 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025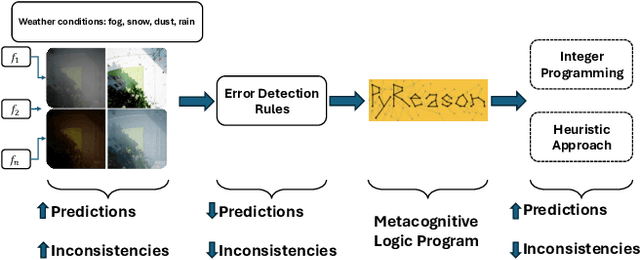
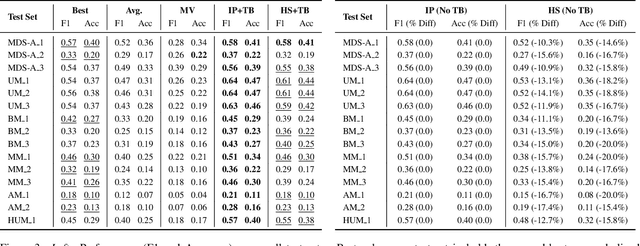
The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
VLC Fusion: Vision-Language Conditioned Sensor Fusion for Robust Object Detection
May 19, 2025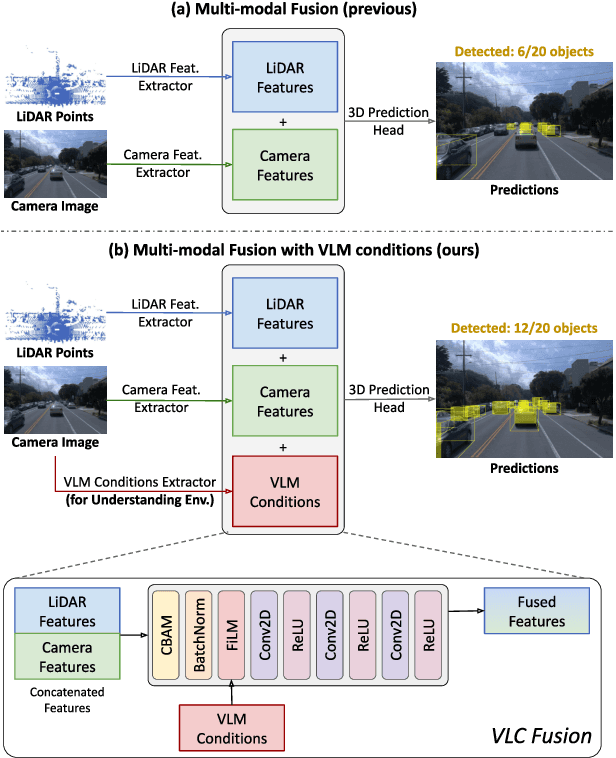

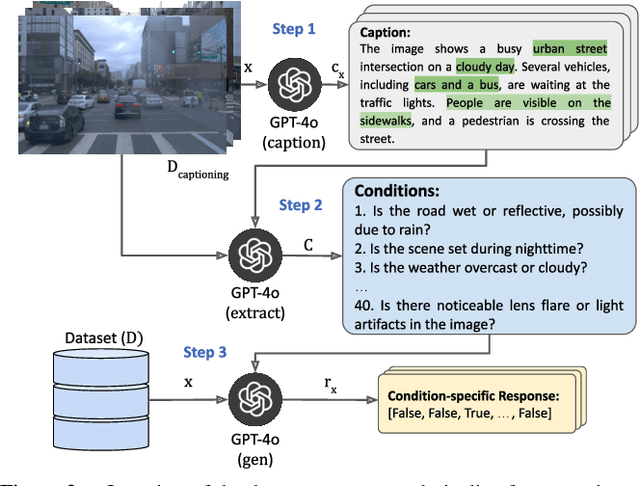
Although fusing multiple sensor modalities can enhance object detection performance, existing fusion approaches often overlook subtle variations in environmental conditions and sensor inputs. As a result, they struggle to adaptively weight each modality under such variations. To address this challenge, we introduce Vision-Language Conditioned Fusion (VLC Fusion), a novel fusion framework that leverages a Vision-Language Model (VLM) to condition the fusion process on nuanced environmental cues. By capturing high-level environmental context such as as darkness, rain, and camera blurring, the VLM guides the model to dynamically adjust modality weights based on the current scene. We evaluate VLC Fusion on real-world autonomous driving and military target detection datasets that include image, LIDAR, and mid-wave infrared modalities. Our experiments show that VLC Fusion consistently outperforms conventional fusion baselines, achieving improved detection accuracy in both seen and unseen scenarios.
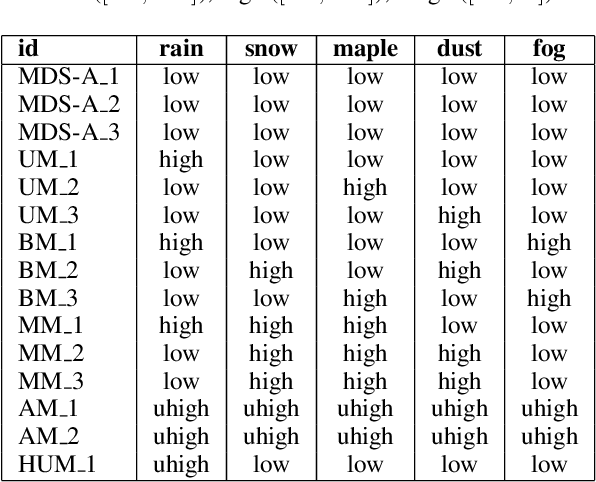
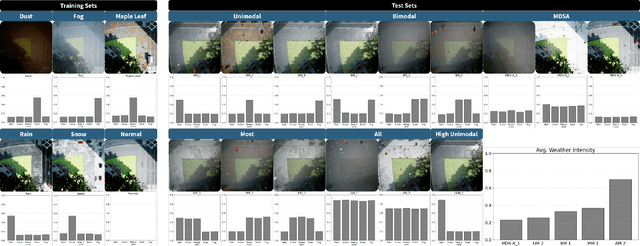
Multiple Distribution Shift -- Aerial (MDS-A): A Dataset for Test-Time Error Detection and Model Adaptation
Feb 18, 2025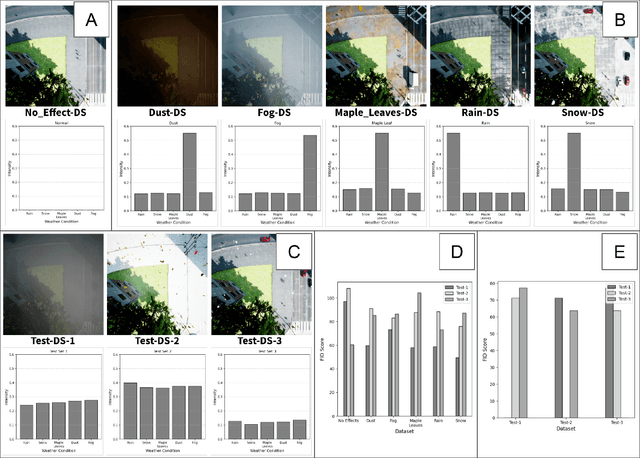
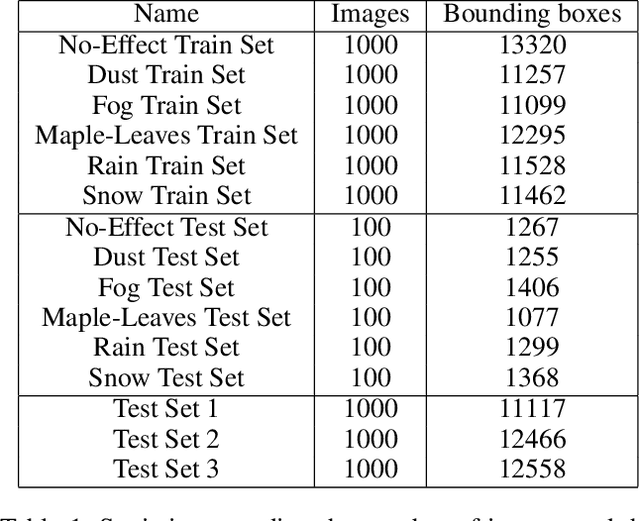

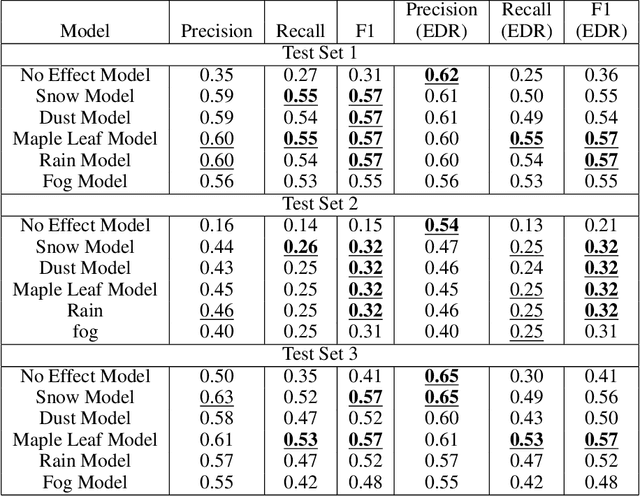
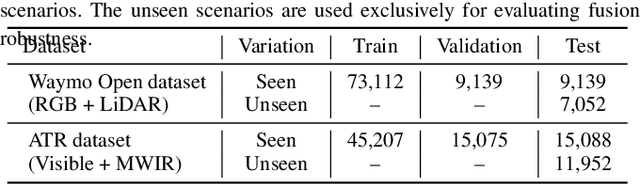
Machine learning models assume that training and test samples are drawn from the same distribution. As such, significant differences between training and test distributions often lead to degradations in performance. We introduce Multiple Distribution Shift -- Aerial (MDS-A) -- a collection of inter-related datasets of the same aerial domain that are perturbed in different ways to better characterize the effects of out-of-distribution performance. Specifically, MDS-A is a set of simulated aerial datasets collected under different weather conditions. We include six datasets under different simulated weather conditions along with six baseline object-detection models, as well as several test datasets that are a mix of weather conditions that we show have significant differences from the training data. In this paper, we present characterizations of MDS-A, provide performance results for the baseline machine learning models (on both their specific training datasets and the test data), as well as results of the baselines after employing recent knowledge-engineering error-detection techniques (EDR) thought to improve out-of-distribution performance. The dataset is available at https://lab-v2.github.io/mdsa-dataset-website.
Metal Price Spike Prediction via a Neurosymbolic Ensemble Approach
Oct 16, 2024



Predicting price spikes in critical metals such as Cobalt, Copper, Magnesium, and Nickel is crucial for mitigating economic risks associated with global trends like the energy transition and reshoring of manufacturing. While traditional models have focused on regression-based approaches, our work introduces a neurosymbolic ensemble framework that integrates multiple neural models with symbolic error detection and correction rules. This framework is designed to enhance predictive accuracy by correcting individual model errors and offering interpretability through rule-based explanations. We show that our method provides up to 6.42% improvement in precision, 29.41% increase in recall at 13.24% increase in F1 over the best performing neural models. Further, our method, as it is based on logical rules, has the benefit of affording an explanation as to which combination of neural models directly contribute to a given prediction.
Diversity Measures: Domain-Independent Proxies for Failure in Language Model Queries
Aug 22, 2023Error prediction in large language models often relies on domain-specific information. In this paper, we present measures for quantification of error in the response of a large language model based on the diversity of responses to a given prompt - hence independent of the underlying application. We describe how three such measures - based on entropy, Gini impurity, and centroid distance - can be employed. We perform a suite of experiments on multiple datasets and temperature settings to demonstrate that these measures strongly correlate with the probability of failure. Additionally, we present empirical results demonstrating how these measures can be applied to few-shot prompting, chain-of-thought reasoning, and error detection.
An Independent Evaluation of ChatGPT on Mathematical Word Problems (MWP)
Feb 28, 2023



We study the performance of a commercially available large language model (LLM) known as ChatGPT on math word problems (MWPs) from the dataset DRAW-1K. To our knowledge, this is the first independent evaluation of ChatGPT. We found that ChatGPT's performance changes dramatically based on the requirement to show its work, failing 20% of the time when it provides work compared with 84% when it does not. Further several factors about MWPs relating to the number of unknowns and number of operations that lead to a higher probability of failure when compared with the prior, specifically noting (across all experiments) that the probability of failure increases linearly with the number of addition and subtraction operations. We also have released the dataset of ChatGPT's responses to the MWPs to support further work on the characterization of LLM performance and present baseline machine learning models to predict if ChatGPT can correctly answer an MWP. We have released a dataset comprised of ChatGPT's responses to support further research in this area.