 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstanceBEV: Unifying Instance and BEV Representation for Global Modeling
May 20, 2025



Occupancy Grid Maps are widely used in navigation for their ability to represent 3D space occupancy. However, existing methods that utilize multi-view cameras to construct Occupancy Networks for perception modeling suffer from cubic growth in data complexity. Adopting a Bird's-Eye View (BEV) perspective offers a more practical solution for autonomous driving, as it provides higher semantic density and mitigates complex object occlusions. Nonetheless, BEV-based approaches still require extensive engineering optimizations to enable efficient large-scale global modeling. To address this challenge, we propose InstanceBEV, the first method to introduce instance-level dimensionality reduction for BEV, enabling global modeling with transformers without relying on sparsification or acceleration operators. Different from other BEV methods, our approach directly employs transformers to aggregate global features. Compared to 3D object detection models, our method samples global feature maps into 3D space. Experiments on OpenOcc-NuScenes dataset show that InstanceBEV achieves state-of-the-art performance while maintaining a simple, efficient framework without requiring additional optimizations.
Effective Reinforcement Learning Control using Conservative Soft Actor-Critic
May 06, 2025Reinforcement Learning (RL) has shown great potential in complex control tasks, particularly when combined with deep neural networks within the Actor-Critic (AC) framework. However, in practical applications, balancing exploration, learning stability, and sample efficiency remains a significant challenge. Traditional methods such as Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO) address these issues by incorporating entropy or relative entropy regularization, but often face problems of instability and low sample efficiency. In this paper, we propose the Conservative Soft Actor-Critic (CSAC) algorithm, which seamlessly integrates entropy and relative entropy regularization within the AC framework. CSAC improves exploration through entropy regularization while avoiding overly aggressive policy updates with the use of relative entropy regularization. Evaluations on benchmark tasks and real-world robotic simulations demonstrate that CSAC offers significant improvements in stability and efficiency over existing methods. These findings suggest that CSAC provides strong robustness and application potential in control tasks under dynamic environments.
Multi-Goal Dexterous Hand Manipulation using Probabilistic Model-based Reinforcement Learning
Apr 30, 2025This paper tackles the challenge of learning multi-goal dexterous hand manipulation tasks using model-based Reinforcement Learning. We propose Goal-Conditioned Probabilistic Model Predictive Control (GC-PMPC) by designing probabilistic neural network ensembles to describe the high-dimensional dexterous hand dynamics and introducing an asynchronous MPC policy to meet the control frequency requirements in real-world dexterous hand systems. Extensive evaluations on four simulated Shadow Hand manipulation scenarios with randomly generated goals demonstrate GC-PMPC's superior performance over state-of-the-art baselines. It successfully drives a cable-driven Dexterous hand, DexHand 021 with 12 Active DOFs and 5 tactile sensors, to learn manipulating a cubic die to three goal poses within approximately 80 minutes of interactions, demonstrating exceptional learning efficiency and control performance on a cost-effective dexterous hand platform.
Efficient Large-Scale Urban Parking Prediction: Graph Coarsening Based on Real-Time Parking Service Capability
Oct 05, 2024



With the sharp increase in the number of vehicles, the issue of parking difficulties has emerged as an urgent challenge that many cities need to address promptly. In the task of predicting large-scale urban parking data, existing research often lacks effective deep learning models and strategies. To tackle this challenge, this paper proposes an innovative framework for predicting large-scale urban parking graphs leveraging real-time service capabilities, aimed at improving the accuracy and efficiency of parking predictions. Specifically, we introduce a graph attention mechanism that assesses the real-time service capabilities of parking lots to construct a dynamic parking graph that accurately reflects real preferences in parking behavior. To effectively handle large-scale parking data, this study combines graph coarsening techniques with temporal convolutional autoencoders to achieve unified dimension reduction of the complex urban parking graph structure and features. Subsequently, we use a spatio-temporal graph convolutional model to make predictions based on the coarsened graph, and a pre-trained autoencoder-decoder module restores the predicted results to their original data dimensions, completing the task. Our methodology has been rigorously tested on a real dataset from parking lots in Shenzhen. The experimental results indicate that compared to traditional parking prediction models, our framework achieves improvements of 46.8\% and 30.5\% in accuracy and efficiency, respectively. Remarkably, with the expansion of the graph's scale, our framework's advantages become even more apparent, showcasing its substantial potential for solving complex urban parking dilemmas in practical scenarios.
Effective Multi-Agent Deep Reinforcement Learning Control with Relative Entropy Regularization
Sep 26, 2023



In this paper, a novel Multi-agent Reinforcement Learning (MARL) approach, Multi-Agent Continuous Dynamic Policy Gradient (MACDPP) was proposed to tackle the issues of limited capability and sample efficiency in various scenarios controlled by multiple agents. It alleviates the inconsistency of multiple agents' policy updates by introducing the relative entropy regularization to the Centralized Training with Decentralized Execution (CTDE) framework with the Actor-Critic (AC) structure. Evaluated by multi-agent cooperation and competition tasks and traditional control tasks including OpenAI benchmarks and robot arm manipulation, MACDPP demonstrates significant superiority in learning capability and sample efficiency compared with both related multi-agent and widely implemented signal-agent baselines and therefore expands the potential of MARL in effectively learning challenging control scenarios.
Practical Probabilistic Model-based Deep Reinforcement Learning by Integrating Dropout Uncertainty and Trajectory Sampling
Sep 20, 2023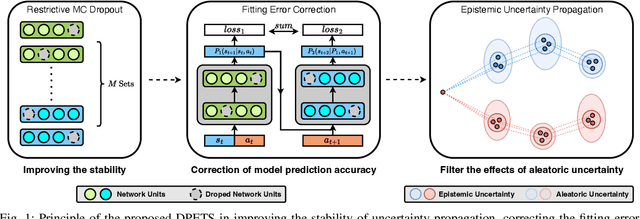
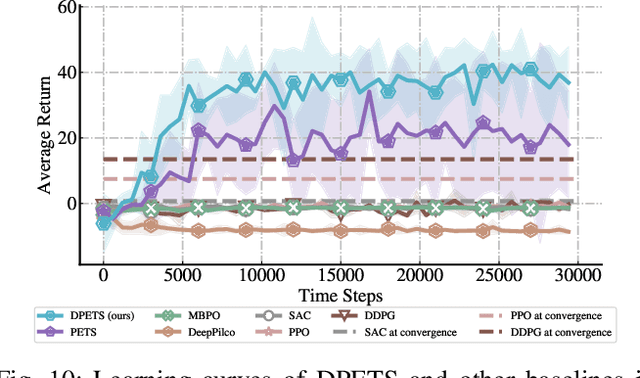
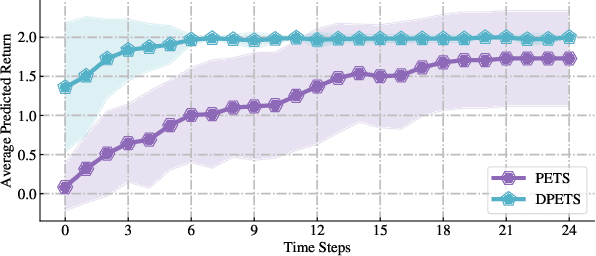
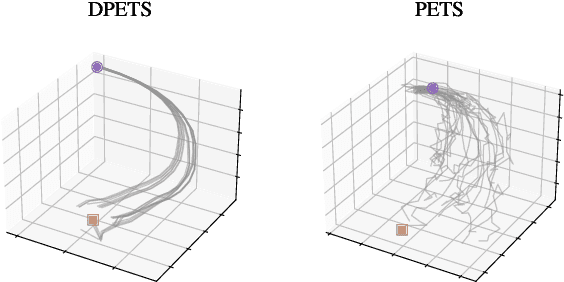
This paper addresses the prediction stability, prediction accuracy and control capability of the current probabilistic model-based reinforcement learning (MBRL) built on neural networks. A novel approach dropout-based probabilistic ensembles with trajectory sampling (DPETS) is proposed where the system uncertainty is stably predicted by combining the Monte-Carlo dropout and trajectory sampling in one framework. Its loss function is designed to correct the fitting error of neural networks for more accurate prediction of probabilistic models. The state propagation in its policy is extended to filter the aleatoric uncertainty for superior control capability. Evaluated by several Mujoco benchmark control tasks under additional disturbances and one practical robot arm manipulation task, DPETS outperforms related MBRL approaches in both average return and convergence velocity while achieving superior performance than well-known model-free baselines with significant sample efficiency. The open source code of DPETS is available at https://github.com/mrjun123/DPETS.
Uncertainty-aware Contact-safe Model-based Reinforcement Learning
Oct 16, 2020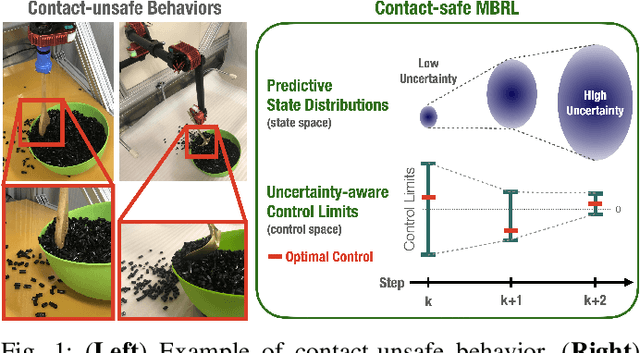
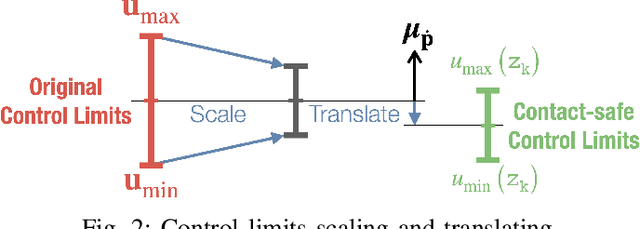
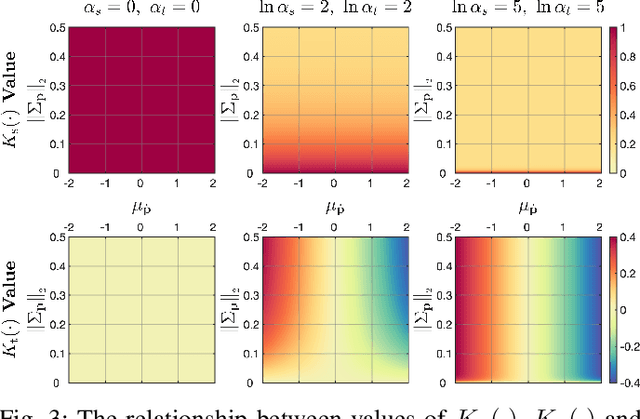
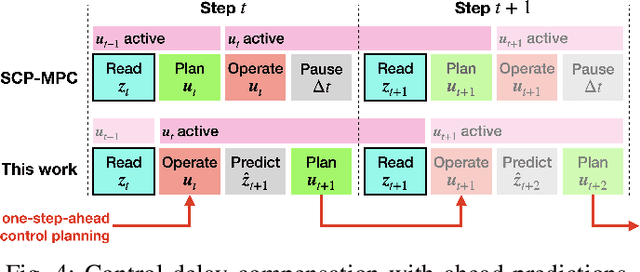
This paper presents contact-safe Model-based Reinforcement Learning (MBRL) for robot applications that achieves contact-safe behaviors in the learning process. In typical MBRL, we cannot expect the data-driven model to generate accurate and reliable policies to the intended robotic tasks during the learning process due to data scarcity. Operating these unreliable policies in a contact-rich environment could cause damage to the robot and its surroundings. To alleviate the risk of causing damage through unexpected intensive physical contacts, we present the contact-safe MBRL that associates the probabilistic Model Predictive Control's (pMPC) control limits with the model uncertainty so that the allowed acceleration of controlled behavior is adjusted according to learning progress. Control planning with such uncertainty-aware control limits is formulated as a deterministic MPC problem using a computationally-efficient approximated GP dynamics and an approximated inference technique. Our approach's effectiveness is evaluated through bowl mixing tasks with simulated and real robots, scooping tasks with a real robot as examples of contact-rich manipulation skills. (video: https://youtu.be/8uTDYYUKeFM)