 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Anatomy of Uncertainty in LLMs
Mar 26, 2026Understanding why a large language model (LLM) is uncertain about the response is important for their reliable deployment. Current approaches, which either provide a single uncertainty score or rely on the classical aleatoric-epistemic dichotomy, fail to offer actionable insights for improving the generative model. Recent studies have also shown that such methods are not enough for understanding uncertainty in LLMs. In this work, we advocate for an uncertainty decomposition framework that dissects LLM uncertainty into three distinct semantic components: (i) input ambiguity, arising from ambiguous prompts; (ii) knowledge gaps, caused by insufficient parametric evidence; and (iii) decoding randomness, stemming from stochastic sampling. Through a series of experiments we demonstrate that the dominance of these components can shift across model size and task. Our framework provides a better understanding to audit LLM reliability and detect hallucinations, paving the way for targeted interventions and more trustworthy systems.
Learning to Configure Agentic AI Systems
Feb 12, 2026Configuring LLM-based agent systems involves choosing workflows, tools, token budgets, and prompts from a large combinatorial design space, and is typically handled today by fixed large templates or hand-tuned heuristics. This leads to brittle behavior and unnecessary compute, since the same cumbersome configuration is often applied to both easy and hard input queries. We formulate agent configuration as a query-wise decision problem and introduce ARC (Agentic Resource & Configuration learner), which learns a light-weight hierarchical policy using reinforcement learning to dynamically tailor these configurations. Across multiple benchmarks spanning reasoning and tool-augmented question answering, the learned policy consistently outperforms strong hand-designed and other baselines, achieving up to 25% higher task accuracy while also reducing token and runtime costs. These results demonstrate that learning per-query agent configurations is a powerful alternative to "one size fits all" designs.
Consistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025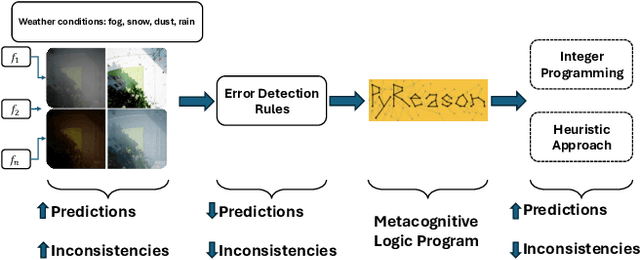
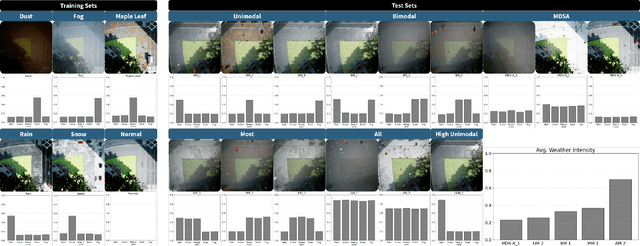
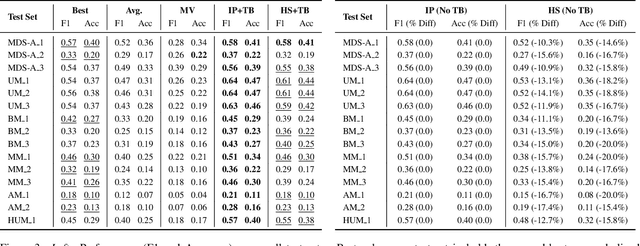
The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
VLC Fusion: Vision-Language Conditioned Sensor Fusion for Robust Object Detection
May 19, 2025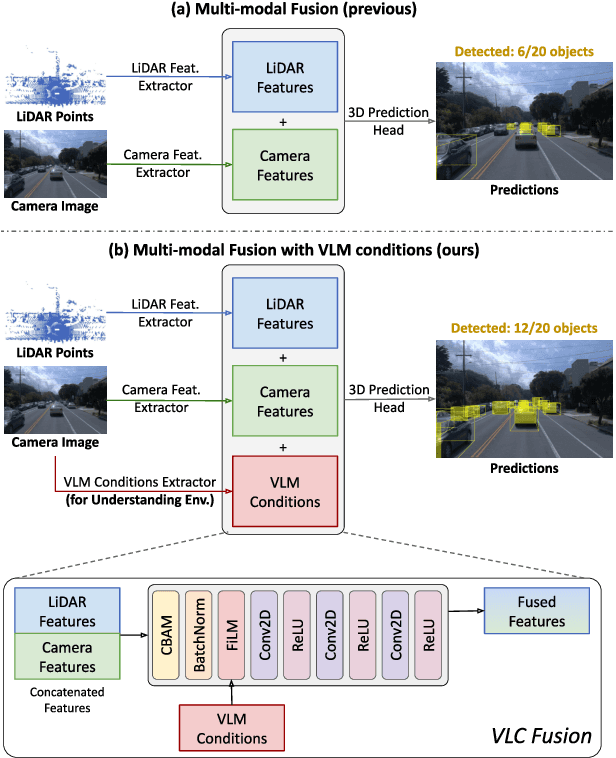
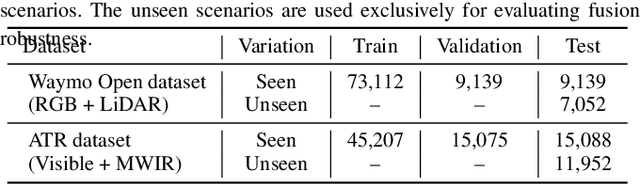

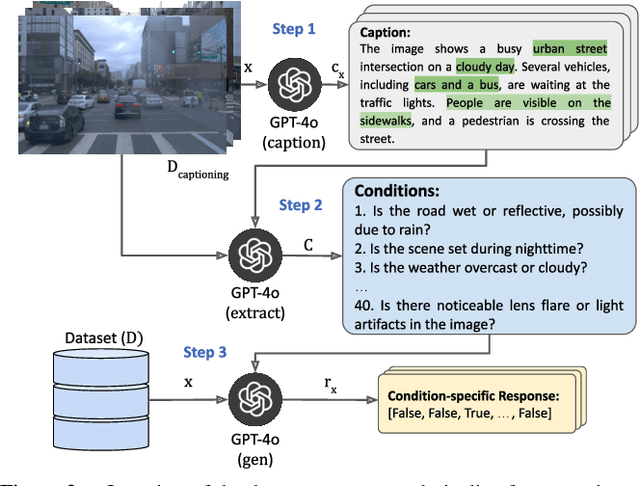
Although fusing multiple sensor modalities can enhance object detection performance, existing fusion approaches often overlook subtle variations in environmental conditions and sensor inputs. As a result, they struggle to adaptively weight each modality under such variations. To address this challenge, we introduce Vision-Language Conditioned Fusion (VLC Fusion), a novel fusion framework that leverages a Vision-Language Model (VLM) to condition the fusion process on nuanced environmental cues. By capturing high-level environmental context such as as darkness, rain, and camera blurring, the VLM guides the model to dynamically adjust modality weights based on the current scene. We evaluate VLC Fusion on real-world autonomous driving and military target detection datasets that include image, LIDAR, and mid-wave infrared modalities. Our experiments show that VLC Fusion consistently outperforms conventional fusion baselines, achieving improved detection accuracy in both seen and unseen scenarios.
Multiple Distribution Shift -- Aerial (MDS-A): A Dataset for Test-Time Error Detection and Model Adaptation
Feb 18, 2025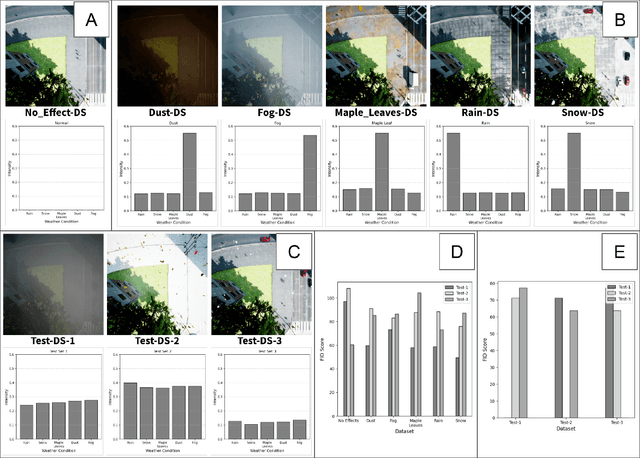
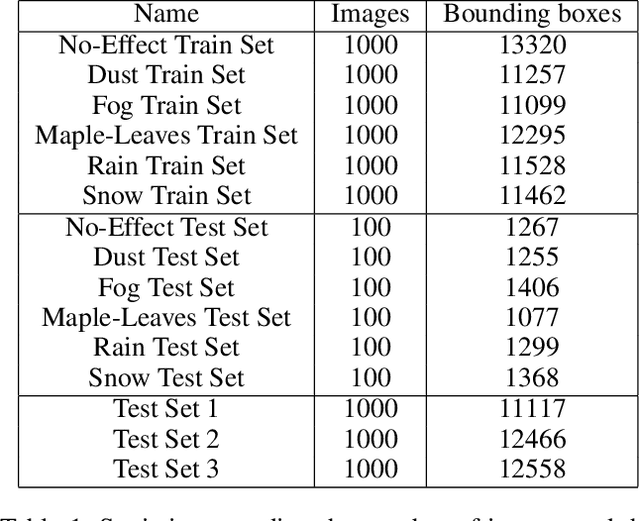

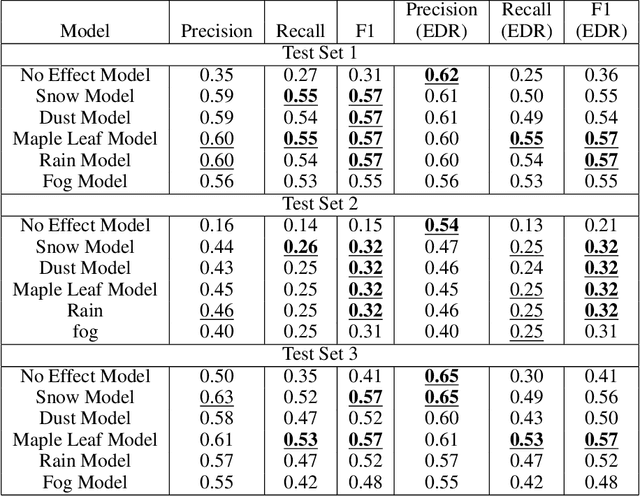
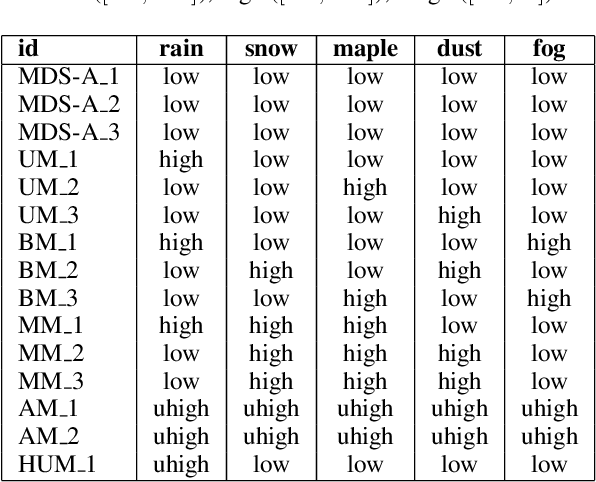
Machine learning models assume that training and test samples are drawn from the same distribution. As such, significant differences between training and test distributions often lead to degradations in performance. We introduce Multiple Distribution Shift -- Aerial (MDS-A) -- a collection of inter-related datasets of the same aerial domain that are perturbed in different ways to better characterize the effects of out-of-distribution performance. Specifically, MDS-A is a set of simulated aerial datasets collected under different weather conditions. We include six datasets under different simulated weather conditions along with six baseline object-detection models, as well as several test datasets that are a mix of weather conditions that we show have significant differences from the training data. In this paper, we present characterizations of MDS-A, provide performance results for the baseline machine learning models (on both their specific training datasets and the test data), as well as results of the baselines after employing recent knowledge-engineering error-detection techniques (EDR) thought to improve out-of-distribution performance. The dataset is available at https://lab-v2.github.io/mdsa-dataset-website.
ExpressivityArena: Can LLMs Express Information Implicitly?
Nov 12, 2024While Large Language Models (LLMs) have demonstrated remarkable performance in certain dimensions, their ability to express implicit language cues that human use for effective communication remains unclear. This paper presents ExpressivityArena, a Python library for measuring the implicit communication abilities of LLMs. We provide a comprehensive framework to evaluate expressivity of arbitrary LLMs and explore its practical implications. To this end, we refine the definition and measurements of ``expressivity,'' and use our framework in a set of small experiments. These experiments test LLMs in creative and logical tasks such as poetry, coding, and emotion-based responses. They are then evaluated by an automated grader, through ExpressivityArena, which we verify to be the most pragmatic for testing expressivity. Building on these experiments, we deepen our understanding of the expressivity of LLMs by assessing their ability to remain expressive in conversations. Our findings indicate that LLMs are capable of generating and understanding expressive content, however, with some limitations. These insights will inform the future development and deployment of expressive LLMs. We provide the code for ExpressivityArena alongside our paper.
LLM-Assisted Red Teaming of Diffusion Models through "Failures Are Fated, But Can Be Faded"
Oct 22, 2024In large deep neural networks that seem to perform surprisingly well on many tasks, we also observe a few failures related to accuracy, social biases, and alignment with human values, among others. Therefore, before deploying these models, it is crucial to characterize this failure landscape for engineers to debug or audit models. Nevertheless, it is infeasible to exhaustively test for all possible combinations of factors that could lead to a model's failure. In this paper, we improve the "Failures are fated, but can be faded" framework (arXiv:2406.07145)--a post-hoc method to explore and construct the failure landscape in pre-trained generative models--with a variety of deep reinforcement learning algorithms, screening tests, and LLM-based rewards and state generation. With the aid of limited human feedback, we then demonstrate how to restructure the failure landscape to be more desirable by moving away from the discovered failure modes. We empirically demonstrate the effectiveness of the proposed method on diffusion models. We also highlight the strengths and weaknesses of each algorithm in identifying failure modes.
Trustworthy Conceptual Explanations for Neural Networks in Robot Decision-Making
Sep 16, 2024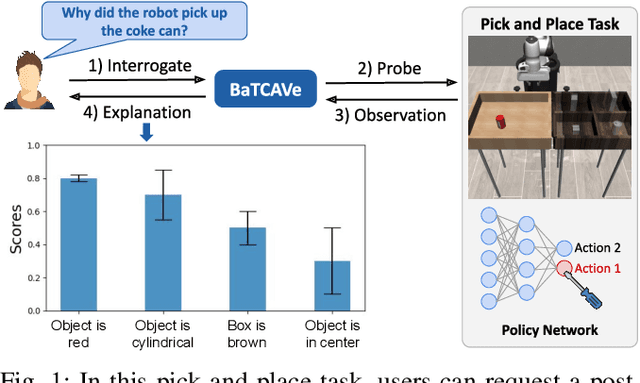


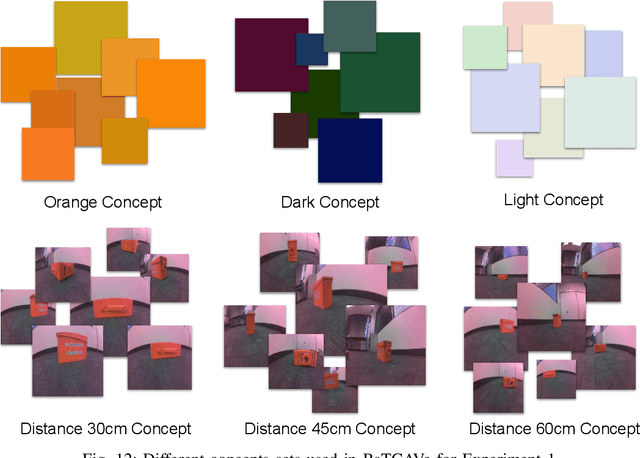
Black box neural networks are an indispensable part of modern robots. Nevertheless, deploying such high-stakes systems in real-world scenarios poses significant challenges when the stakeholders, such as engineers and legislative bodies, lack insights into the neural networks' decision-making process. Presently, explainable AI is primarily tailored to natural language processing and computer vision, falling short in two critical aspects when applied in robots: grounding in decision-making tasks and the ability to assess trustworthiness of their explanations. In this paper, we introduce a trustworthy explainable robotics technique based on human-interpretable, high-level concepts that attribute to the decisions made by the neural network. Our proposed technique provides explanations with associated uncertainty scores by matching neural network's activations with human-interpretable visualizations. To validate our approach, we conducted a series of experiments with various simulated and real-world robot decision-making models, demonstrating the effectiveness of the proposed approach as a post-hoc, human-friendly robot learning diagnostic tool.
Explainable Concept Generation through Vision-Language Preference Learning
Aug 24, 2024Concept-based explanations have become a popular choice for explaining deep neural networks post-hoc because, unlike most other explainable AI techniques, they can be used to test high-level visual "concepts" that are not directly related to feature attributes. For instance, the concept of "stripes" is important to classify an image as a zebra. Concept-based explanation methods, however, require practitioners to guess and collect multiple candidate concept image sets, which can often be imprecise and labor-intensive. Addressing this limitation, in this paper, we frame concept image set creation as an image generation problem. However, since naively using a generative model does not result in meaningful concepts, we devise a reinforcement learning-based preference optimization algorithm that fine-tunes the vision-language generative model from approximate textual descriptions of concepts. Through a series of experiments, we demonstrate the capability of our method to articulate complex, abstract concepts that are otherwise challenging to craft manually. In addition to showing the efficacy and reliability of our method, we show how our method can be used as a diagnostic tool for analyzing neural networks.
HPix: Generating Vector Maps from Satellite Images
Jul 18, 2024Vector maps find widespread utility across diverse domains due to their capacity to not only store but also represent discrete data boundaries such as building footprints, disaster impact analysis, digitization, urban planning, location points, transport links, and more. Although extensive research exists on identifying building footprints and road types from satellite imagery, the generation of vector maps from such imagery remains an area with limited exploration. Furthermore, conventional map generation techniques rely on labor-intensive manual feature extraction or rule-based approaches, which impose inherent limitations. To surmount these limitations, we propose a novel method called HPix, which utilizes modified Generative Adversarial Networks (GANs) to generate vector tile map from satellite images. HPix incorporates two hierarchical frameworks: one operating at the global level and the other at the local level, resulting in a comprehensive model. Through empirical evaluations, our proposed approach showcases its effectiveness in producing highly accurate and visually captivating vector tile maps derived from satellite images. We further extend our study's application to include mapping of road intersections and building footprints cluster based on their area.