 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Conceptual Explanations for Neural Networks in Robot Decision-Making
Paper and Code
Sep 16, 2024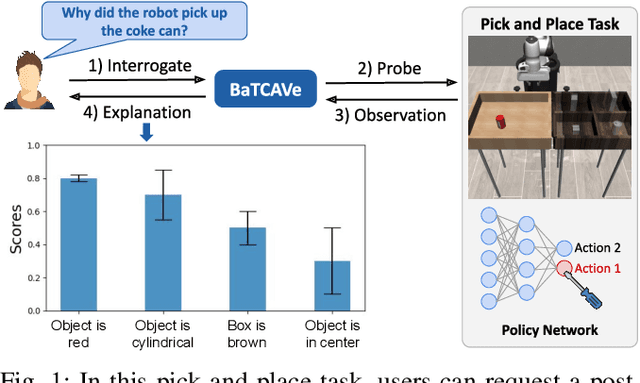


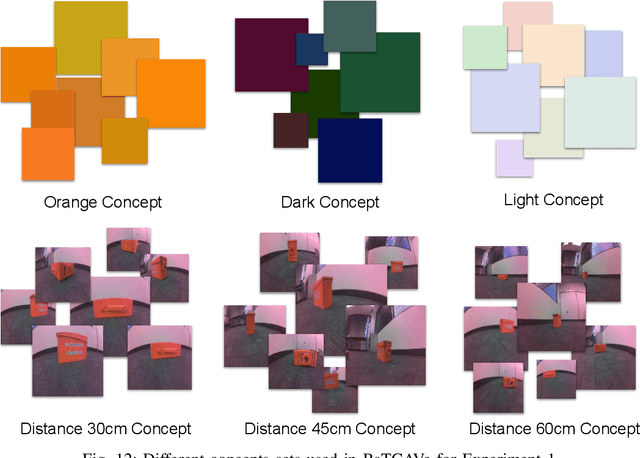
Black box neural networks are an indispensable part of modern robots. Nevertheless, deploying such high-stakes systems in real-world scenarios poses significant challenges when the stakeholders, such as engineers and legislative bodies, lack insights into the neural networks' decision-making process. Presently, explainable AI is primarily tailored to natural language processing and computer vision, falling short in two critical aspects when applied in robots: grounding in decision-making tasks and the ability to assess trustworthiness of their explanations. In this paper, we introduce a trustworthy explainable robotics technique based on human-interpretable, high-level concepts that attribute to the decisions made by the neural network. Our proposed technique provides explanations with associated uncertainty scores by matching neural network's activations with human-interpretable visualizations. To validate our approach, we conducted a series of experiments with various simulated and real-world robot decision-making models, demonstrating the effectiveness of the proposed approach as a post-hoc, human-friendly robot learning diagnostic tool.