 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Anatomy of Uncertainty in LLMs
Mar 26, 2026Understanding why a large language model (LLM) is uncertain about the response is important for their reliable deployment. Current approaches, which either provide a single uncertainty score or rely on the classical aleatoric-epistemic dichotomy, fail to offer actionable insights for improving the generative model. Recent studies have also shown that such methods are not enough for understanding uncertainty in LLMs. In this work, we advocate for an uncertainty decomposition framework that dissects LLM uncertainty into three distinct semantic components: (i) input ambiguity, arising from ambiguous prompts; (ii) knowledge gaps, caused by insufficient parametric evidence; and (iii) decoding randomness, stemming from stochastic sampling. Through a series of experiments we demonstrate that the dominance of these components can shift across model size and task. Our framework provides a better understanding to audit LLM reliability and detect hallucinations, paving the way for targeted interventions and more trustworthy systems.
LLM Routing as Reasoning: A MaxSAT View
Mar 13, 2026Routing a query through an appropriate LLM is challenging, particularly when user preferences are expressed in natural language and model attributes are only partially observable. We propose a constraint-based interpretation of language-conditioned LLM routing, formulating it as a weighted MaxSAT/MaxSMT problem in which natural language feedback induces hard and soft constraints over model attributes. Under this view, routing corresponds to selecting models that approximately maximize satisfaction of feedback-conditioned clauses. Empirical analysis on a 25-model benchmark shows that language feedback produces near-feasible recommendation sets, while no-feedback scenarios reveal systematic priors. Our results suggest that LLM routing can be understood as structured constraint optimization under language-conditioned preferences.
Learning to Configure Agentic AI Systems
Feb 12, 2026Configuring LLM-based agent systems involves choosing workflows, tools, token budgets, and prompts from a large combinatorial design space, and is typically handled today by fixed large templates or hand-tuned heuristics. This leads to brittle behavior and unnecessary compute, since the same cumbersome configuration is often applied to both easy and hard input queries. We formulate agent configuration as a query-wise decision problem and introduce ARC (Agentic Resource & Configuration learner), which learns a light-weight hierarchical policy using reinforcement learning to dynamically tailor these configurations. Across multiple benchmarks spanning reasoning and tool-augmented question answering, the learned policy consistently outperforms strong hand-designed and other baselines, achieving up to 25% higher task accuracy while also reducing token and runtime costs. These results demonstrate that learning per-query agent configurations is a powerful alternative to "one size fits all" designs.
Humanoid Factors: Design Principles for AI Humanoids in Human Worlds
Feb 10, 2026Human factors research has long focused on optimizing environments, tools, and systems to account for human performance. Yet, as humanoid robots begin to share our workplaces, homes, and public spaces, the design challenge expands. We must now consider not only factors for humans but also factors for humanoids, since both will coexist and interact within the same environments. Unlike conventional machines, humanoids introduce expectations of human-like behavior, communication, and social presence, which reshape usability, trust, and safety considerations. In this article, we introduce the concept of humanoid factors as a framework structured around four pillars - physical, cognitive, social, and ethical - that shape the development of humanoids to help them effectively coexist and collaborate with humans. This framework characterizes the overlap and divergence between human capabilities and those of general-purpose humanoids powered by AI foundation models. To demonstrate our framework's practical utility, we then apply the framework to evaluate a real-world humanoid control algorithm, illustrating how conventional task completion metrics in robotics overlook key human cognitive and interaction principles. We thus position humanoid factors as a foundational framework for designing, evaluating, and governing sustained human-humanoid coexistence.
Strategic Vantage Selection for Learning Viewpoint-Agnostic Manipulation Policies
Jun 13, 2025Vision-based manipulation has shown remarkable success, achieving promising performance across a range of tasks. However, these manipulation policies often fail to generalize beyond their training viewpoints, which is a persistent challenge in achieving perspective-agnostic manipulation, especially in settings where the camera is expected to move at runtime. Although collecting data from many angles seems a natural solution, such a naive approach is both resource-intensive and degrades manipulation policy performance due to excessive and unstructured visual diversity. This paper proposes Vantage, a framework that systematically identifies and integrates data from optimal perspectives to train robust, viewpoint-agnostic policies. By formulating viewpoint selection as a continuous optimization problem, we iteratively fine-tune policies on a few vantage points. Since we leverage Bayesian optimization to efficiently navigate the infinite space of potential camera configurations, we are able to balance exploration of novel views and exploitation of high-performing ones, thereby ensuring data collection from a minimal number of effective viewpoints. We empirically evaluate this framework on diverse standard manipulation tasks using multiple policy learning methods, demonstrating that fine-tuning with data from strategic camera placements yields substantial performance gains, achieving average improvements of up to 46.19% when compared to fixed, random, or heuristic-based strategies.
Consistency-based Abductive Reasoning over Perceptual Errors of Multiple Pre-trained Models in Novel Environments
May 25, 2025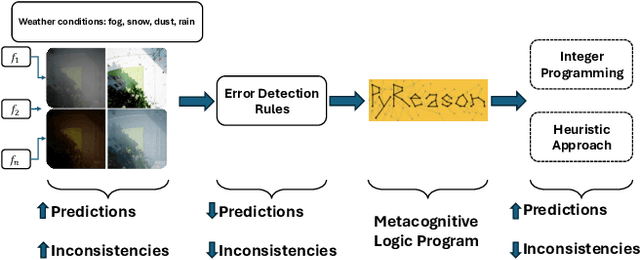
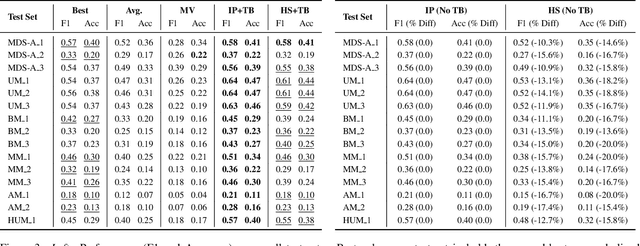
The deployment of pre-trained perception models in novel environments often leads to performance degradation due to distributional shifts. Although recent artificial intelligence approaches for metacognition use logical rules to characterize and filter model errors, improving precision often comes at the cost of reduced recall. This paper addresses the hypothesis that leveraging multiple pre-trained models can mitigate this recall reduction. We formulate the challenge of identifying and managing conflicting predictions from various models as a consistency-based abduction problem. The input predictions and the learned error detection rules derived from each model are encoded in a logic program. We then seek an abductive explanation--a subset of model predictions--that maximizes prediction coverage while ensuring the rate of logical inconsistencies (derived from domain constraints) remains below a specified threshold. We propose two algorithms for this knowledge representation task: an exact method based on Integer Programming (IP) and an efficient Heuristic Search (HS). Through extensive experiments on a simulated aerial imagery dataset featuring controlled, complex distributional shifts, we demonstrate that our abduction-based framework outperforms individual models and standard ensemble baselines, achieving, for instance, average relative improvements of approximately 13.6% in F1-score and 16.6% in accuracy across 15 diverse test datasets when compared to the best individual model. Our results validate the use of consistency-based abduction as an effective mechanism to robustly integrate knowledge from multiple imperfect reasoners in challenging, novel scenarios.
VLC Fusion: Vision-Language Conditioned Sensor Fusion for Robust Object Detection
May 19, 2025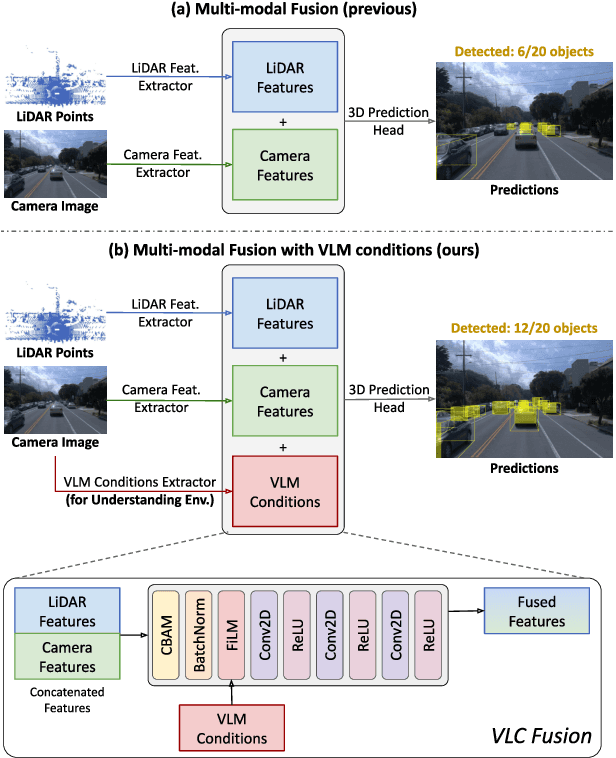
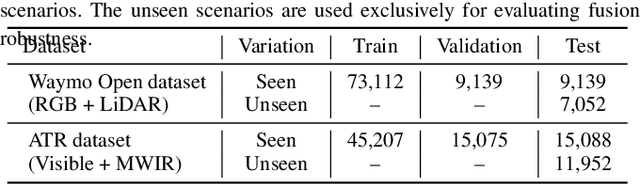

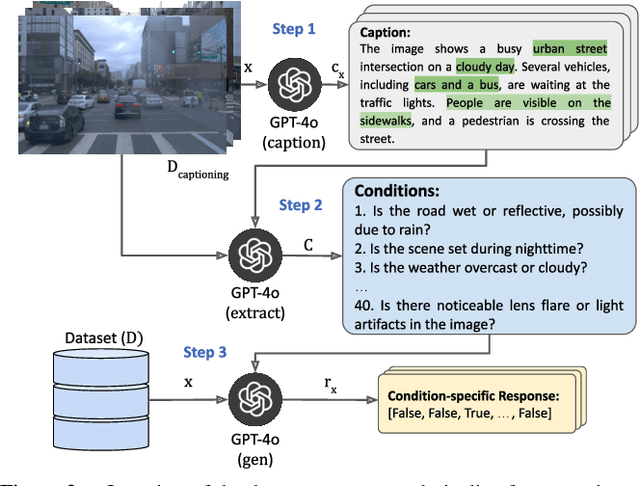
Although fusing multiple sensor modalities can enhance object detection performance, existing fusion approaches often overlook subtle variations in environmental conditions and sensor inputs. As a result, they struggle to adaptively weight each modality under such variations. To address this challenge, we introduce Vision-Language Conditioned Fusion (VLC Fusion), a novel fusion framework that leverages a Vision-Language Model (VLM) to condition the fusion process on nuanced environmental cues. By capturing high-level environmental context such as as darkness, rain, and camera blurring, the VLM guides the model to dynamically adjust modality weights based on the current scene. We evaluate VLC Fusion on real-world autonomous driving and military target detection datasets that include image, LIDAR, and mid-wave infrared modalities. Our experiments show that VLC Fusion consistently outperforms conventional fusion baselines, achieving improved detection accuracy in both seen and unseen scenarios.
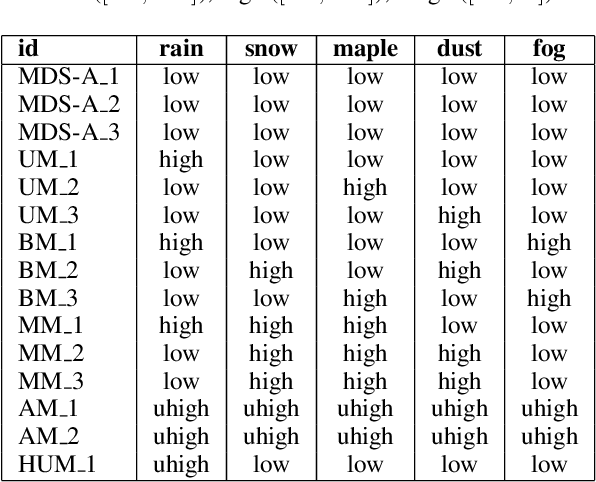
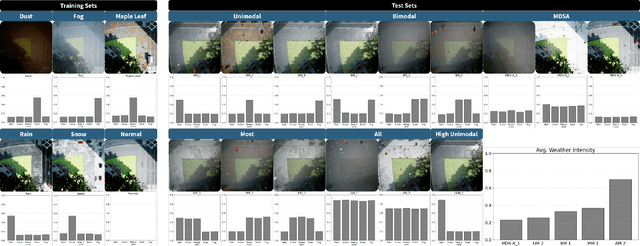
Multiple Distribution Shift -- Aerial (MDS-A): A Dataset for Test-Time Error Detection and Model Adaptation
Feb 18, 2025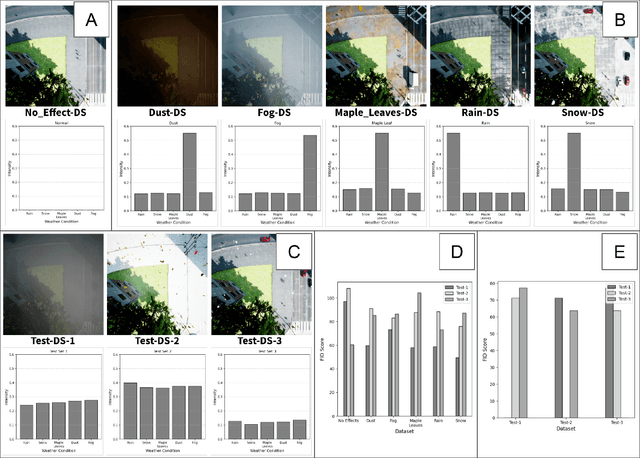
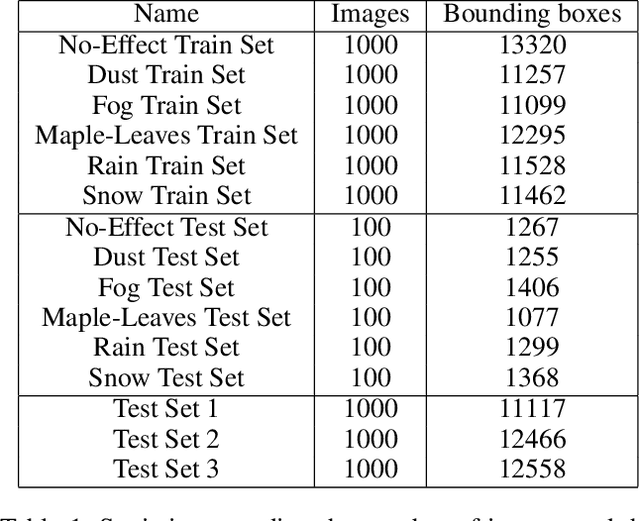

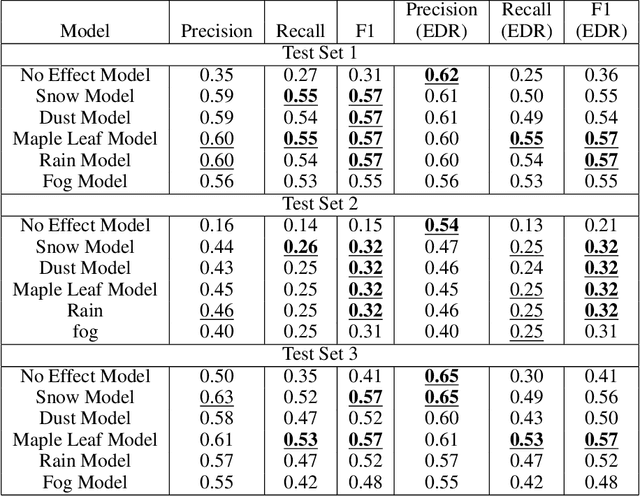
Machine learning models assume that training and test samples are drawn from the same distribution. As such, significant differences between training and test distributions often lead to degradations in performance. We introduce Multiple Distribution Shift -- Aerial (MDS-A) -- a collection of inter-related datasets of the same aerial domain that are perturbed in different ways to better characterize the effects of out-of-distribution performance. Specifically, MDS-A is a set of simulated aerial datasets collected under different weather conditions. We include six datasets under different simulated weather conditions along with six baseline object-detection models, as well as several test datasets that are a mix of weather conditions that we show have significant differences from the training data. In this paper, we present characterizations of MDS-A, provide performance results for the baseline machine learning models (on both their specific training datasets and the test data), as well as results of the baselines after employing recent knowledge-engineering error-detection techniques (EDR) thought to improve out-of-distribution performance. The dataset is available at https://lab-v2.github.io/mdsa-dataset-website.
MoSH: Modeling Multi-Objective Tradeoffs with Soft and Hard Bounds
Dec 09, 2024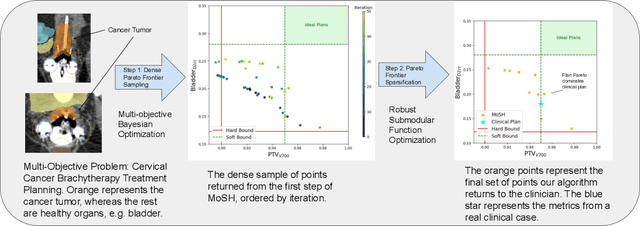
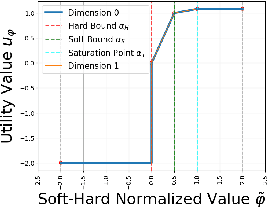
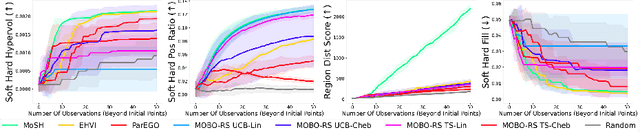
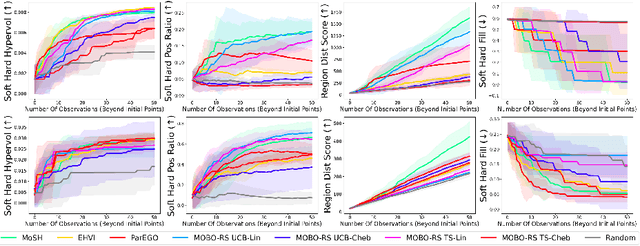
Countless science and engineering applications in multi-objective optimization (MOO) necessitate that decision-makers (DMs) select a Pareto-optimal solution which aligns with their preferences. Evaluating individual solutions is often expensive, necessitating cost-sensitive optimization techniques. Due to competing objectives, the space of trade-offs is also expansive -- thus, examining the full Pareto frontier may prove overwhelming to a DM. Such real-world settings generally have loosely-defined and context-specific desirable regions for each objective function that can aid in constraining the search over the Pareto frontier. We introduce a novel conceptual framework that operationalizes these priors using soft-hard functions, SHFs, which allow for the DM to intuitively impose soft and hard bounds on each objective -- which has been lacking in previous MOO frameworks. Leveraging a novel minimax formulation for Pareto frontier sampling, we propose a two-step process for obtaining a compact set of Pareto-optimal points which respect the user-defined soft and hard bounds: (1) densely sample the Pareto frontier using Bayesian optimization, and (2) sparsify the selected set to surface to the user, using robust submodular function optimization. We prove that (2) obtains the optimal compact Pareto-optimal set of points from (1). We further show that many practical problems fit within the SHF framework and provide extensive empirical validation on diverse domains, including brachytherapy, engineering design, and large language model personalization. Specifically, for brachytherapy, our approach returns a compact set of points with over 3% greater SHF-defined utility than the next best approach. Among the other diverse experiments, our approach consistently leads in utility, allowing the DM to reach >99% of their maximum possible desired utility within validation of 5 points.
RoboFail: Analyzing Failures in Robot Learning Policies
Dec 03, 2024Despite being trained on increasingly large datasets, robot models often overfit to specific environments or datasets. Consequently, they excel within their training distribution but face challenges in generalizing to novel or unforeseen scenarios. This paper presents a method to proactively identify failure mode probabilities in robot manipulation policies, providing insights into where these models are likely to falter. To this end, since exhaustively searching over a large space of failures is infeasible, we propose a deep reinforcement learning-based framework, RoboFail. It is designed to detect scenarios prone to failure and quantify their likelihood, thus offering a structured approach to anticipate failures. By identifying these high-risk states in advance, RoboFail enables researchers and engineers to better understand the robustness limits of robot policies, contributing to the development of safer and more adaptable robotic systems.