 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Implicit Large Language Model Alignment Objectives
Feb 17, 2026Large language model (LLM) alignment relies on complex reward signals that often obscure the specific behaviors being incentivized, creating critical risks of misalignment and reward hacking. Existing interpretation methods typically rely on pre-defined rubrics, risking the omission of "unknown unknowns", or fail to identify objectives that comprehensively cover and are causal to the model behavior. To address these limitations, we introduce Obj-Disco, a framework that automatically decomposes an alignment reward signal into a sparse, weighted combination of human-interpretable natural language objectives. Our approach utilizes an iterative greedy algorithm to analyze behavioral changes across training checkpoints, identifying and validating candidate objectives that best explain the residual reward signal. Extensive evaluations across diverse tasks, model sizes, and alignment algorithms demonstrate the framework's robustness. Experiments with popular open-source reward models show that the framework consistently captures > 90% of reward behavior, a finding further corroborated by human evaluation. Additionally, a case study on alignment with an open-source reward model reveals that Obj-Disco can successfully identify latent misaligned incentives that emerge alongside intended behaviors. Our work provides a crucial tool for uncovering the implicit objectives in LLM alignment, paving the way for more transparent and safer AI development.
ALMo: Interactive Aim-Limit-Defined, Multi-Objective System for Personalized High-Dose-Rate Brachytherapy Treatment Planning and Visualization for Cervical Cancer
Feb 14, 2026In complex clinical decision-making, clinicians must often track a variety of competing metrics defined by aim (ideal) and limit (strict) thresholds. Sifting through these high-dimensional tradeoffs to infer the optimal patient-specific strategy is cognitively demanding and historically prone to variability. In this paper, we address this challenge within the context of High-Dose-Rate (HDR) brachytherapy for cervical cancer, where planning requires strictly managing radiation hot spots while balancing tumor coverage against organ sparing. We present ALMo (Aim-Limit-defined Multi-Objective system), an interactive decision support system designed to infer and operationalize clinician intent. ALMo employs a novel optimization framework that minimizes manual input through automated parameter setup and enables flexible control over toxicity risks. Crucially, the system allows clinicians to navigate the Pareto surface of dosimetric tradeoffs by directly manipulating intuitive aim and limit values. In a retrospective evaluation of 25 clinical cases, ALMo generated treatment plans that consistently met or exceeded manual planning quality, with 65% of cases demonstrating dosimetric improvements. Furthermore, the system significantly enhanced efficiency, reducing average planning time to approximately 17 minutes, compared to the conventional 30-60 minutes. While validated in brachytherapy, ALMo demonstrates a generalized framework for streamlining interaction in multi-criteria clinical decision-making.
PluRel: Synthetic Data unlocks Scaling Laws for Relational Foundation Models
Feb 03, 2026Relational Foundation Models (RFMs) facilitate data-driven decision-making by learning from complex multi-table databases. However, the diverse relational databases needed to train such models are rarely public due to privacy constraints. While there are methods to generate synthetic tabular data of arbitrary size, incorporating schema structure and primary--foreign key connectivity for multi-table generation remains challenging. Here we introduce PluRel, a framework to synthesize multi-tabular relational databases from scratch. In a step-by-step fashion, PluRel models (1) schemas with directed graphs, (2) inter-table primary-foreign key connectivity with bipartite graphs, and, (3) feature distributions in tables via conditional causal mechanisms. The design space across these stages supports the synthesis of a wide range of diverse databases, while being computationally lightweight. Using PluRel, we observe for the first time that (1) RFM pretraining loss exhibits power-law scaling with the number of synthetic databases and total pretraining tokens, (2) scaling the number of synthetic databases improves generalization to real databases, and (3) synthetic pretraining yields strong base models for continued pretraining on real databases. Overall, our framework and results position synthetic data scaling as a promising paradigm for RFMs.
Reinforcement Learning via Self-Distillation
Jan 28, 2026Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
Learning to Discover at Test Time
Jan 22, 2026How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement learning at test time, so the LLM can continue to train, but now with experience specific to the test problem. This form of continual learning is quite special, because its goal is to produce one great solution rather than many good ones on average, and to solve this very problem rather than generalize to other problems. Therefore, our learning objective and search subroutine are designed to prioritize the most promising solutions. We call this method Test-Time Training to Discover (TTT-Discover). Following prior work, we focus on problems with continuous rewards. We report results for every problem we attempted, across mathematics, GPU kernel engineering, algorithm design, and biology. TTT-Discover sets the new state of the art in almost all of them: (i) Erdős' minimum overlap problem and an autocorrelation inequality; (ii) a GPUMode kernel competition (up to $2\times$ faster than prior art); (iii) past AtCoder algorithm competitions; and (iv) denoising problem in single-cell analysis. Our solutions are reviewed by experts or the organizers. All our results are achieved with an open model, OpenAI gpt-oss-120b, and can be reproduced with our publicly available code, in contrast to previous best results that required closed frontier models. Our test-time training runs are performed using Tinker, an API by Thinking Machines, with a cost of only a few hundred dollars per problem.
End-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
DeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Aug 27, 2025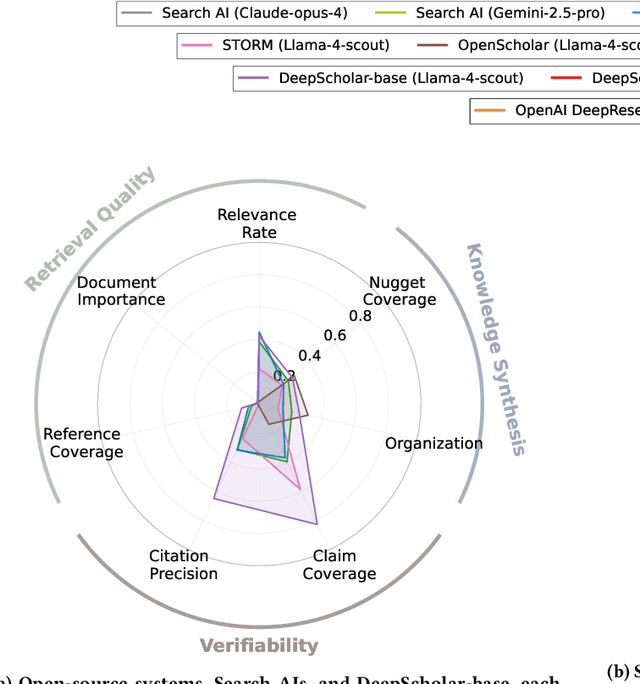
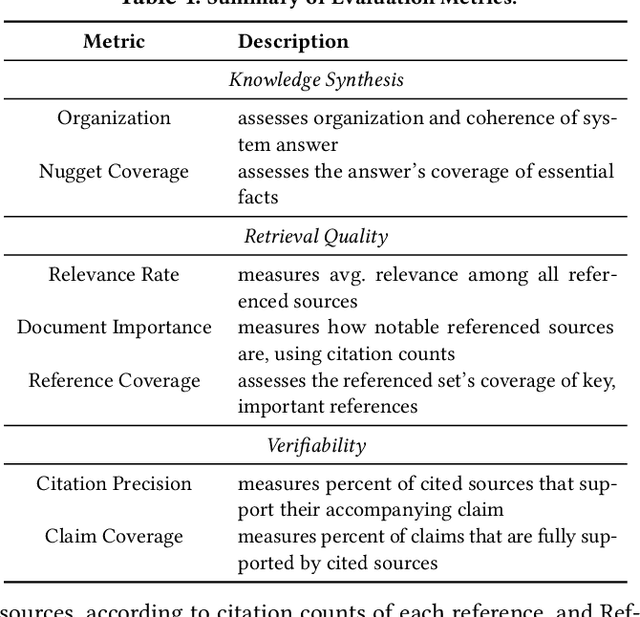
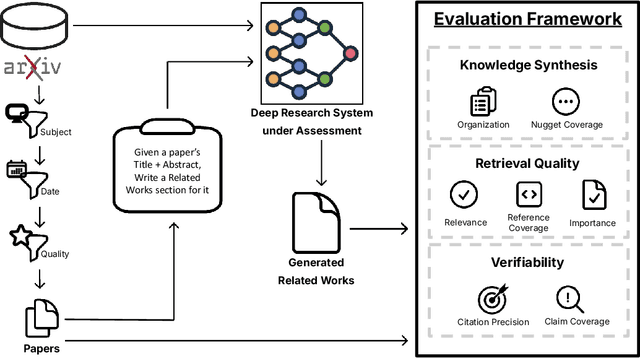
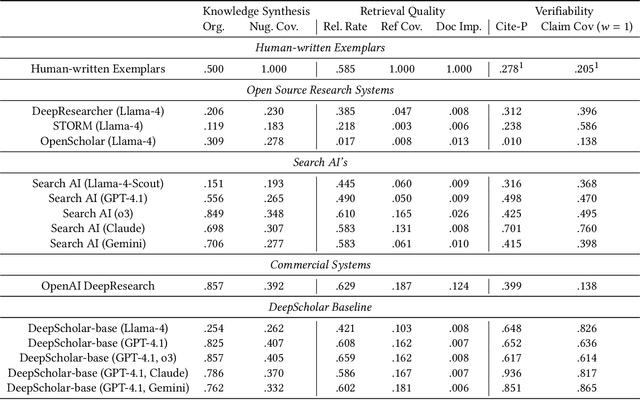
The ability to research and synthesize knowledge is central to human expertise and progress. An emerging class of systems promises these exciting capabilities through generative research synthesis, performing retrieval over the live web and synthesizing discovered sources into long-form, cited summaries. However, evaluating such systems remains an open challenge: existing question-answering benchmarks focus on short-form factual responses, while expert-curated datasets risk staleness and data contamination. Both fail to capture the complexity and evolving nature of real research synthesis tasks. In this work, we introduce DeepScholar-bench, a live benchmark and holistic, automated evaluation framework designed to evaluate generative research synthesis. DeepScholar-bench draws queries from recent, high-quality ArXiv papers and focuses on a real research synthesis task: generating the related work sections of a paper by retrieving, synthesizing, and citing prior research. Our evaluation framework holistically assesses performance across three key dimensions, knowledge synthesis, retrieval quality, and verifiability. We also develop DeepScholar-base, a reference pipeline implemented efficiently using the LOTUS API. Using the DeepScholar-bench framework, we perform a systematic evaluation of prior open-source systems, search AI's, OpenAI's DeepResearch, and DeepScholar-base. We find that DeepScholar-base establishes a strong baseline, attaining competitive or higher performance than each other method. We also find that DeepScholar-bench remains far from saturated, with no system exceeding a score of $19\%$ across all metrics. These results underscore the difficulty of DeepScholar-bench, as well as its importance for progress towards AI systems capable of generative research synthesis. We make our code available at https://github.com/guestrin-lab/deepscholar-bench.
metaTextGrad: Automatically optimizing language model optimizers
May 24, 2025Large language models (LLMs) are increasingly used in learning algorithms, evaluations, and optimization tasks. Recent studies have shown that using LLM-based optimizers to automatically optimize model prompts, demonstrations, predictions themselves, or other components can significantly enhance the performance of AI systems, as demonstrated by frameworks such as DSPy and TextGrad. However, optimizers built on language models themselves are usually designed by humans with manual design choices; optimizers themselves are not optimized. Moreover, these optimizers are general purpose by design, to be useful to a broad audience, and are not tailored for specific tasks. To address these challenges, we propose metaTextGrad, which focuses on designing a meta-optimizer to further enhance existing optimizers and align them to be good optimizers for a given task. Our approach consists of two key components: a meta prompt optimizer and a meta structure optimizer. The combination of these two significantly improves performance across multiple benchmarks, achieving an average absolute performance improvement of up to 6% compared to the best baseline.
Societal Impacts Research Requires Benchmarks for Creative Composition Tasks
Apr 09, 2025Foundation models that are capable of automating cognitive tasks represent a pivotal technological shift, yet their societal implications remain unclear. These systems promise exciting advances, yet they also risk flooding our information ecosystem with formulaic, homogeneous, and potentially misleading synthetic content. Developing benchmarks grounded in real use cases where these risks are most significant is therefore critical. Through a thematic analysis using 2 million language model user prompts, we identify creative composition tasks as a prevalent usage category where users seek help with personal tasks that require everyday creativity. Our fine-grained analysis identifies mismatches between current benchmarks and usage patterns among these tasks. Crucially, we argue that the same use cases that currently lack thorough evaluations can lead to negative downstream impacts. This position paper argues that benchmarks focused on creative composition tasks is a necessary step towards understanding the societal harms of AI-generated content. We call for greater transparency in usage patterns to inform the development of new benchmarks that can effectively measure both the progress and the impacts of models with creative capabilities.
One-Minute Video Generation with Test-Time Training
Apr 07, 2025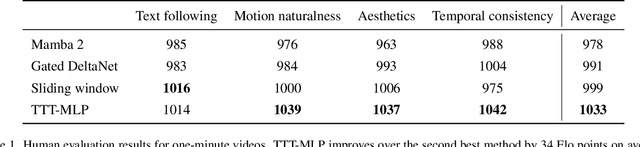
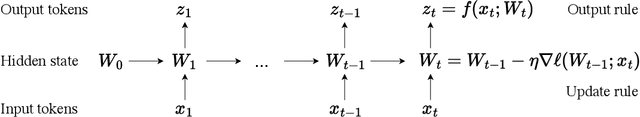
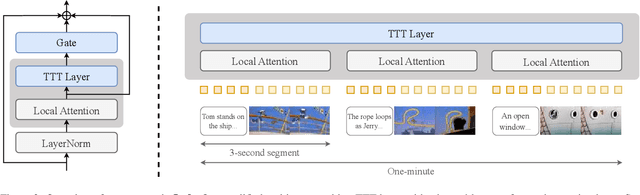
Transformers today still struggle to generate one-minute videos because self-attention layers are inefficient for long context. Alternatives such as Mamba layers struggle with complex multi-scene stories because their hidden states are less expressive. We experiment with Test-Time Training (TTT) layers, whose hidden states themselves can be neural networks, therefore more expressive. Adding TTT layers into a pre-trained Transformer enables it to generate one-minute videos from text storyboards. For proof of concept, we curate a dataset based on Tom and Jerry cartoons. Compared to baselines such as Mamba~2, Gated DeltaNet, and sliding-window attention layers, TTT layers generate much more coherent videos that tell complex stories, leading by 34 Elo points in a human evaluation of 100 videos per method. Although promising, results still contain artifacts, likely due to the limited capability of the pre-trained 5B model. The efficiency of our implementation can also be improved. We have only experimented with one-minute videos due to resource constraints, but the approach can be extended to longer videos and more complex stories. Sample videos, code and annotations are available at: https://test-time-training.github.io/video-dit