 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Demystifying Data-Driven Probabilistic Medium-Range Weather Forecasting
Jan 26, 2026The recent revolution in data-driven methods for weather forecasting has lead to a fragmented landscape of complex, bespoke architectures and training strategies, obscuring the fundamental drivers of forecast accuracy. Here, we demonstrate that state-of-the-art probabilistic skill requires neither intricate architectural constraints nor specialized training heuristics. We introduce a scalable framework for learning multi-scale atmospheric dynamics by combining a directly downsampled latent space with a history-conditioned local projector that resolves high-resolution physics. We find that our framework design is robust to the choice of probabilistic estimator, seamlessly supporting stochastic interpolants, diffusion models, and CRPS-based ensemble training. Validated against the Integrated Forecasting System and the deep learning probabilistic model GenCast, our framework achieves statistically significant improvements on most of the variables. These results suggest scaling a general-purpose model is sufficient for state-of-the-art medium-range prediction, eliminating the need for tailored training recipes and proving effective across the full spectrum of probabilistic frameworks.
C-RADIOv4 (Tech Report)
Jan 24, 2026By leveraging multi-teacher distillation, agglomerative vision backbones provide a unified student model that retains and improves the distinct capabilities of multiple teachers. In this tech report, we describe the most recent release of the C-RADIO family of models, C-RADIOv4, which builds upon AM-RADIO/RADIOv2.5 in design, offering strong improvements on key downstream tasks at the same computational complexity. We release -SO400M (412M params), and -H (631M) model variants, both trained with an updated set of teachers: SigLIP2, DINOv3, and SAM3. In addition to improvements on core metrics and new capabilities from imitating SAM3, the C-RADIOv4 model family further improves any-resolution support, brings back the ViTDet option for drastically enhanced efficiency at high-resolution, and comes with a permissive license.
Learning to Discover at Test Time
Jan 22, 2026How can we use AI to discover a new state of the art for a scientific problem? Prior work in test-time scaling, such as AlphaEvolve, performs search by prompting a frozen LLM. We perform reinforcement learning at test time, so the LLM can continue to train, but now with experience specific to the test problem. This form of continual learning is quite special, because its goal is to produce one great solution rather than many good ones on average, and to solve this very problem rather than generalize to other problems. Therefore, our learning objective and search subroutine are designed to prioritize the most promising solutions. We call this method Test-Time Training to Discover (TTT-Discover). Following prior work, we focus on problems with continuous rewards. We report results for every problem we attempted, across mathematics, GPU kernel engineering, algorithm design, and biology. TTT-Discover sets the new state of the art in almost all of them: (i) Erdős' minimum overlap problem and an autocorrelation inequality; (ii) a GPUMode kernel competition (up to $2\times$ faster than prior art); (iii) past AtCoder algorithm competitions; and (iv) denoising problem in single-cell analysis. Our solutions are reviewed by experts or the organizers. All our results are achieved with an open model, OpenAI gpt-oss-120b, and can be reproduced with our publicly available code, in contrast to previous best results that required closed frontier models. Our test-time training runs are performed using Tinker, an API by Thinking Machines, with a cost of only a few hundred dollars per problem.
Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Jan 14, 2026Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments. While recent studies on reasoning VLAs show that explicit chain-of-thought (CoT) can improve generalization, they suffer from high inference latency due to lengthy reasoning traces. We propose Fast-ThinkAct, an efficient reasoning framework that achieves compact yet performant planning through verbalizable latent reasoning. Fast-ThinkAct learns to reason efficiently with latent CoTs by distilling from a teacher, driven by a preference-guided objective to align manipulation trajectories that transfers both linguistic and visual planning capabilities for embodied control. This enables reasoning-enhanced policy learning that effectively connects compact reasoning to action execution. Extensive experiments across diverse embodied manipulation and reasoning benchmarks demonstrate that Fast-ThinkAct achieves strong performance with up to 89.3\% reduced inference latency over state-of-the-art reasoning VLAs, while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery.
NitroGen: An Open Foundation Model for Generalist Gaming Agents
Jan 04, 2026We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025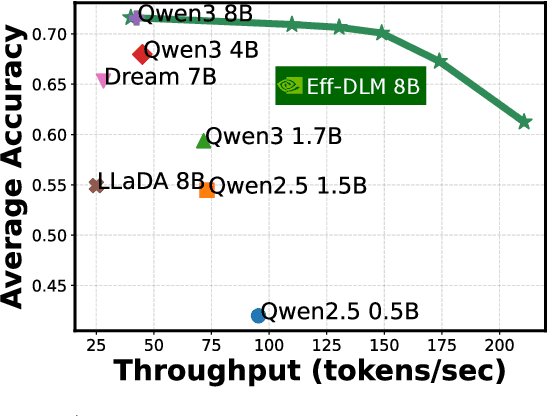
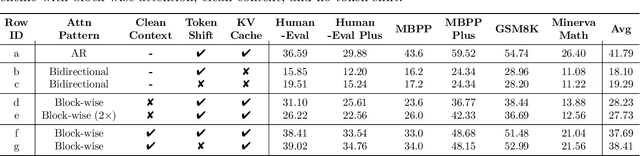
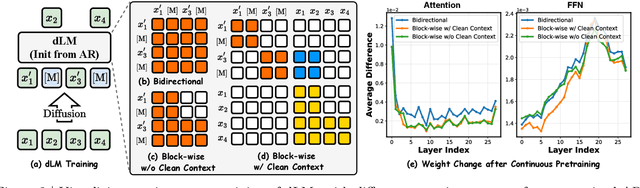
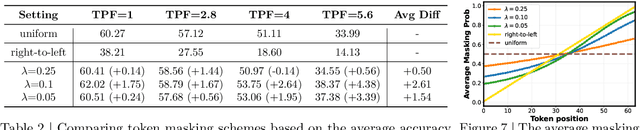
Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
TiDAR: Think in Diffusion, Talk in Autoregression
Nov 12, 2025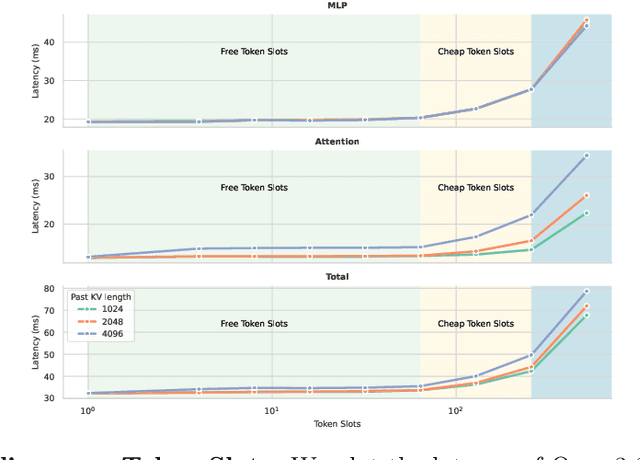

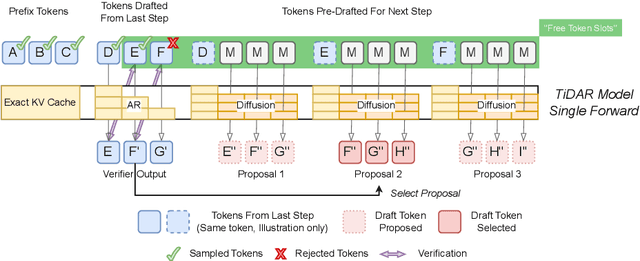
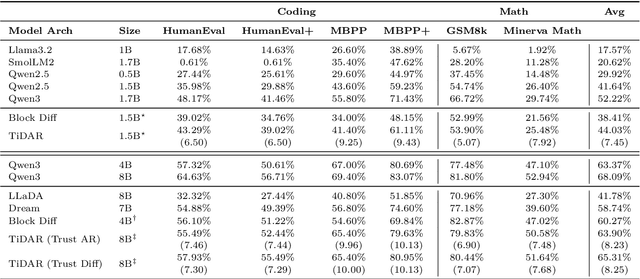
Diffusion language models hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a fundamental question: can we achieve a synergy with high throughput, higher GPU utilization, and AR level quality? Existing methods fail to effectively balance these two aspects, either prioritizing AR using a weaker model for sequential drafting (speculative decoding), leading to lower drafting efficiency, or using some form of left-to-right (AR-like) decoding logic for diffusion, which still suffers from quality degradation and forfeits its potential parallelizability. We introduce TiDAR, a sequence-level hybrid architecture that drafts tokens (Thinking) in Diffusion and samples final outputs (Talking) AutoRegressively - all within a single forward pass using specially designed structured attention masks. This design exploits the free GPU compute density, achieving a strong balance between drafting and verification capacity. Moreover, TiDAR is designed to be serving-friendly (low overhead) as a standalone model. We extensively evaluate TiDAR against AR models, speculative decoding, and diffusion variants across generative and likelihood tasks at 1.5B and 8B scales. Thanks to the parallel drafting and sampling as well as exact KV cache support, TiDAR outperforms speculative decoding in measured throughput and surpasses diffusion models like Dream and Llada in both efficiency and quality. Most notably, TiDAR is the first architecture to close the quality gap with AR models while delivering 4.71x to 5.91x more tokens per second.