 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan the Environment Speak for Itself? $T^{2}$-GRPO: A Turn-Trajectory Group Relative Policy Optimization for Caregiver Agents
Jun 07, 2026Optimizing large language models (LLMs) for long-horizon caregiver agents requires balancing delayed task objectives with immediate environment dynamics, such as patient distress and resistance. In dementia care, this balance is especially difficult: trajectory level rewards are too sparse for turn level credit assignment, while external LLM-based evaluators are costly and can misread fragmented or indirect patient responses. To address this issue, we propose \textbf{T}urn-\textbf{T}rajectory \textbf{G}roup \textbf{R}elative \textbf{P}olicy \textbf{O}ptimization (\textbf{T$^{2}$-GRPO}), a framework that decouples caregiver RL into two normalized reward horizons and enforces safety through a binary hard veto. $T^2$-GRPO derives dense turn-level rewards directly from environment state transitions, measuring changes in patient distress and resistance from a frozen dementia patient simulator. These environment-grounded rewards are combined with trajectory-level evaluations through independent centered-rank normalization, which preserves heterogeneous reward signals and mitigates reward collapse. Extensive experiments on dementia caregivers show that T $^{2}$-GRPO outperforms competitive baselines, indicating a substantial improvement for emotionally sensitive caregiver scenarios that effectively handles immediate patient feedback, long-term care outcomes, and safety constraints.
MERIT: Multi-domain Efficient RAW Image Translation
Mar 21, 2026RAW images captured by different camera sensors exhibit substantial domain shifts due to varying spectral responses, noise characteristics, and tone behaviors, complicating their direct use in downstream computer vision tasks. Prior methods address this problem by training domain-specific RAW-to-RAW translators for each source-target pair, but such approaches do not scale to real-world scenarios involving multiple types of commercial cameras. In this work, we introduce MERIT, the first unified framework for multi-domain RAW image translation, which leverages a single model to perform translations across arbitrary camera domains. To address domain-specific noise discrepancies, we propose a sensor-aware noise modeling loss that explicitly aligns the signal-dependent noise statistics of the generated images with those of the target domain. We further enhance the generator with a conditional multi-scale large kernel attention module for improved context and sensor-aware feature modeling. To facilitate standardized evaluation, we introduce MDRAW, the first dataset tailored for multi-domain RAW image translation, comprising both paired and unpaired RAW captures from five diverse camera sensors across a wide range of scenes. Extensive experiments demonstrate that MERIT outperforms prior models in both quality (5.56 dB improvement) and scalability (80% reduction in training iterations).
$n$-Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models
Feb 09, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) shows that small, specialized language models (SLMs) can exhibit structured reasoning without relying on large monolithic LLMs. We introduce soft hidden-state collaboration, where multiple heterogeneous frozen SLM experts are integrated through their internal representations via a trainable attention interface. Experiments on Reasoning Gym and GSM8K show that this latent integration is competitive with strong single-model RLVR baselines. Ablations further reveal a dual mechanism of expert utilization: for simpler arithmetic domains, performance gains can largely be explained by static expert preferences, whereas more challenging settings induce increasingly concentrated and structured expert attention over training, indicating emergent specialization in how the router connects to relevant experts. Overall, hidden-state collaboration provides a compact mechanism for leveraging frozen experts, while offering an observational window into expert utilization patterns and their evolution under RLVR.
Fair Context Learning for Evidence-Balanced Test-Time Adaptation in Vision-Language Models
Feb 02, 2026Vision-Language Models (VLMs) such as CLIP enable strong zero-shot recognition but suffer substantial degradation under distribution shifts. Test-Time Adaptation (TTA) aims to improve robustness using only unlabeled test samples, yet most prompt-based TTA methods rely on entropy minimization -- an approach that can amplify spurious correlations and induce overconfident errors when classes share visual features. We propose Fair Context Learning (FCL), an episodic TTA framework that avoids entropy minimization by explicitly addressing shared-evidence bias. Motivated by our additive evidence decomposition assumption, FCL decouples adaptation into (i) augmentation-based exploration to identify plausible class candidates, and (ii) fairness-driven calibration that adapts text contexts to equalize sensitivity to common visual evidence. This fairness constraint mitigates partial feature obsession and enables effective calibration of text embeddings without relying on entropy reduction. Through extensive evaluation, we empirically validate our theoretical motivation and show that FCL achieves competitive adaptation performance relative to state-of-the-art TTA methods across diverse domain-shift and fine-grained benchmarks.
Cauchy-Schwarz Fairness Regularizer
Dec 10, 2025



Group fairness in machine learning is often enforced by adding a regularizer that reduces the dependence between model predictions and sensitive attributes. However, existing regularizers are built on heterogeneous distance measures and design choices, which makes their behavior hard to reason about and their performance inconsistent across tasks. This raises a basic question: what properties make a good fairness regularizer? We address this question by first organizing existing in-process methods into three families: (i) matching prediction statistics across sensitive groups, (ii) aligning latent representations, and (iii) directly minimizing dependence between predictions and sensitive attributes. Through this lens, we identify desirable properties of the underlying distance measure, including tight generalization bounds, robustness to scale differences, and the ability to handle arbitrary prediction distributions. Motivated by these properties, we propose a Cauchy-Schwarz (CS) fairness regularizer that penalizes the empirical CS divergence between prediction distributions conditioned on sensitive groups. Under a Gaussian comparison, we show that CS divergence yields a tighter bound than Kullback-Leibler divergence, Maximum Mean Discrepancy, and the mean disparity used in Demographic Parity, and we discuss how these advantages translate to a distribution-free, kernel-based estimator that naturally extends to multiple sensitive attributes. Extensive experiments on four tabular benchmarks and one image dataset demonstrate that the proposed CS regularizer consistently improves Demographic Parity and Equal Opportunity metrics while maintaining competitive accuracy, and achieves a more stable utility-fairness trade-off across hyperparameter settings compared to prior regularizers.
LUNE: Efficient LLM Unlearning via LoRA Fine-Tuning with Negative Examples
Dec 08, 2025Large language models (LLMs) possess vast knowledge acquired from extensive training corpora, but they often cannot remove specific pieces of information when needed, which makes it hard to handle privacy, bias mitigation, and knowledge correction. Traditional model unlearning approaches require computationally expensive fine-tuning or direct weight editing, making them impractical for real-world deployment. In this work, we introduce LoRA-based Unlearning with Negative Examples (LUNE), a lightweight framework that performs negative-only unlearning by updating only low-rank adapters while freezing the backbone, thereby localizing edits and avoiding disruptive global changes. Leveraging Low-Rank Adaptation (LoRA), LUNE targets intermediate representations to suppress (or replace) requested knowledge with an order-of-magnitude lower compute and memory than full fine-tuning or direct weight editing. Extensive experiments on multiple factual unlearning tasks show that LUNE: (I) achieves effectiveness comparable to full fine-tuning and memory-editing methods, and (II) reduces computational cost by about an order of magnitude.
Recover-to-Forget: Gradient Reconstruction from LoRA for Efficient LLM Unlearning
Dec 08, 2025



Unlearning in large foundation models (e.g., LLMs) is essential for enabling dynamic knowledge updates, enforcing data deletion rights, and correcting model behavior. However, existing unlearning methods often require full-model fine-tuning or access to the original training data, which limits their scalability and practicality. In this work, we introduce Recover-to-Forget (R2F), a novel framework for efficient unlearning in LLMs based on reconstructing full-model gradient directions from low-rank LoRA adapter updates. Rather than performing backpropagation through the full model, we compute gradients with respect to LoRA parameters using multiple paraphrased prompts and train a gradient decoder to approximate the corresponding full-model gradients. To ensure applicability to larger or black-box models, the decoder is trained on a proxy model and transferred to target models. We provide a theoretical analysis of cross-model generalization and demonstrate that our method achieves effective unlearning while preserving general model performance. Experimental results demonstrate that R2F offers a scalable and lightweight alternative for unlearning in pretrained LLMs without requiring full retraining or access to internal parameters.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025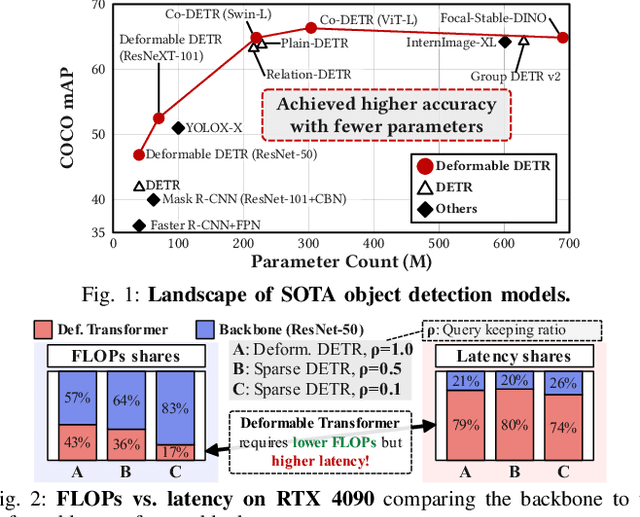
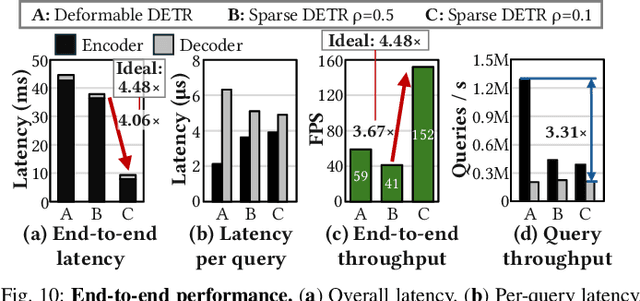
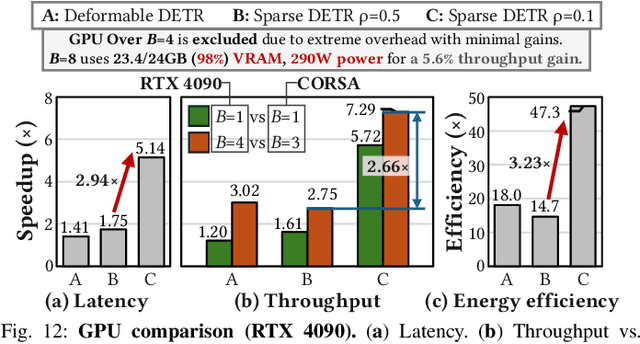
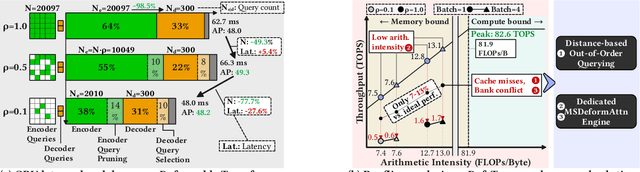
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
Draft and Refine with Visual Experts
Nov 14, 2025While recent Large Vision-Language Models (LVLMs) exhibit strong multimodal reasoning abilities, they often produce ungrounded or hallucinated responses because they rely too heavily on linguistic priors instead of visual evidence. This limitation highlights the absence of a quantitative measure of how much these models actually use visual information during reasoning. We propose Draft and Refine (DnR), an agent framework driven by a question-conditioned utilization metric. The metric quantifies the model's reliance on visual evidence by first constructing a query-conditioned relevance map to localize question-specific cues and then measuring dependence through relevance-guided probabilistic masking. Guided by this metric, the DnR agent refines its initial draft using targeted feedback from external visual experts. Each expert's output (such as boxes or masks) is rendered as visual cues on the image, and the model is re-queried to select the response that yields the largest improvement in utilization. This process strengthens visual grounding without retraining or architectural changes. Experiments across VQA and captioning benchmarks show consistent accuracy gains and reduced hallucination, demonstrating that measuring visual utilization provides a principled path toward more interpretable and evidence-driven multimodal agent systems.
Enabling Group Fairness in Graph Unlearning via Bi-level Debiasing
May 14, 2025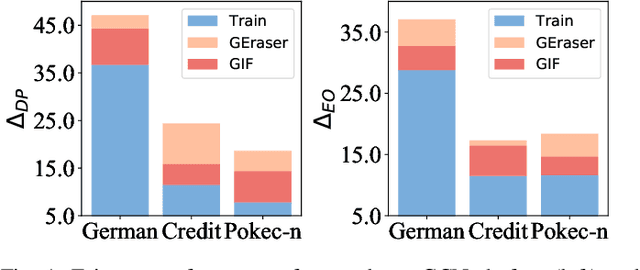
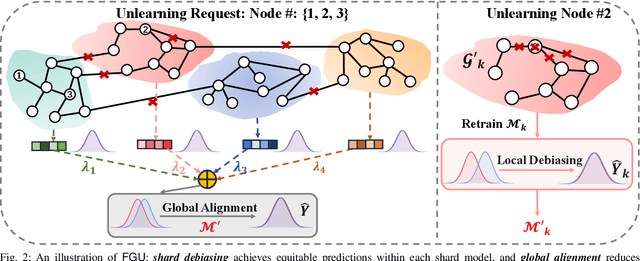
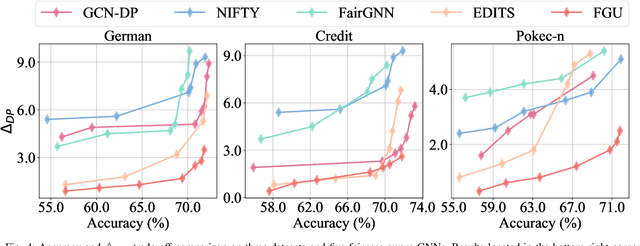
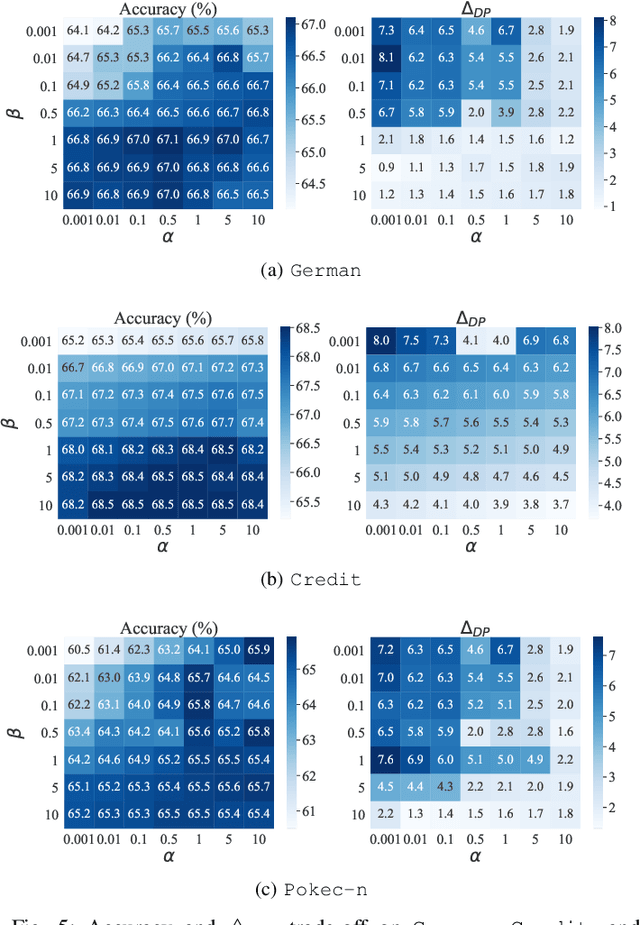
Graph unlearning is a crucial approach for protecting user privacy by erasing the influence of user data on trained graph models. Recent developments in graph unlearning methods have primarily focused on maintaining model prediction performance while removing user information. However, we have observed that when user information is deleted from the model, the prediction distribution across different sensitive groups often changes. Furthermore, graph models are shown to be prone to amplifying biases, making the study of fairness in graph unlearning particularly important. This raises the question: Does graph unlearning actually introduce bias? Our findings indicate that the predictions of post-unlearning models become highly correlated with sensitive attributes, confirming the introduction of bias in the graph unlearning process. To address this issue, we propose a fair graph unlearning method, FGU. To guarantee privacy, FGU trains shard models on partitioned subgraphs, unlearns the requested data from the corresponding subgraphs, and retrains the shard models on the modified subgraphs. To ensure fairness, FGU employs a bi-level debiasing process: it first enables shard-level fairness by incorporating a fairness regularizer in the shard model retraining, and then achieves global-level fairness by aligning all shard models to minimize global disparity. Our experiments demonstrate that FGU achieves superior fairness while maintaining privacy and accuracy. Additionally, FGU is robust to diverse unlearning requests, ensuring fairness and utility performance across various data distributions.