 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Hypervectors Enough? Single-Call LLM Reasoning over Knowledge Graphs
Dec 10, 2025Recent advances in large language models (LLMs) have enabled strong reasoning over both structured and unstructured knowledge. When grounded on knowledge graphs (KGs), however, prevailing pipelines rely on heavy neural encoders to embed and score symbolic paths or on repeated LLM calls to rank candidates, leading to high latency, GPU cost, and opaque decisions that hinder faithful, scalable deployment. We propose PathHD, a lightweight and encoder-free KG reasoning framework that replaces neural path scoring with hyperdimensional computing (HDC) and uses only a single LLM call per query. PathHD encodes relation paths into block-diagonal GHRR hypervectors, ranks candidates with blockwise cosine similarity and Top-K pruning, and then performs a one-shot LLM adjudication to produce the final answer together with cited supporting paths. Technically, PathHD is built on three ingredients: (i) an order-aware, non-commutative binding operator for path composition, (ii) a calibrated similarity for robust hypervector-based retrieval, and (iii) a one-shot adjudication step that preserves interpretability while eliminating per-path LLM scoring. On WebQSP, CWQ, and the GrailQA split, PathHD (i) attains comparable or better Hits@1 than strong neural baselines while using one LLM call per query; (ii) reduces end-to-end latency by $40-60\%$ and GPU memory by $3-5\times$ thanks to encoder-free retrieval; and (iii) delivers faithful, path-grounded rationales that improve error diagnosis and controllability. These results indicate that carefully designed HDC representations provide a practical substrate for efficient KG-LLM reasoning, offering a favorable accuracy-efficiency-interpretability trade-off.
Cauchy-Schwarz Fairness Regularizer
Dec 10, 2025



Group fairness in machine learning is often enforced by adding a regularizer that reduces the dependence between model predictions and sensitive attributes. However, existing regularizers are built on heterogeneous distance measures and design choices, which makes their behavior hard to reason about and their performance inconsistent across tasks. This raises a basic question: what properties make a good fairness regularizer? We address this question by first organizing existing in-process methods into three families: (i) matching prediction statistics across sensitive groups, (ii) aligning latent representations, and (iii) directly minimizing dependence between predictions and sensitive attributes. Through this lens, we identify desirable properties of the underlying distance measure, including tight generalization bounds, robustness to scale differences, and the ability to handle arbitrary prediction distributions. Motivated by these properties, we propose a Cauchy-Schwarz (CS) fairness regularizer that penalizes the empirical CS divergence between prediction distributions conditioned on sensitive groups. Under a Gaussian comparison, we show that CS divergence yields a tighter bound than Kullback-Leibler divergence, Maximum Mean Discrepancy, and the mean disparity used in Demographic Parity, and we discuss how these advantages translate to a distribution-free, kernel-based estimator that naturally extends to multiple sensitive attributes. Extensive experiments on four tabular benchmarks and one image dataset demonstrate that the proposed CS regularizer consistently improves Demographic Parity and Equal Opportunity metrics while maintaining competitive accuracy, and achieves a more stable utility-fairness trade-off across hyperparameter settings compared to prior regularizers.
Mitigating Bias in Graph Hyperdimensional Computing
Dec 08, 2025Graph hyperdimensional computing (HDC) has emerged as a promising paradigm for cognitive tasks, emulating brain-like computation with high-dimensional vectors known as hypervectors. While HDC offers robustness and efficiency on graph-structured data, its fairness implications remain largely unexplored. In this paper, we study fairness in graph HDC, where biases in data representation and decision rules can lead to unequal treatment of different groups. We show how hypervector encoding and similarity-based classification can propagate or even amplify such biases, and we propose a fairness-aware training framework, FairGHDC, to mitigate them. FairGHDC introduces a bias correction term, derived from a gap-based demographic-parity regularizer, and converts it into a scalar fairness factor that scales the update of the class hypervector for the ground-truth label. This enables debiasing directly in the hypervector space without modifying the graph encoder or requiring backpropagation. Experimental results on six benchmark datasets demonstrate that FairGHDC substantially reduces demographic-parity and equal-opportunity gaps while maintaining accuracy comparable to standard GNNs and fairness-aware GNNs. At the same time, FairGHDC preserves the computational advantages of HDC, achieving up to about one order of magnitude ($\approx 10\times$) speedup in training time on GPU compared to GNN and fairness-aware GNN baselines.
LUNE: Efficient LLM Unlearning via LoRA Fine-Tuning with Negative Examples
Dec 08, 2025Large language models (LLMs) possess vast knowledge acquired from extensive training corpora, but they often cannot remove specific pieces of information when needed, which makes it hard to handle privacy, bias mitigation, and knowledge correction. Traditional model unlearning approaches require computationally expensive fine-tuning or direct weight editing, making them impractical for real-world deployment. In this work, we introduce LoRA-based Unlearning with Negative Examples (LUNE), a lightweight framework that performs negative-only unlearning by updating only low-rank adapters while freezing the backbone, thereby localizing edits and avoiding disruptive global changes. Leveraging Low-Rank Adaptation (LoRA), LUNE targets intermediate representations to suppress (or replace) requested knowledge with an order-of-magnitude lower compute and memory than full fine-tuning or direct weight editing. Extensive experiments on multiple factual unlearning tasks show that LUNE: (I) achieves effectiveness comparable to full fine-tuning and memory-editing methods, and (II) reduces computational cost by about an order of magnitude.
Recover-to-Forget: Gradient Reconstruction from LoRA for Efficient LLM Unlearning
Dec 08, 2025



Unlearning in large foundation models (e.g., LLMs) is essential for enabling dynamic knowledge updates, enforcing data deletion rights, and correcting model behavior. However, existing unlearning methods often require full-model fine-tuning or access to the original training data, which limits their scalability and practicality. In this work, we introduce Recover-to-Forget (R2F), a novel framework for efficient unlearning in LLMs based on reconstructing full-model gradient directions from low-rank LoRA adapter updates. Rather than performing backpropagation through the full model, we compute gradients with respect to LoRA parameters using multiple paraphrased prompts and train a gradient decoder to approximate the corresponding full-model gradients. To ensure applicability to larger or black-box models, the decoder is trained on a proxy model and transferred to target models. We provide a theoretical analysis of cross-model generalization and demonstrate that our method achieves effective unlearning while preserving general model performance. Experimental results demonstrate that R2F offers a scalable and lightweight alternative for unlearning in pretrained LLMs without requiring full retraining or access to internal parameters.
Enabling Group Fairness in Graph Unlearning via Bi-level Debiasing
May 14, 2025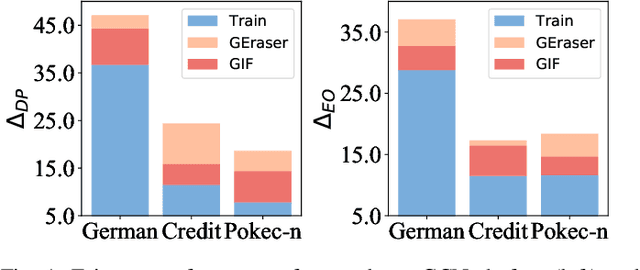
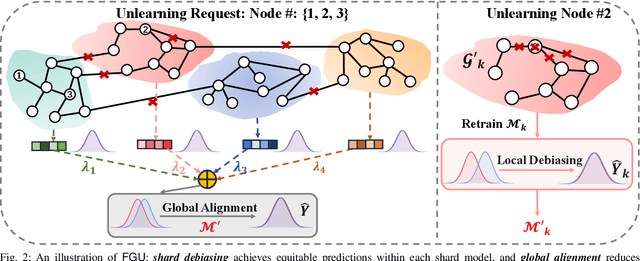
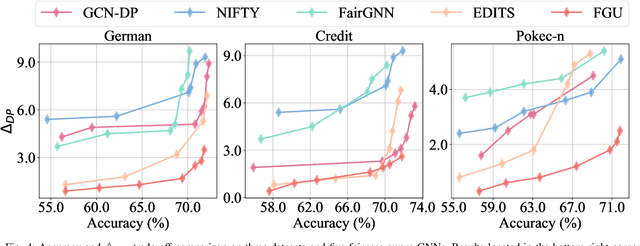
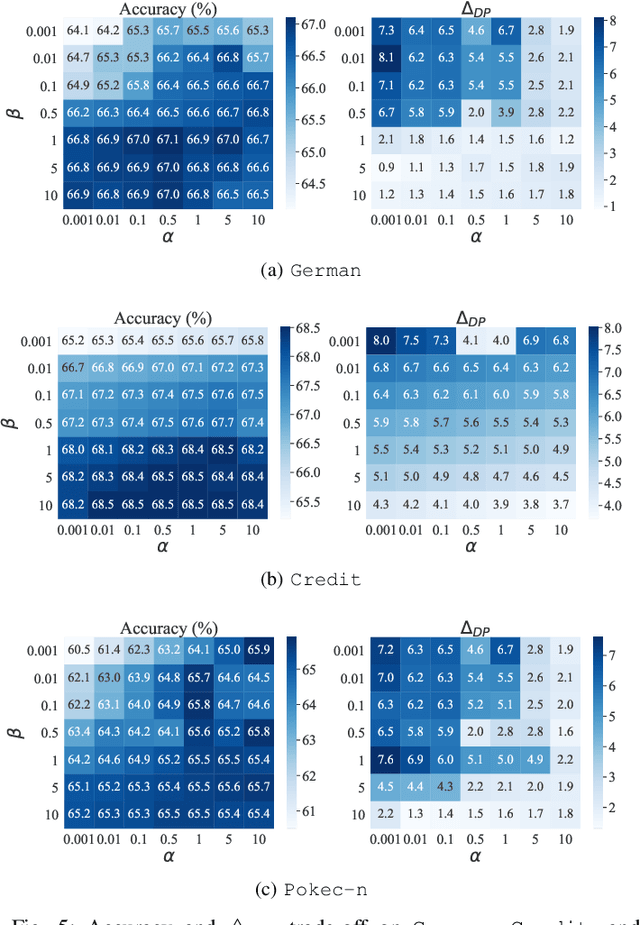
Graph unlearning is a crucial approach for protecting user privacy by erasing the influence of user data on trained graph models. Recent developments in graph unlearning methods have primarily focused on maintaining model prediction performance while removing user information. However, we have observed that when user information is deleted from the model, the prediction distribution across different sensitive groups often changes. Furthermore, graph models are shown to be prone to amplifying biases, making the study of fairness in graph unlearning particularly important. This raises the question: Does graph unlearning actually introduce bias? Our findings indicate that the predictions of post-unlearning models become highly correlated with sensitive attributes, confirming the introduction of bias in the graph unlearning process. To address this issue, we propose a fair graph unlearning method, FGU. To guarantee privacy, FGU trains shard models on partitioned subgraphs, unlearns the requested data from the corresponding subgraphs, and retrains the shard models on the modified subgraphs. To ensure fairness, FGU employs a bi-level debiasing process: it first enables shard-level fairness by incorporating a fairness regularizer in the shard model retraining, and then achieves global-level fairness by aligning all shard models to minimize global disparity. Our experiments demonstrate that FGU achieves superior fairness while maintaining privacy and accuracy. Additionally, FGU is robust to diverse unlearning requests, ensuring fairness and utility performance across various data distributions.
LVLM_CSP: Accelerating Large Vision Language Models via Clustering, Scattering, and Pruning for Reasoning Segmentation
Apr 15, 2025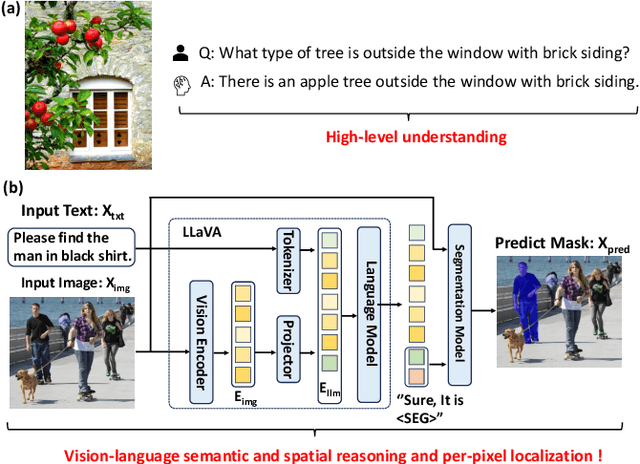
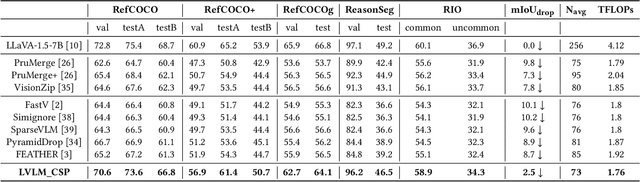
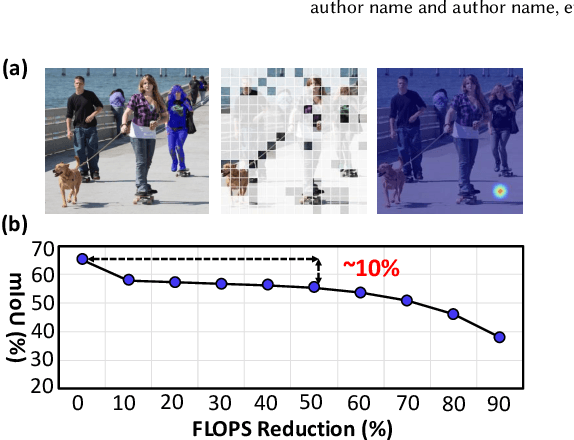
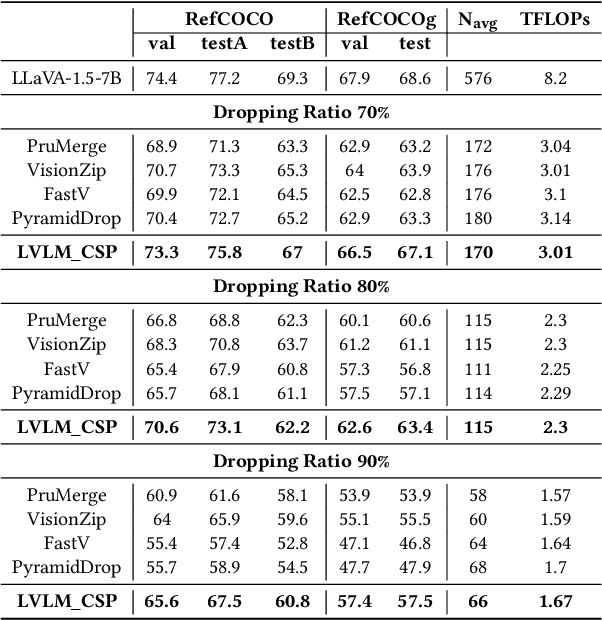
Large Vision Language Models (LVLMs) have been widely adopted to guide vision foundation models in performing reasoning segmentation tasks, achieving impressive performance. However, the substantial computational overhead associated with LVLMs presents a new challenge. The primary source of this computational cost arises from processing hundreds of image tokens. Therefore, an effective strategy to mitigate such overhead is to reduce the number of image tokens, a process known as image token pruning. Previous studies on image token pruning for LVLMs have primarily focused on high level visual understanding tasks, such as visual question answering and image captioning. In contrast, guiding vision foundation models to generate accurate visual masks based on textual queries demands precise semantic and spatial reasoning capabilities. Consequently, pruning methods must carefully control individual image tokens throughout the LVLM reasoning process. Our empirical analysis reveals that existing methods struggle to adequately balance reductions in computational overhead with the necessity to maintain high segmentation accuracy. In this work, we propose LVLM_CSP, a novel training free visual token pruning method specifically designed for LVLM based reasoning segmentation tasks. LVLM_CSP consists of three stages: clustering, scattering, and pruning. Initially, the LVLM performs coarse-grained visual reasoning using a subset of selected image tokens. Next, fine grained reasoning is conducted, and finally, most visual tokens are pruned in the last stage. Extensive experiments demonstrate that LVLM_CSP achieves a 65% reduction in image token inference FLOPs with virtually no accuracy degradation, and a 70% reduction with only a minor 1% drop in accuracy on the 7B LVLM.
Tell Me What to Track: Infusing Robust Language Guidance for Enhanced Referring Multi-Object Tracking
Dec 17, 2024Referring multi-object tracking (RMOT) is an emerging cross-modal task that aims to localize an arbitrary number of targets based on a language expression and continuously track them in a video. This intricate task involves reasoning on multi-modal data and precise target localization with temporal association. However, prior studies overlook the imbalanced data distribution between newborn targets and existing targets due to the nature of the task. In addition, they only indirectly fuse multi-modal features, struggling to deliver clear guidance on newborn target detection. To solve the above issues, we conduct a collaborative matching strategy to alleviate the impact of the imbalance, boosting the ability to detect newborn targets while maintaining tracking performance. In the encoder, we integrate and enhance the cross-modal and multi-scale fusion, overcoming the bottlenecks in previous work, where limited multi-modal information is shared and interacted between feature maps. In the decoder, we also develop a referring-infused adaptation that provides explicit referring guidance through the query tokens. The experiments showcase the superior performance of our model (+3.42%) compared to prior works, demonstrating the effectiveness of our designs.
Gradient Inversion Attack on Graph Neural Networks
Nov 29, 2024



Graph federated learning is of essential importance for training over large graph datasets while protecting data privacy, where each client stores a subset of local graph data, while the server collects the local gradients and broadcasts only the aggregated gradients. Recent studies reveal that a malicious attacker can steal private image data from gradient exchanging of neural networks during federated learning. However, none of the existing works have studied the vulnerability of graph data and graph neural networks under such attack. To answer this question, the present paper studies the problem of whether private data can be recovered from leaked gradients in both node classification and graph classification tasks and { proposes a novel attack named Graph Leakage from Gradients (GLG)}. Two widely-used GNN frameworks are analyzed, namely GCN and GraphSAGE. The effects of different model settings on recovery are extensively discussed. Through theoretical analysis and empirical validation, it is shown that parts of the graph data can be leaked from the gradients.
Promoting Fairness in Link Prediction with Graph Enhancement
Sep 13, 2024Link prediction is a crucial task in network analysis, but it has been shown to be prone to biased predictions, particularly when links are unfairly predicted between nodes from different sensitive groups. In this paper, we study the fair link prediction problem, which aims to ensure that the predicted link probability is independent of the sensitive attributes of the connected nodes. Existing methods typically incorporate debiasing techniques within graph embeddings to mitigate this issue. However, training on large real-world graphs is already challenging, and adding fairness constraints can further complicate the process. To overcome this challenge, we propose FairLink, a method that learns a fairness-enhanced graph to bypass the need for debiasing during the link predictor's training. FairLink maintains link prediction accuracy by ensuring that the enhanced graph follows a training trajectory similar to that of the original input graph. Meanwhile, it enhances fairness by minimizing the absolute difference in link probabilities between node pairs within the same sensitive group and those between node pairs from different sensitive groups. Our extensive experiments on multiple large-scale graphs demonstrate that FairLink not only promotes fairness but also often achieves link prediction accuracy comparable to baseline methods. Most importantly, the enhanced graph exhibits strong generalizability across different GNN architectures.