 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
Play to Generalize: Learning to Reason Through Game Play
Jun 09, 2025Developing generalizable reasoning capabilities in multimodal large language models (MLLMs) remains challenging. Motivated by cognitive science literature suggesting that gameplay promotes transferable cognitive skills, we propose a novel post-training paradigm, Visual Game Learning, or ViGaL, where MLLMs develop out-of-domain generalization of multimodal reasoning through playing arcade-like games. Specifically, we show that post-training a 7B-parameter MLLM via reinforcement learning (RL) on simple arcade-like games, e.g. Snake, significantly enhances its downstream performance on multimodal math benchmarks like MathVista, and on multi-discipline questions like MMMU, without seeing any worked solutions, equations, or diagrams during RL, suggesting the capture of transferable reasoning skills. Remarkably, our model outperforms specialist models tuned on multimodal reasoning data in multimodal reasoning benchmarks, while preserving the base model's performance on general visual benchmarks, a challenge where specialist models often fall short. Our findings suggest a new post-training paradigm: synthetic, rule-based games can serve as controllable and scalable pre-text tasks that unlock generalizable multimodal reasoning abilities in MLLMs.
DriveSuprim: Towards Precise Trajectory Selection for End-to-End Planning
Jun 07, 2025In complex driving environments, autonomous vehicles must navigate safely. Relying on a single predicted path, as in regression-based approaches, usually does not explicitly assess the safety of the predicted trajectory. Selection-based methods address this by generating and scoring multiple trajectory candidates and predicting the safety score for each, but face optimization challenges in precisely selecting the best option from thousands of possibilities and distinguishing subtle but safety-critical differences, especially in rare or underrepresented scenarios. We propose DriveSuprim to overcome these challenges and advance the selection-based paradigm through a coarse-to-fine paradigm for progressive candidate filtering, a rotation-based augmentation method to improve robustness in out-of-distribution scenarios, and a self-distillation framework to stabilize training. DriveSuprim achieves state-of-the-art performance, reaching 93.5% PDMS in NAVSIM v1 and 87.1% EPDMS in NAVSIM v2 without extra data, demonstrating superior safetycritical capabilities, including collision avoidance and compliance with rules, while maintaining high trajectory quality in various driving scenarios.
Generalized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025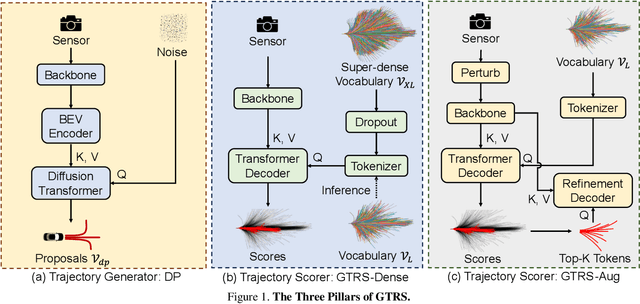

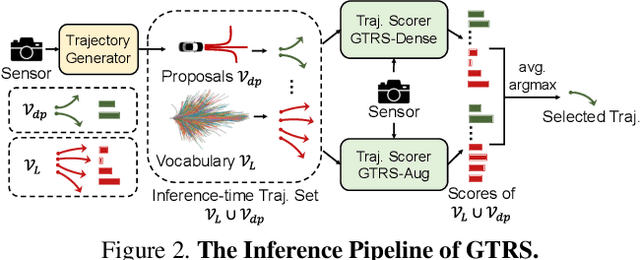
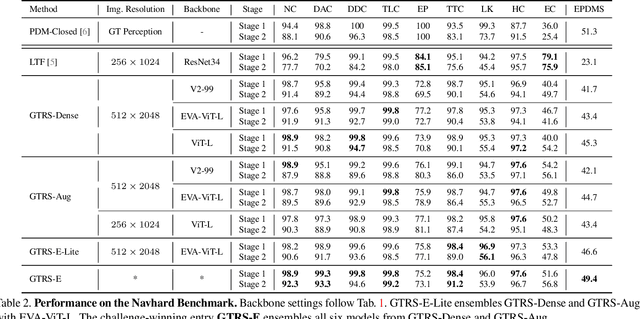
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025
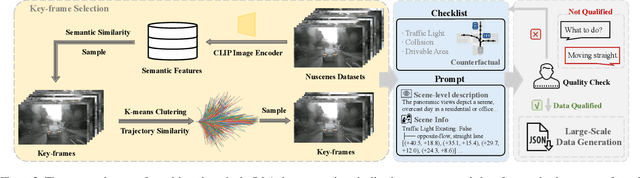
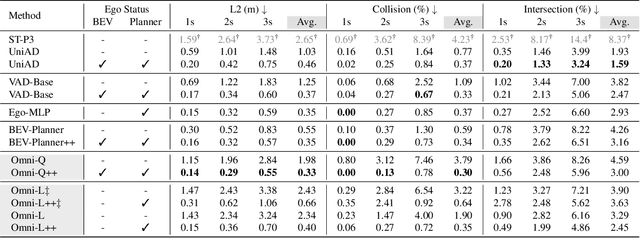
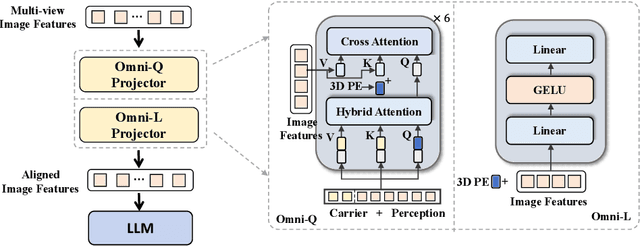
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
MDP: Multidimensional Vision Model Pruning with Latency Constraint
Apr 02, 2025Current structural pruning methods face two significant limitations: (i) they often limit pruning to finer-grained levels like channels, making aggressive parameter reduction challenging, and (ii) they focus heavily on parameter and FLOP reduction, with existing latency-aware methods frequently relying on simplistic, suboptimal linear models that fail to generalize well to transformers, where multiple interacting dimensions impact latency. In this paper, we address both limitations by introducing Multi-Dimensional Pruning (MDP), a novel paradigm that jointly optimizes across a variety of pruning granularities-including channels, query, key, heads, embeddings, and blocks. MDP employs an advanced latency modeling technique to accurately capture latency variations across all prunable dimensions, achieving an optimal balance between latency and accuracy. By reformulating pruning as a Mixed-Integer Nonlinear Program (MINLP), MDP efficiently identifies the optimal pruned structure across all prunable dimensions while respecting latency constraints. This versatile framework supports both CNNs and transformers. Extensive experiments demonstrate that MDP significantly outperforms previous methods, especially at high pruning ratios. On ImageNet, MDP achieves a 28% speed increase with a +1.4 Top-1 accuracy improvement over prior work like HALP for ResNet50 pruning. Against the latest transformer pruning method, Isomorphic, MDP delivers an additional 37% acceleration with a +0.7 Top-1 accuracy improvement.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Hydra-MDP++: Advancing End-to-End Driving via Expert-Guided Hydra-Distillation
Mar 17, 2025Hydra-MDP++ introduces a novel teacher-student knowledge distillation framework with a multi-head decoder that learns from human demonstrations and rule-based experts. Using a lightweight ResNet-34 network without complex components, the framework incorporates expanded evaluation metrics, including traffic light compliance (TL), lane-keeping ability (LK), and extended comfort (EC) to address unsafe behaviors not captured by traditional NAVSIM-derived teachers. Like other end-to-end autonomous driving approaches, \hydra processes raw images directly without relying on privileged perception signals. Hydra-MDP++ achieves state-of-the-art performance by integrating these components with a 91.0% drive score on NAVSIM through scaling to a V2-99 image encoder, demonstrating its effectiveness in handling diverse driving scenarios while maintaining computational efficiency.
Hydra-NeXt: Robust Closed-Loop Driving with Open-Loop Training
Mar 15, 2025End-to-end autonomous driving research currently faces a critical challenge in bridging the gap between open-loop training and closed-loop deployment. Current approaches are trained to predict trajectories in an open-loop environment, which struggle with quick reactions to other agents in closed-loop environments and risk generating kinematically infeasible plans due to the gap between open-loop training and closed-loop driving. In this paper, we introduce Hydra-NeXt, a novel multi-branch planning framework that unifies trajectory prediction, control prediction, and a trajectory refinement network in one model. Unlike current open-loop trajectory prediction models that only handle general-case planning, Hydra-NeXt further utilizes a control decoder to focus on short-term actions, which enables faster responses to dynamic situations and reactive agents. Moreover, we propose the Trajectory Refinement module to augment and refine the planning decisions by effectively adhering to kinematic constraints in closed-loop environments. This unified approach bridges the gap between open-loop training and closed-loop driving, demonstrating superior performance of 65.89 Driving Score (DS) and 48.20% Success Rate (SR) on the Bench2Drive dataset without relying on external experts for data collection. Hydra-NeXt surpasses the previous state-of-the-art by 22.98 DS and 17.49 SR, marking a significant advancement in autonomous driving. Code will be available at https://github.com/woxihuanjiangguo/Hydra-NeXt.
Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
Mar 14, 2025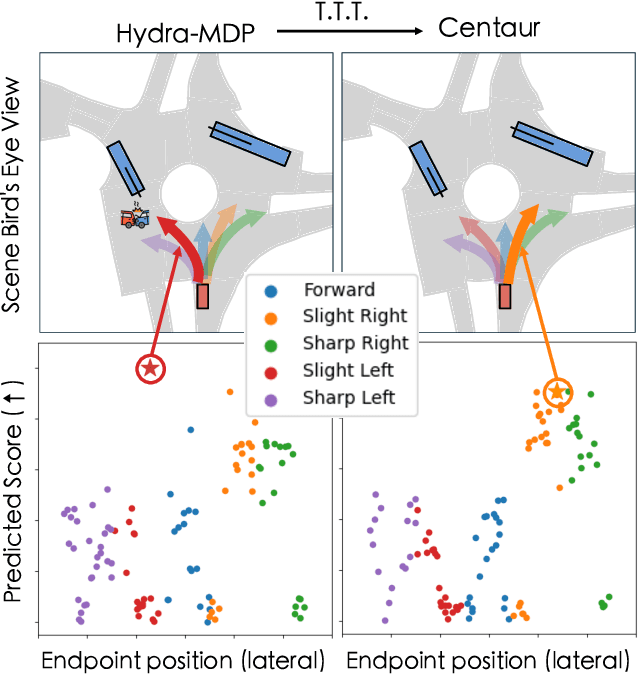



How can we rely on an end-to-end autonomous vehicle's complex decision-making system during deployment? One common solution is to have a ``fallback layer'' that checks the planned trajectory for rule violations and replaces it with a pre-defined safe action if necessary. Another approach involves adjusting the planner's decisions to minimize a pre-defined ``cost function'' using additional system predictions such as road layouts and detected obstacles. However, these pre-programmed rules or cost functions cannot learn and improve with new training data, often resulting in overly conservative behaviors. In this work, we propose Centaur (Cluster Entropy for Test-time trAining using Uncertainty) which updates a planner's behavior via test-time training, without relying on hand-engineered rules or cost functions. Instead, we measure and minimize the uncertainty in the planner's decisions. For this, we develop a novel uncertainty measure, called Cluster Entropy, which is simple, interpretable, and compatible with state-of-the-art planning algorithms. Using data collected at prior test-time time-steps, we perform an update to the model's parameters using a gradient that minimizes the Cluster Entropy. With only this sole gradient update prior to inference, Centaur exhibits significant improvements, ranking first on the navtest leaderboard with notable gains in safety-critical metrics such as time to collision. To provide detailed insights on a per-scenario basis, we also introduce navsafe, a challenging new benchmark, which highlights previously undiscovered failure modes of driving models.