 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Distribution Shift -- Aerial (MDS-A): A Dataset for Test-Time Error Detection and Model Adaptation
Feb 18, 2025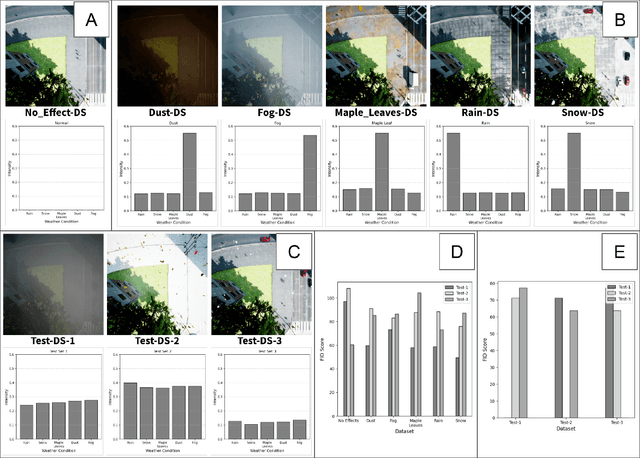
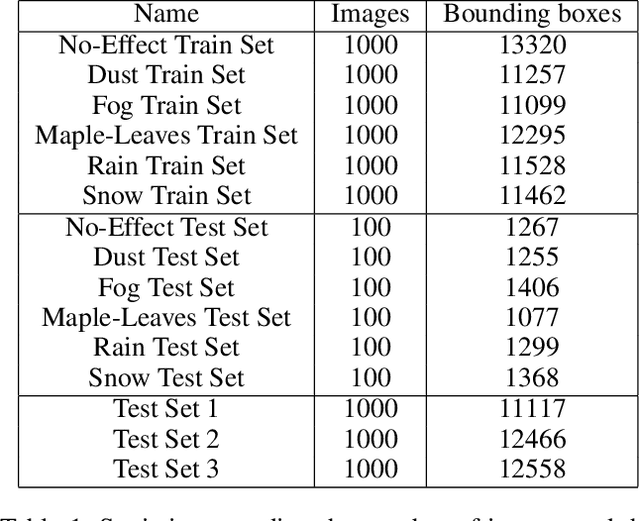

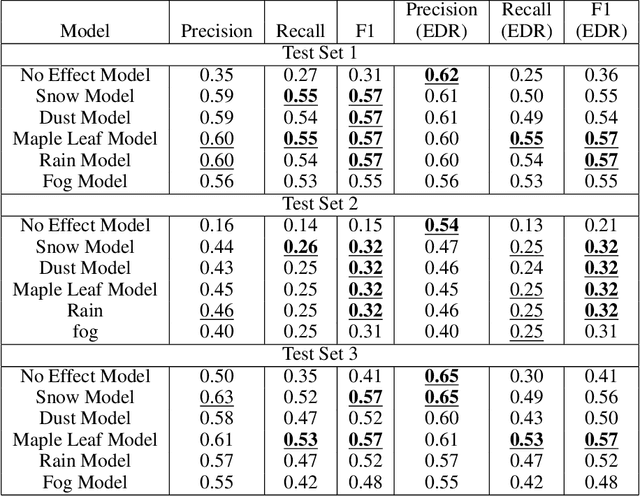
Machine learning models assume that training and test samples are drawn from the same distribution. As such, significant differences between training and test distributions often lead to degradations in performance. We introduce Multiple Distribution Shift -- Aerial (MDS-A) -- a collection of inter-related datasets of the same aerial domain that are perturbed in different ways to better characterize the effects of out-of-distribution performance. Specifically, MDS-A is a set of simulated aerial datasets collected under different weather conditions. We include six datasets under different simulated weather conditions along with six baseline object-detection models, as well as several test datasets that are a mix of weather conditions that we show have significant differences from the training data. In this paper, we present characterizations of MDS-A, provide performance results for the baseline machine learning models (on both their specific training datasets and the test data), as well as results of the baselines after employing recent knowledge-engineering error-detection techniques (EDR) thought to improve out-of-distribution performance. The dataset is available at https://lab-v2.github.io/mdsa-dataset-website.
Abduction of Domain Relationships from Data for VQA
Feb 13, 2025In this paper, we study the problem of visual question answering (VQA) where the image and query are represented by ASP programs that lack domain data. We provide an approach that is orthogonal and complementary to existing knowledge augmentation techniques where we abduce domain relationships of image constructs from past examples. After framing the abduction problem, we provide a baseline approach, and an implementation that significantly improves the accuracy of query answering yet requires few examples.
* In Proceedings ICLP 2024, arXiv:2502.08453
Probabilistic Foundations for Metacognition via Hybrid-AI
Feb 08, 2025Metacognition is the concept of reasoning about an agent's own internal processes, and it has recently received renewed attention with respect to artificial intelligence (AI) and, more specifically, machine learning systems. This paper reviews a hybrid-AI approach known as "error detecting and correcting rules" (EDCR) that allows for the learning of rules to correct perceptual (e.g., neural) models. Additionally, we introduce a probabilistic framework that adds rigor to prior empirical studies, and we use this framework to prove results on necessary and sufficient conditions for metacognitive improvement, as well as limits to the approach. A set of future
Do Large Language Models Show Biases in Causal Learning?
Dec 13, 2024



Causal learning is the cognitive process of developing the capability of making causal inferences based on available information, often guided by normative principles. This process is prone to errors and biases, such as the illusion of causality, in which people perceive a causal relationship between two variables despite lacking supporting evidence. This cognitive bias has been proposed to underlie many societal problems, including social prejudice, stereotype formation, misinformation, and superstitious thinking. In this research, we investigate whether large language models (LLMs) develop causal illusions, both in real-world and controlled laboratory contexts of causal learning and inference. To this end, we built a dataset of over 2K samples including purely correlational cases, situations with null contingency, and cases where temporal information excludes the possibility of causality by placing the potential effect before the cause. We then prompted the models to make statements or answer causal questions to evaluate their tendencies to infer causation erroneously in these structured settings. Our findings show a strong presence of causal illusion bias in LLMs. Specifically, in open-ended generation tasks involving spurious correlations, the models displayed bias at levels comparable to, or even lower than, those observed in similar studies on human subjects. However, when faced with null-contingency scenarios or temporal cues that negate causal relationships, where it was required to respond on a 0-100 scale, the models exhibited significantly higher bias. These findings suggest that the models have not uniformly, consistently, or reliably internalized the normative principles essential for accurate causal learning.
Geospatial Trajectory Generation via Efficient Abduction: Deployment for Independent Testing
Jul 08, 2024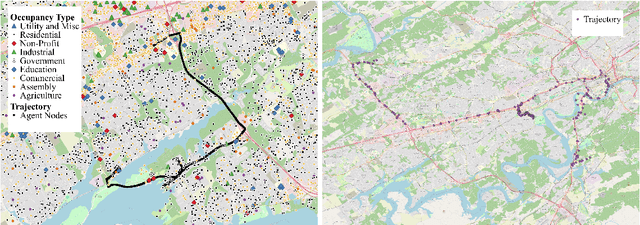

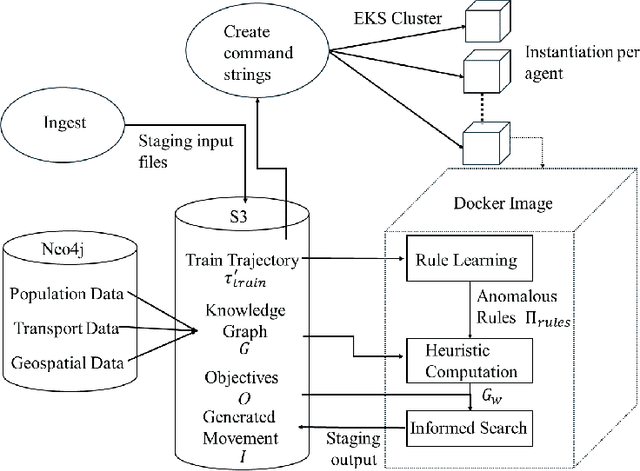
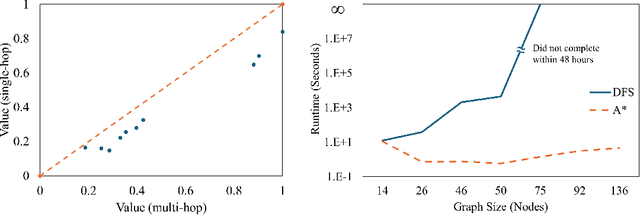
The ability to generate artificial human movement patterns while meeting location and time constraints is an important problem in the security community, particularly as it enables the study of the analog problem of detecting such patterns while maintaining privacy. We frame this problem as an instance of abduction guided by a novel parsimony function represented as an aggregate truth value over an annotated logic program. This approach has the added benefit of affording explainability to an analyst user. By showing that any subset of such a program can provide a lower bound on this parsimony requirement, we are able to abduce movement trajectories efficiently through an informed (i.e., A*) search. We describe how our implementation was enhanced with the application of multiple techniques in order to be scaled and integrated with a cloud-based software stack that included bottom-up rule learning, geolocated knowledge graph retrieval/management, and interfaces with government systems for independently conducted government-run tests for which we provide results. We also report on our own experiments showing that we not only provide exact results but also scale to very large scenarios and provide realistic agent trajectories that can go undetected by machine learning anomaly detectors.
Extensions to Generalized Annotated Logic and an Equivalent Neural Architecture
Feb 23, 2023While deep neural networks have led to major advances in image recognition, language translation, data mining, and game playing, there are well-known limits to the paradigm such as lack of explainability, difficulty of incorporating prior knowledge, and modularity. Neuro symbolic hybrid systems have recently emerged as a straightforward way to extend deep neural networks by incorporating ideas from symbolic reasoning such as computational logic. In this paper, we propose a list desirable criteria for neuro symbolic systems and examine how some of the existing approaches address these criteria. We then propose an extension to generalized annotated logic that allows for the creation of an equivalent neural architecture comprising an alternate neuro symbolic hybrid. However, unlike previous approaches that rely on continuous optimization for the training process, our framework is designed as a binarized neural network that uses discrete optimization. We provide proofs of correctness and discuss several of the challenges that must be overcome to realize this framework in an implemented system.
Reasoning about Complex Networks: A Logic Programming Approach
Sep 29, 2022Reasoning about complex networks has in recent years become an important topic of study due to its many applications: the adoption of commercial products, spread of disease, the diffusion of an idea, etc. In this paper, we present the MANCaLog language, a formalism based on logic programming that satisfies a set of desiderata proposed in previous work as recommendations for the development of approaches to reasoning in complex networks. To the best of our knowledge, this is the first formalism that satisfies all such criteria. We first focus on algorithms for finding minimal models (on which multi-attribute analysis can be done), and then on how this formalism can be applied in certain real world scenarios. Towards this end, we study the problem of deciding group membership in social networks: given a social network and a set of groups where group membership of only some of the individuals in the network is known, we wish to determine a degree of membership for the remaining group-individual pairs. We develop a prototype implementation that we use to obtain experimental results on two real world datasets, including a current social network of criminal gangs in a major U.S.\ city. We then show how the assignment of degree of membership to nodes in this case allows for a better understanding of the criminal gang problem when combined with other social network mining techniques -- including detection of sub-groups and identification of core group members -- which would not be possible without further identification of additional group members.
On the Importance of Domain-specific Explanations in AI-based Cybersecurity Systems (Technical Report)
Aug 02, 2021
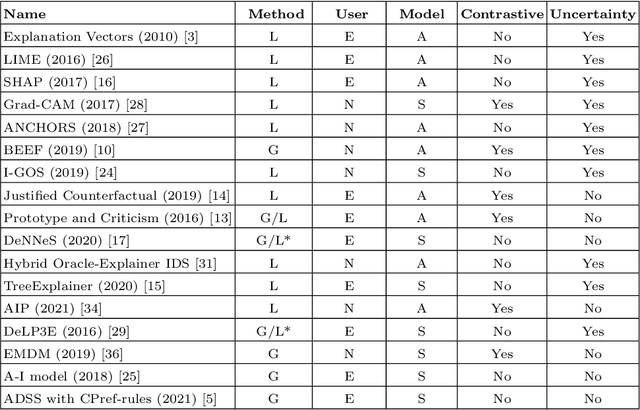
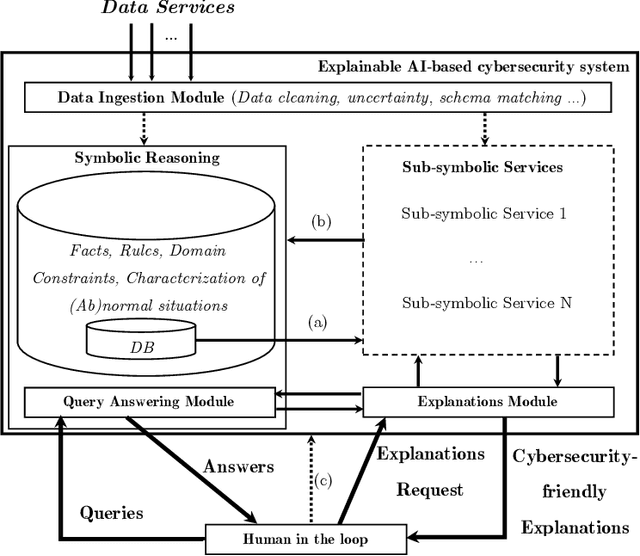
With the availability of large datasets and ever-increasing computing power, there has been a growing use of data-driven artificial intelligence systems, which have shown their potential for successful application in diverse areas. However, many of these systems are not able to provide information about the rationale behind their decisions to their users. Lack of understanding of such decisions can be a major drawback, especially in critical domains such as those related to cybersecurity. In light of this problem, in this paper we make three contributions: (i) proposal and discussion of desiderata for the explanation of outputs generated by AI-based cybersecurity systems; (ii) a comparative analysis of approaches in the literature on Explainable Artificial Intelligence (XAI) under the lens of both our desiderata and further dimensions that are typically used for examining XAI approaches; and (iii) a general architecture that can serve as a roadmap for guiding research efforts towards the development of explainable AI-based cybersecurity systems -- at its core, this roadmap proposes combinations of several research lines in a novel way towards tackling the unique challenges that arise in this context.
An Approach to Characterize Graded Entailment of Arguments through a Label-based Framework
Mar 05, 2019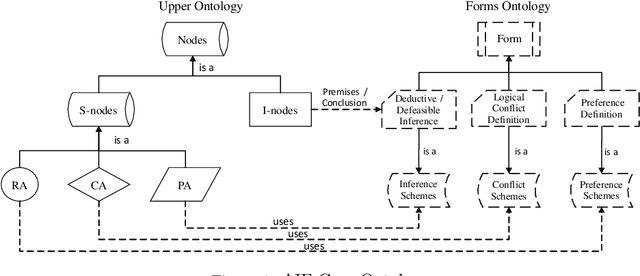
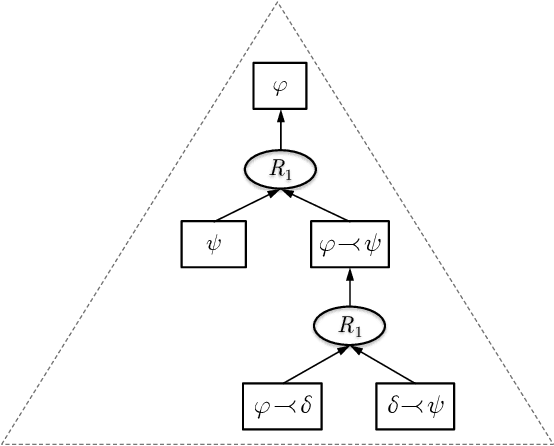
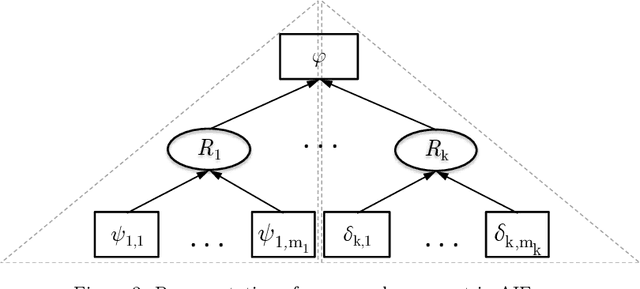
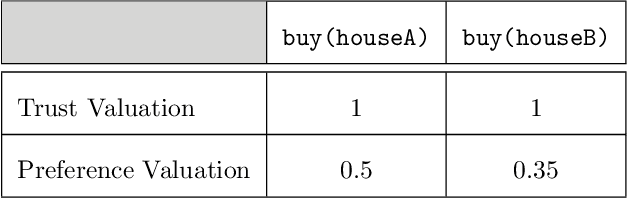
Argumentation theory is a powerful paradigm that formalizes a type of commonsense reasoning that aims to simulate the human ability to resolve a specific problem in an intelligent manner. A classical argumentation process takes into account only the properties related to the intrinsic logical soundness of an argument in order to determine its acceptability status. However, these properties are not always the only ones that matter to establish the argument's acceptability---there exist other qualities, such as strength, weight, social votes, trust degree, relevance level, and certainty degree, among others.
DARKMENTION: A Deployed System to Predict Enterprise-Targeted External Cyberattacks
Oct 30, 2018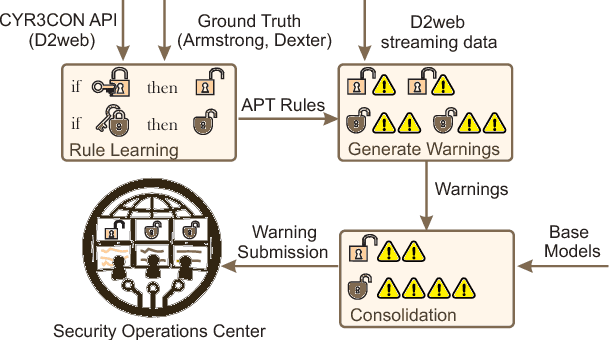
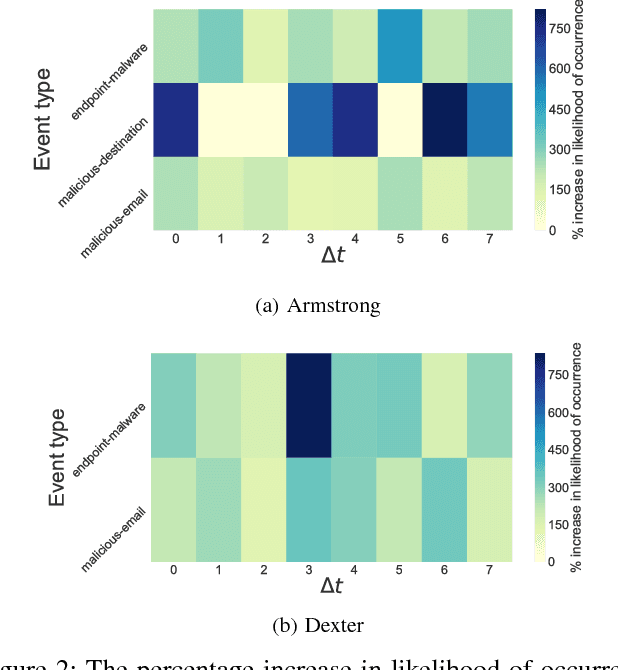
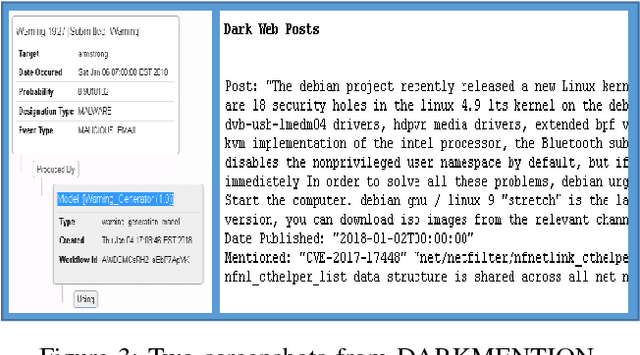
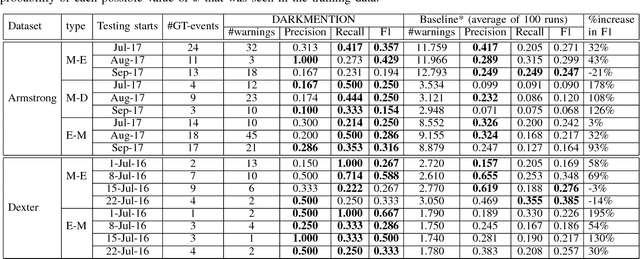
Recent incidents of data breaches call for organizations to proactively identify cyber attacks on their systems. Darkweb/Deepweb (D2web) forums and marketplaces provide environments where hackers anonymously discuss existing vulnerabilities and commercialize malicious software to exploit those vulnerabilities. These platforms offer security practitioners a threat intelligence environment that allows to mine for patterns related to organization-targeted cyber attacks. In this paper, we describe a system (called DARKMENTION) that learns association rules correlating indicators of attacks from D2web to real-world cyber incidents. Using the learned rules, DARKMENTION generates and submits warnings to a Security Operations Center (SOC) prior to attacks. Our goal was to design a system that automatically generates enterprise-targeted warnings that are timely, actionable, accurate, and transparent. We show that DARKMENTION meets our goal. In particular, we show that it outperforms baseline systems that attempt to generate warnings of cyber attacks related to two enterprises with an average increase in F1 score of about 45% and 57%. Additionally, DARKMENTION was deployed as part of a larger system that is built under a contract with the IARPA Cyber-attack Automated Unconventional Sensor Environment (CAUSE) program. It is actively producing warnings that precede attacks by an average of 3 days.