 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025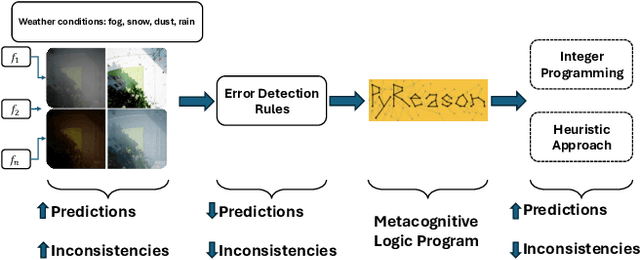
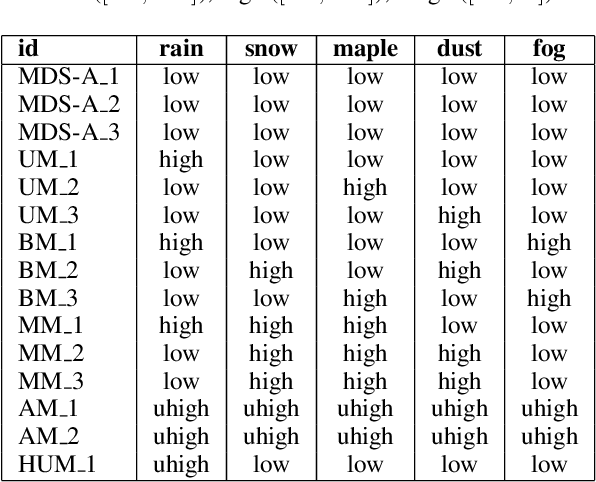
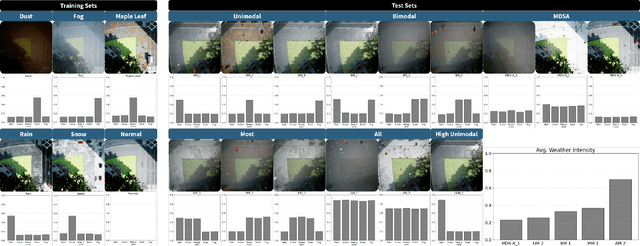
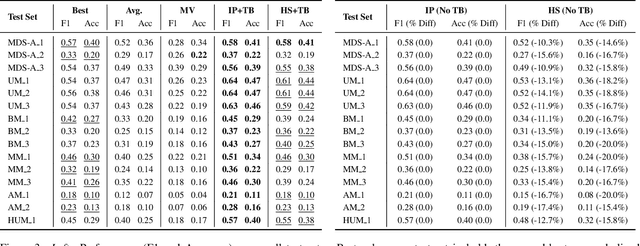
The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
Adaptive Pruning of Deep Neural Networks for Resource-Aware Embedded Intrusion Detection on the Edge
May 20, 2025Artificial neural network pruning is a method in which artificial neural network sizes can be reduced while attempting to preserve the predicting capabilities of the network. This is done to make the model smaller or faster during inference time. In this work we analyze the ability of a selection of artificial neural network pruning methods to generalize to a new cybersecurity dataset utilizing a simpler network type than was designed for. We analyze each method using a variety of pruning degrees to best understand how each algorithm responds to the new environment. This has allowed us to determine the most well fit pruning method of those we searched for the task. Unexpectedly, we have found that many of them do not generalize to the problem well, leaving only a few algorithms working to an acceptable degree.
Continuous GNN-based Anomaly Detection on Edge using Efficient Adaptive Knowledge Graph Learning
Nov 13, 2024



The increasing demand for robust security solutions across various industries has made Video Anomaly Detection (VAD) a critical task in applications such as intelligent surveillance, evidence investigation, and violence detection. Traditional approaches to VAD often rely on finetuning large pre-trained models, which can be computationally expensive and impractical for real-time or resource-constrained environments. To address this, MissionGNN introduced a more efficient method by training a graph neural network (GNN) using a fixed knowledge graph (KG) derived from large language models (LLMs) like GPT-4. While this approach demonstrated significant efficiency in computational power and memory, it faces limitations in dynamic environments where frequent updates to the KG are necessary due to evolving behavior trends and shifting data patterns. These updates typically require cloud-based computation, posing challenges for edge computing applications. In this paper, we propose a novel framework that facilitates continuous KG adaptation directly on edge devices, overcoming the limitations of cloud dependency. Our method dynamically modifies the KG through a three-phase process: pruning, alternating, and creating nodes, enabling real-time adaptation to changing data trends. This continuous learning approach enhances the robustness of anomaly detection models, making them more suitable for deployment in dynamic and resource-constrained environments.
VLTP: Vision-Language Guided Token Pruning for Task-Oriented Segmentation
Sep 13, 2024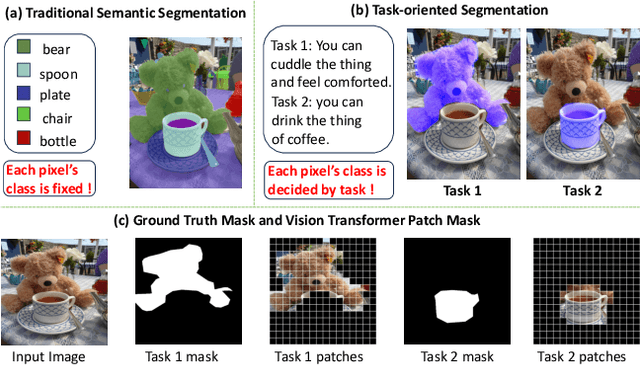
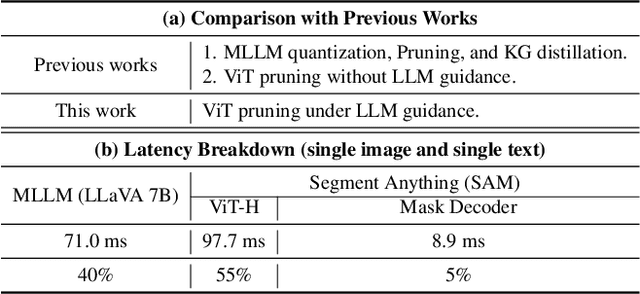
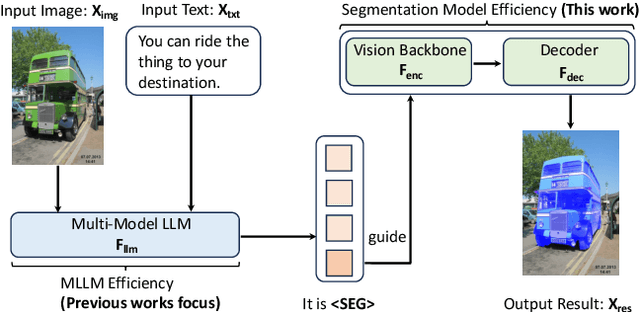
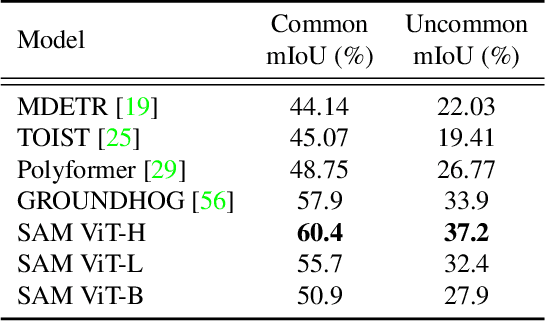
Vision Transformers (ViTs) have emerged as the backbone of many segmentation models, consistently achieving state-of-the-art (SOTA) performance. However, their success comes at a significant computational cost. Image token pruning is one of the most effective strategies to address this complexity. However, previous approaches fall short when applied to more complex task-oriented segmentation (TOS), where the class of each image patch is not predefined but dependent on the specific input task. This work introduces the Vision Language Guided Token Pruning (VLTP), a novel token pruning mechanism that can accelerate ViTbased segmentation models, particularly for TOS guided by multi-modal large language model (MLLM). We argue that ViT does not need to process every image token through all of its layers only the tokens related to reasoning tasks are necessary. We design a new pruning decoder to take both image tokens and vision-language guidance as input to predict the relevance of each image token to the task. Only image tokens with high relevance are passed to deeper layers of the ViT. Experiments show that the VLTP framework reduces the computational costs of ViT by approximately 25% without performance degradation and by around 40% with only a 1% performance drop.
Novelty Detection in Network Traffic: Using Survival Analysis for Feature Identification
Jan 16, 2023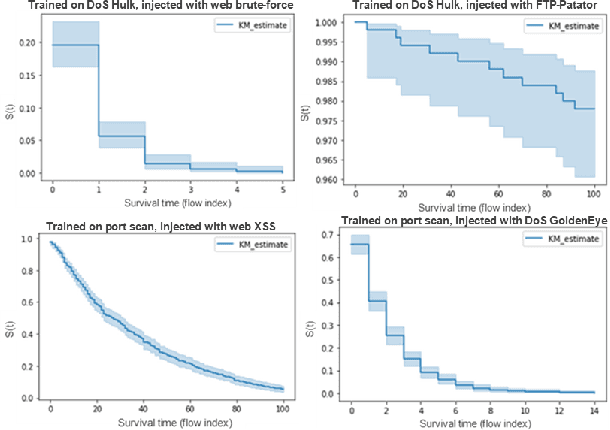

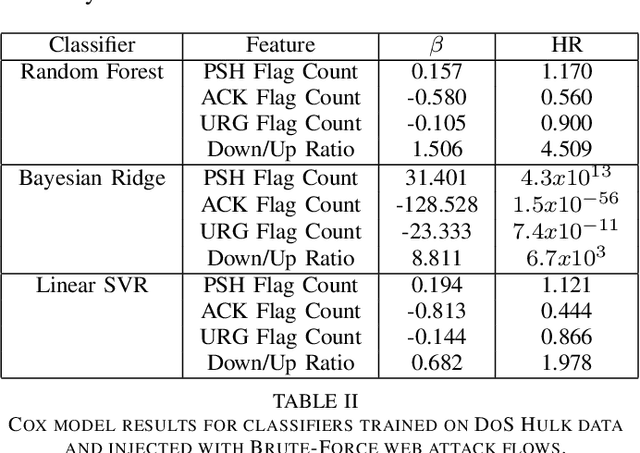
Intrusion Detection Systems are an important component of many organizations' cyber defense and resiliency strategies. However, one downside of these systems is their reliance on known attack signatures for detection of malicious network events. When it comes to unknown attack types and zero-day exploits, modern Intrusion Detection Systems often fall short. In this paper, we introduce an unconventional approach to identifying network traffic features that influence novelty detection based on survival analysis techniques. Specifically, we combine several Cox proportional hazards models and implement Kaplan-Meier estimates to predict the probability that a classifier identifies novelty after the injection of an unknown network attack at any given time. The proposed model is successful at pinpointing PSH Flag Count, ACK Flag Count, URG Flag Count, and Down/Up Ratio as the main features to impact novelty detection via Random Forest, Bayesian Ridge, and Linear Support Vector Regression classifiers.