 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Centric Decision Process
May 12, 2026Language environments such as web browsers, code terminals, and interactive simulations emit raw text rather than states, and provide none of the runtime structure that MDP analysis requires. No explicit state space, no observation-to-state mapping, no certified transitions, and no termination criterion. We introduce the State-Centric Decision Process (SDP), a runtime framework that constructs these missing inputs by having the agent build them, predicate by predicate, as it acts. At each step the agent commits to a natural-language predicate describing how the world should look, takes an action to make it true, and checks the observation against it. Predicates that pass become certified states, and the resulting trajectory carries the four objects language environments do not provide, namely a task-induced state space, an observation-to-state mapping, certified transitions, and a termination criterion. We evaluate SDP on five benchmarks spanning planning, scientific exploration, web reasoning, and multi-hop question answering. SDP achieves the best training-free results on all five, with the advantage widening as the horizon grows. The certified trajectories additionally support analyses unavailable to reactive agents, including per-predicate credit assignment, failure localization, partial-progress measurement, and modular operator replacement.
TorR: Towards Brain-Inspired Task-Oriented Reasoning via Cache-Oriented Algorithm-Architecture Co-design
Mar 24, 2026Task-oriented object detection (TOOD) atop CLIP offers open-vocabulary, prompt-driven semantics, yet dense per-window computation and heavy memory traffic hinder real-time, power-limited edge deployment. We present \emph{TorR}, a brain-inspired \textbf{algorithm--architecture co-design} that \textbf{replaces CLIP-style dense alignment with a hyperdimensional (HDC) associative reasoner} and turns temporal coherence into reuse. On the \emph{algorithm} side, TorR reformulates alignment as HDC similarity and graph composition, introducing \emph{partial-similarity reuse} via (i) query caching with per-class score accumulation, (ii) exact $δ$-updates when only a small set of hypervector bits change, and (iii) similarity/load-gated bypass under high system load. On the \emph{architecture} side, TorR instantiates a lane-scalable, bit-sliced item memory with bank/precision gating and a lightweight controller that schedules bypass/$δ$/full paths to meet RT-30/RT-60 targets as object counts vary. Synthesized in a TSMC 28\,nm process and exercised with a cycle-accurate simulator, TorR sustains real-time throughput with millijoule-scale energy per window ($\approx$50\,mJ at 60\,FPS; $\approx$113\,mJ at 30\,FPS) and low latency jitter, while delivering competitive AP@0.5 across five task prompts (mean 44.27\%) within a bounded margin to strong VLM baselines, but at orders-of-magnitude lower energy. The design exposes deployment-time configurability (effective dimension $D'$, thresholds, precision) to trade accuracy, latency, and energy for edge budgets.
MERIT: Multi-domain Efficient RAW Image Translation
Mar 21, 2026RAW images captured by different camera sensors exhibit substantial domain shifts due to varying spectral responses, noise characteristics, and tone behaviors, complicating their direct use in downstream computer vision tasks. Prior methods address this problem by training domain-specific RAW-to-RAW translators for each source-target pair, but such approaches do not scale to real-world scenarios involving multiple types of commercial cameras. In this work, we introduce MERIT, the first unified framework for multi-domain RAW image translation, which leverages a single model to perform translations across arbitrary camera domains. To address domain-specific noise discrepancies, we propose a sensor-aware noise modeling loss that explicitly aligns the signal-dependent noise statistics of the generated images with those of the target domain. We further enhance the generator with a conditional multi-scale large kernel attention module for improved context and sensor-aware feature modeling. To facilitate standardized evaluation, we introduce MDRAW, the first dataset tailored for multi-domain RAW image translation, comprising both paired and unpaired RAW captures from five diverse camera sensors across a wide range of scenes. Extensive experiments demonstrate that MERIT outperforms prior models in both quality (5.56 dB improvement) and scalability (80% reduction in training iterations).
$n$-Musketeers: Reinforcement Learning Shapes Collaboration Among Language Models
Feb 09, 2026Recent progress in reinforcement learning with verifiable rewards (RLVR) shows that small, specialized language models (SLMs) can exhibit structured reasoning without relying on large monolithic LLMs. We introduce soft hidden-state collaboration, where multiple heterogeneous frozen SLM experts are integrated through their internal representations via a trainable attention interface. Experiments on Reasoning Gym and GSM8K show that this latent integration is competitive with strong single-model RLVR baselines. Ablations further reveal a dual mechanism of expert utilization: for simpler arithmetic domains, performance gains can largely be explained by static expert preferences, whereas more challenging settings induce increasingly concentrated and structured expert attention over training, indicating emergent specialization in how the router connects to relevant experts. Overall, hidden-state collaboration provides a compact mechanism for leveraging frozen experts, while offering an observational window into expert utilization patterns and their evolution under RLVR.
Fair Context Learning for Evidence-Balanced Test-Time Adaptation in Vision-Language Models
Feb 02, 2026Vision-Language Models (VLMs) such as CLIP enable strong zero-shot recognition but suffer substantial degradation under distribution shifts. Test-Time Adaptation (TTA) aims to improve robustness using only unlabeled test samples, yet most prompt-based TTA methods rely on entropy minimization -- an approach that can amplify spurious correlations and induce overconfident errors when classes share visual features. We propose Fair Context Learning (FCL), an episodic TTA framework that avoids entropy minimization by explicitly addressing shared-evidence bias. Motivated by our additive evidence decomposition assumption, FCL decouples adaptation into (i) augmentation-based exploration to identify plausible class candidates, and (ii) fairness-driven calibration that adapts text contexts to equalize sensitivity to common visual evidence. This fairness constraint mitigates partial feature obsession and enables effective calibration of text embeddings without relying on entropy reduction. Through extensive evaluation, we empirically validate our theoretical motivation and show that FCL achieves competitive adaptation performance relative to state-of-the-art TTA methods across diverse domain-shift and fine-grained benchmarks.
Internal Flow Signatures for Self-Checking and Refinement in LLMs
Feb 02, 2026Large language models can generate fluent answers that are unfaithful to the provided context, while many safeguards rely on external verification or a separate judge after generation. We introduce \emph{internal flow signatures} that audit decision formation from depthwise dynamics at a fixed inter-block monitoring boundary. The method stabilizes token-wise motion via bias-centered monitoring, then summarizes trajectories in compact \emph{moving} readout-aligned subspaces constructed from the top token and its close competitors within each depth window. Neighboring window frames are aligned by an orthogonal transport, yielding depth-comparable transported step lengths, turning angles, and subspace drift summaries that are invariant to within-window basis choices. A lightweight GRU validator trained on these signatures performs self-checking without modifying the base model. Beyond detection, the validator localizes a culprit depth event and enables a targeted refinement: the model rolls back to the culprit token and clamps an abnormal transported step at the identified block while preserving the orthogonal residual. The resulting pipeline provides actionable localization and low-overhead self-checking from internal decision dynamics. \emph{Code is available at} \texttt{github.com/EavnJeong/Internal-Flow-Signatures-for-Self-Checking-and-Refinement-in-LLMs}.
HopFormer: Sparse Graph Transformers with Explicit Receptive Field Control
Feb 02, 2026Graph Transformers typically rely on explicit positional or structural encodings and dense global attention to incorporate graph topology. In this work, we show that neither is essential. We introduce HopFormer, a graph Transformer that injects structure exclusively through head-specific n-hop masked sparse attention, without the use of positional encodings or architectural modifications. This design provides explicit and interpretable control over receptive fields while enabling genuinely sparse attention whose computational cost scales linearly with mask sparsity. Through extensive experiments on both node-level and graph-level benchmarks, we demonstrate that our approach achieves competitive or superior performance across diverse graph structures. Our results further reveal that dense global attention is often unnecessary: on graphs with strong small-world properties, localized attention yields more stable and consistently high performance, while on graphs with weaker small-world effects, global attention offers diminishing returns. Together, these findings challenge prevailing assumptions in graph Transformer design and highlight sparsity-controlled attention as a principled and efficient alternative.
T-SAR: A Full-Stack Co-design for CPU-Only Ternary LLM Inference via In-Place SIMD ALU Reorganization
Nov 17, 2025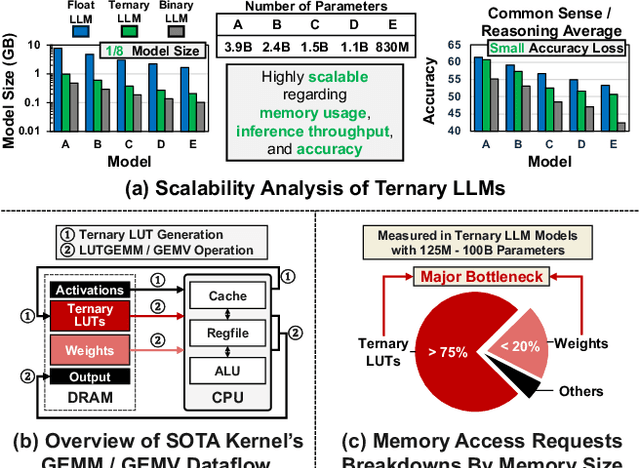
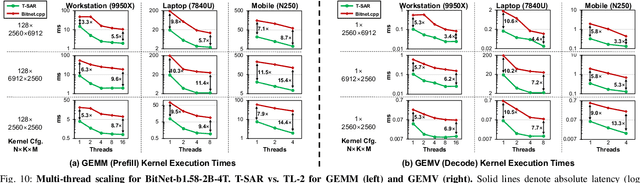
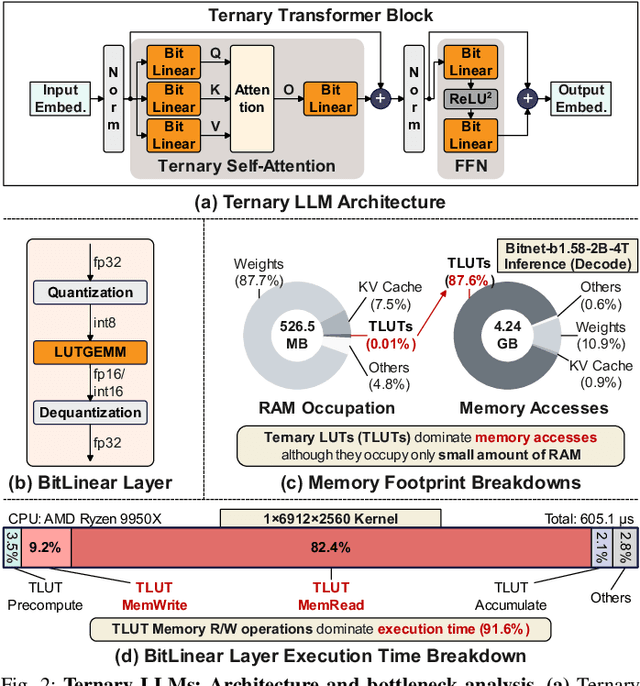
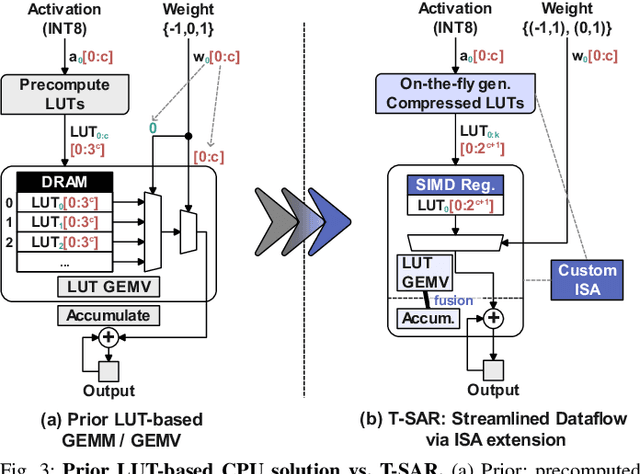
Recent advances in LLMs have outpaced the computational and memory capacities of edge platforms that primarily employ CPUs, thereby challenging efficient and scalable deployment. While ternary quantization enables significant resource savings, existing CPU solutions rely heavily on memory-based lookup tables (LUTs) which limit scalability, and FPGA or GPU accelerators remain impractical for edge use. This paper presents T-SAR, the first framework to achieve scalable ternary LLM inference on CPUs by repurposing the SIMD register file for dynamic, in-register LUT generation with minimal hardware modifications. T-SAR eliminates memory bottlenecks and maximizes data-level parallelism, delivering 5.6-24.5x and 1.1-86.2x improvements in GEMM latency and GEMV throughput, respectively, with only 3.2% power and 1.4% area overheads in SIMD units. T-SAR achieves up to 2.5-4.9x the energy efficiency of an NVIDIA Jetson AGX Orin, establishing a practical approach for efficient LLM inference on edge platforms.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025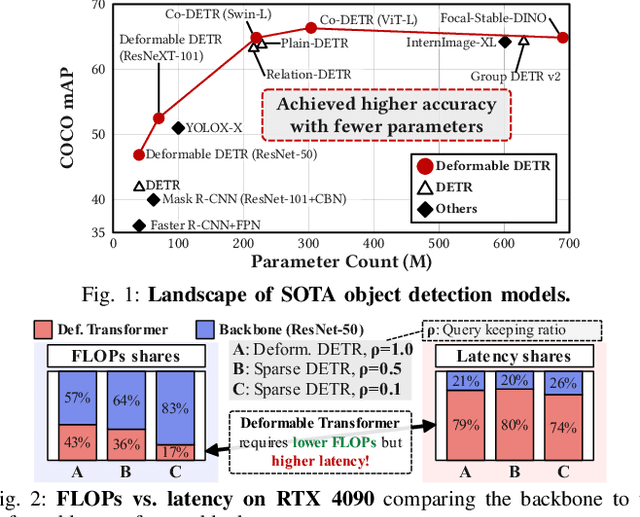
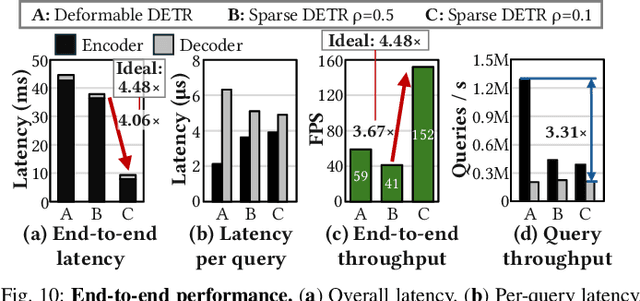
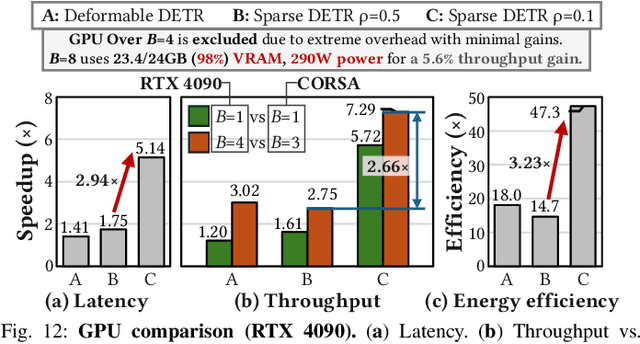
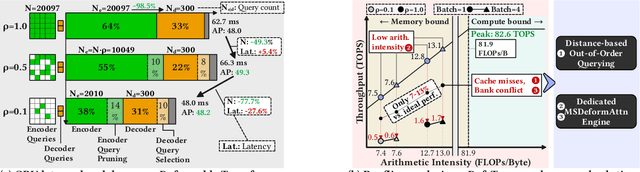
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
Draft and Refine with Visual Experts
Nov 14, 2025While recent Large Vision-Language Models (LVLMs) exhibit strong multimodal reasoning abilities, they often produce ungrounded or hallucinated responses because they rely too heavily on linguistic priors instead of visual evidence. This limitation highlights the absence of a quantitative measure of how much these models actually use visual information during reasoning. We propose Draft and Refine (DnR), an agent framework driven by a question-conditioned utilization metric. The metric quantifies the model's reliance on visual evidence by first constructing a query-conditioned relevance map to localize question-specific cues and then measuring dependence through relevance-guided probabilistic masking. Guided by this metric, the DnR agent refines its initial draft using targeted feedback from external visual experts. Each expert's output (such as boxes or masks) is rendered as visual cues on the image, and the model is re-queried to select the response that yields the largest improvement in utilization. This process strengthens visual grounding without retraining or architectural changes. Experiments across VQA and captioning benchmarks show consistent accuracy gains and reduced hallucination, demonstrating that measuring visual utilization provides a principled path toward more interpretable and evidence-driven multimodal agent systems.