 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorR: Towards Brain-Inspired Task-Oriented Reasoning via Cache-Oriented Algorithm-Architecture Co-design
Mar 24, 2026Task-oriented object detection (TOOD) atop CLIP offers open-vocabulary, prompt-driven semantics, yet dense per-window computation and heavy memory traffic hinder real-time, power-limited edge deployment. We present \emph{TorR}, a brain-inspired \textbf{algorithm--architecture co-design} that \textbf{replaces CLIP-style dense alignment with a hyperdimensional (HDC) associative reasoner} and turns temporal coherence into reuse. On the \emph{algorithm} side, TorR reformulates alignment as HDC similarity and graph composition, introducing \emph{partial-similarity reuse} via (i) query caching with per-class score accumulation, (ii) exact $δ$-updates when only a small set of hypervector bits change, and (iii) similarity/load-gated bypass under high system load. On the \emph{architecture} side, TorR instantiates a lane-scalable, bit-sliced item memory with bank/precision gating and a lightweight controller that schedules bypass/$δ$/full paths to meet RT-30/RT-60 targets as object counts vary. Synthesized in a TSMC 28\,nm process and exercised with a cycle-accurate simulator, TorR sustains real-time throughput with millijoule-scale energy per window ($\approx$50\,mJ at 60\,FPS; $\approx$113\,mJ at 30\,FPS) and low latency jitter, while delivering competitive AP@0.5 across five task prompts (mean 44.27\%) within a bounded margin to strong VLM baselines, but at orders-of-magnitude lower energy. The design exposes deployment-time configurability (effective dimension $D'$, thresholds, precision) to trade accuracy, latency, and energy for edge budgets.
MERIT: Multi-domain Efficient RAW Image Translation
Mar 21, 2026RAW images captured by different camera sensors exhibit substantial domain shifts due to varying spectral responses, noise characteristics, and tone behaviors, complicating their direct use in downstream computer vision tasks. Prior methods address this problem by training domain-specific RAW-to-RAW translators for each source-target pair, but such approaches do not scale to real-world scenarios involving multiple types of commercial cameras. In this work, we introduce MERIT, the first unified framework for multi-domain RAW image translation, which leverages a single model to perform translations across arbitrary camera domains. To address domain-specific noise discrepancies, we propose a sensor-aware noise modeling loss that explicitly aligns the signal-dependent noise statistics of the generated images with those of the target domain. We further enhance the generator with a conditional multi-scale large kernel attention module for improved context and sensor-aware feature modeling. To facilitate standardized evaluation, we introduce MDRAW, the first dataset tailored for multi-domain RAW image translation, comprising both paired and unpaired RAW captures from five diverse camera sensors across a wide range of scenes. Extensive experiments demonstrate that MERIT outperforms prior models in both quality (5.56 dB improvement) and scalability (80% reduction in training iterations).
Fair Context Learning for Evidence-Balanced Test-Time Adaptation in Vision-Language Models
Feb 02, 2026Vision-Language Models (VLMs) such as CLIP enable strong zero-shot recognition but suffer substantial degradation under distribution shifts. Test-Time Adaptation (TTA) aims to improve robustness using only unlabeled test samples, yet most prompt-based TTA methods rely on entropy minimization -- an approach that can amplify spurious correlations and induce overconfident errors when classes share visual features. We propose Fair Context Learning (FCL), an episodic TTA framework that avoids entropy minimization by explicitly addressing shared-evidence bias. Motivated by our additive evidence decomposition assumption, FCL decouples adaptation into (i) augmentation-based exploration to identify plausible class candidates, and (ii) fairness-driven calibration that adapts text contexts to equalize sensitivity to common visual evidence. This fairness constraint mitigates partial feature obsession and enables effective calibration of text embeddings without relying on entropy reduction. Through extensive evaluation, we empirically validate our theoretical motivation and show that FCL achieves competitive adaptation performance relative to state-of-the-art TTA methods across diverse domain-shift and fine-grained benchmarks.
Exploiting Boosting in Hyperdimensional Computing for Enhanced Reliability in Healthcare
Nov 21, 2024Hyperdimensional computing (HDC) enables efficient data encoding and processing in high-dimensional space, benefiting machine learning and data analysis. However, underutilization of these spaces can lead to overfitting and reduced model reliability, especially in data-limited systems a critical issue in sectors like healthcare that demand robustness and consistent performance. We introduce BoostHD, an approach that applies boosting algorithms to partition the hyperdimensional space into subspaces, creating an ensemble of weak learners. By integrating boosting with HDC, BoostHD enhances performance and reliability beyond existing HDC methods. Our analysis highlights the importance of efficient utilization of hyperdimensional spaces for improved model performance. Experiments on healthcare datasets show that BoostHD outperforms state-of-the-art methods. On the WESAD dataset, it achieved an accuracy of 98.37%, surpassing Random Forest, XGBoost, and OnlineHD. BoostHD also demonstrated superior inference efficiency and stability, maintaining high accuracy under data imbalance and noise. In person-specific evaluations, it achieved an average accuracy of 96.19%, outperforming other models. By addressing the limitations of both boosting and HDC, BoostHD expands the applicability of HDC in critical domains where reliability and precision are paramount.
VLTP: Vision-Language Guided Token Pruning for Task-Oriented Segmentation
Sep 13, 2024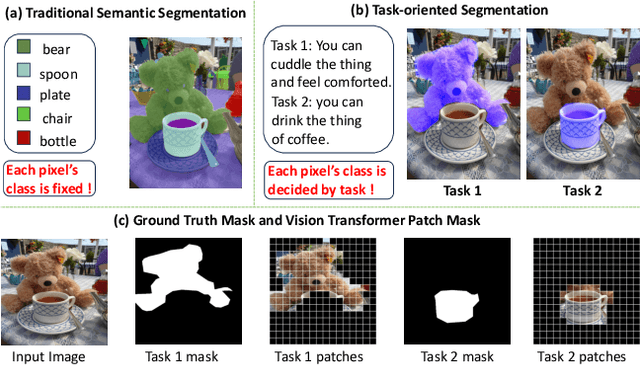
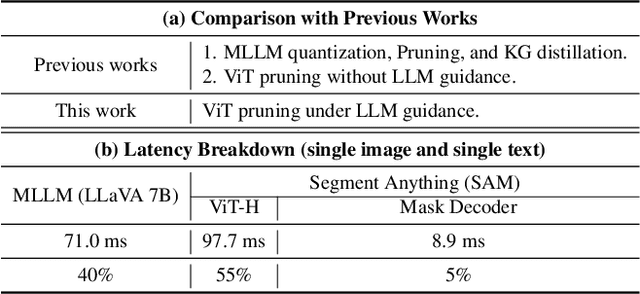
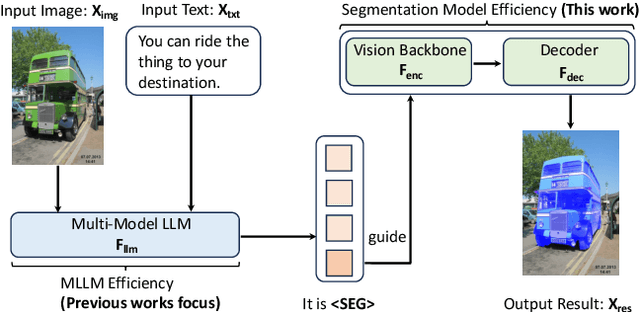
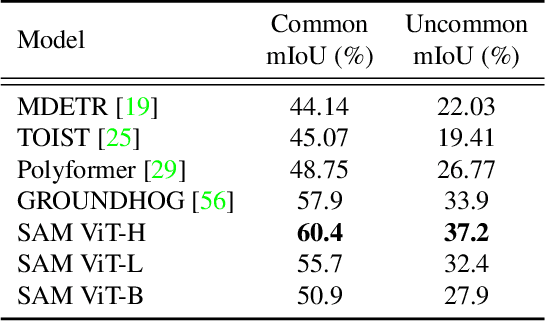
Vision Transformers (ViTs) have emerged as the backbone of many segmentation models, consistently achieving state-of-the-art (SOTA) performance. However, their success comes at a significant computational cost. Image token pruning is one of the most effective strategies to address this complexity. However, previous approaches fall short when applied to more complex task-oriented segmentation (TOS), where the class of each image patch is not predefined but dependent on the specific input task. This work introduces the Vision Language Guided Token Pruning (VLTP), a novel token pruning mechanism that can accelerate ViTbased segmentation models, particularly for TOS guided by multi-modal large language model (MLLM). We argue that ViT does not need to process every image token through all of its layers only the tokens related to reasoning tasks are necessary. We design a new pruning decoder to take both image tokens and vision-language guidance as input to predict the relevance of each image token to the task. Only image tokens with high relevance are passed to deeper layers of the ViT. Experiments show that the VLTP framework reduces the computational costs of ViT by approximately 25% without performance degradation and by around 40% with only a 1% performance drop.
Recoverable Anonymization for Pose Estimation: A Privacy-Enhancing Approach
Sep 01, 2024Human pose estimation (HPE) is crucial for various applications. However, deploying HPE algorithms in surveillance contexts raises significant privacy concerns due to the potential leakage of sensitive personal information (SPI) such as facial features, and ethnicity. Existing privacy-enhancing methods often compromise either privacy or performance, or they require costly additional modalities. We propose a novel privacy-enhancing system that generates privacy-enhanced portraits while maintaining high HPE performance. Our key innovations include the reversible recovery of SPI for authorized personnel and the preservation of contextual information. By jointly optimizing a privacy-enhancing module, a privacy recovery module, and a pose estimator, our system ensures robust privacy protection, efficient SPI recovery, and high-performance HPE. Experimental results demonstrate the system's robust performance in privacy enhancement, SPI recovery, and HPE.
Spatial-Aware Image Retrieval: A Hyperdimensional Computing Approach for Efficient Similarity Hashing
Apr 17, 2024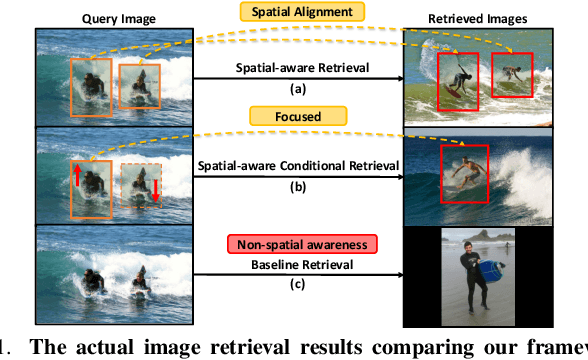


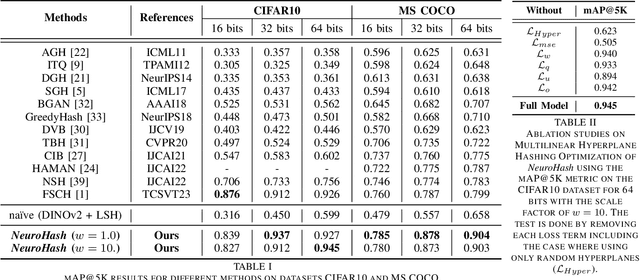
In the face of burgeoning image data, efficiently retrieving similar images poses a formidable challenge. Past research has focused on refining hash functions to distill images into compact indicators of resemblance. Initial attempts used shallow models, evolving to attention mechanism-based architectures from Convolutional Neural Networks (CNNs) to advanced models. Recognizing limitations in gradient-based models for spatial information embedding, we propose an innovative image hashing method, NeuroHash leveraging Hyperdimensional Computing (HDC). HDC symbolically encodes spatial information into high-dimensional vectors, reshaping image representation. Our approach combines pre-trained large vision models with HDC operations, enabling spatially encoded feature representations. Hashing with locality-sensitive hashing (LSH) ensures swift and efficient image retrieval. Notably, our framework allows dynamic hash manipulation for conditional image retrieval. Our work introduces a transformative image hashing framework enabling spatial-aware conditional retrieval. By seamlessly combining DNN-based neural and HDC-based symbolic models, our methodology breaks from traditional training, offering flexible and conditional image retrieval. Performance evaluations signify a paradigm shift in image-hashing methodologies, demonstrating enhanced retrieval accuracy.