 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-Aware Data Selection for End-to-End Autonomous Driving Systems
Apr 09, 2026Large-scale deep learning models for physical AI applications depend on diverse training data collection efforts. These models and correspondingly, the training data, must address different evaluation criteria necessary for the models to be deployable in real-world environments. Data selection policies can guide the development of the training set, but current frameworks do not account for the ambiguity in how data points affect different metrics. In this work, we propose Mixture Optimization via Scaling-Aware Iterative Collection (MOSAIC), a general data selection framework that operates by: (i) partitioning the dataset into domains; (ii) fitting neural scaling laws from each data domain to the evaluation metrics; and (iii) optimizing a data mixture by iteratively adding data from domains that maximize the change in metrics. We apply MOSAIC to autonomous driving (AD), where an End-to-End (E2E) planner model is evaluated on the Extended Predictive Driver Model Score (EPDMS), an aggregate of driving rule compliance metrics. Here, MOSAIC outperforms a diverse set of baselines on EPDMS with up to 80\% less data.
Generalized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025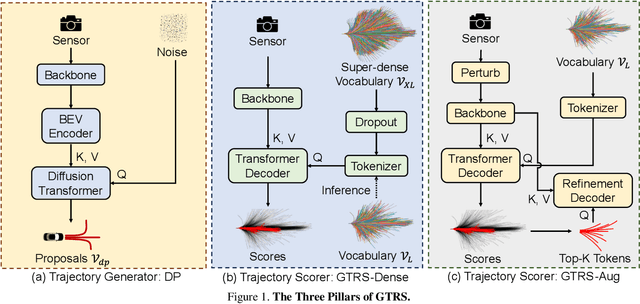

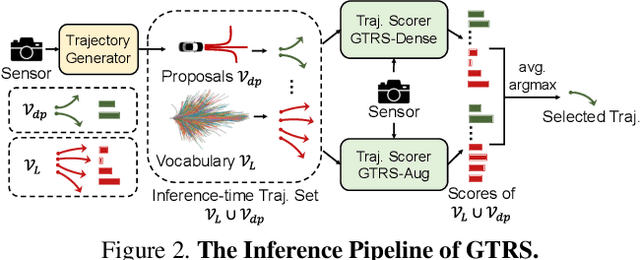
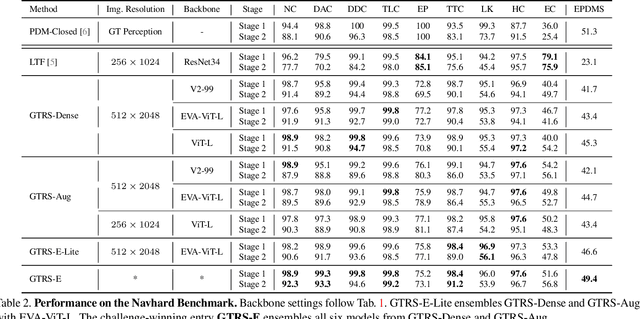
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
MDP: Multidimensional Vision Model Pruning with Latency Constraint
Apr 02, 2025Current structural pruning methods face two significant limitations: (i) they often limit pruning to finer-grained levels like channels, making aggressive parameter reduction challenging, and (ii) they focus heavily on parameter and FLOP reduction, with existing latency-aware methods frequently relying on simplistic, suboptimal linear models that fail to generalize well to transformers, where multiple interacting dimensions impact latency. In this paper, we address both limitations by introducing Multi-Dimensional Pruning (MDP), a novel paradigm that jointly optimizes across a variety of pruning granularities-including channels, query, key, heads, embeddings, and blocks. MDP employs an advanced latency modeling technique to accurately capture latency variations across all prunable dimensions, achieving an optimal balance between latency and accuracy. By reformulating pruning as a Mixed-Integer Nonlinear Program (MINLP), MDP efficiently identifies the optimal pruned structure across all prunable dimensions while respecting latency constraints. This versatile framework supports both CNNs and transformers. Extensive experiments demonstrate that MDP significantly outperforms previous methods, especially at high pruning ratios. On ImageNet, MDP achieves a 28% speed increase with a +1.4 Top-1 accuracy improvement over prior work like HALP for ResNet50 pruning. Against the latest transformer pruning method, Isomorphic, MDP delivers an additional 37% acceleration with a +0.7 Top-1 accuracy improvement.
Advancing Weight and Channel Sparsification with Enhanced Saliency
Feb 05, 2025



Pruning aims to accelerate and compress models by removing redundant parameters, identified by specifically designed importance scores which are usually imperfect. This removal is irreversible, often leading to subpar performance in pruned models. Dynamic sparse training, while attempting to adjust sparse structures during training for continual reassessment and refinement, has several limitations including criterion inconsistency between pruning and growth, unsuitability for structured sparsity, and short-sighted growth strategies. Our paper introduces an efficient, innovative paradigm to enhance a given importance criterion for either unstructured or structured sparsity. Our method separates the model into an active structure for exploitation and an exploration space for potential updates. During exploitation, we optimize the active structure, whereas in exploration, we reevaluate and reintegrate parameters from the exploration space through a pruning and growing step consistently guided by the same given importance criterion. To prepare for exploration, we briefly "reactivate" all parameters in the exploration space and train them for a few iterations while keeping the active part frozen, offering a preview of the potential performance gains from reintegrating these parameters. We show on various datasets and configurations that existing importance criterion even simple as magnitude can be enhanced with ours to achieve state-of-the-art performance and training cost reductions. Notably, on ImageNet with ResNet50, ours achieves an +1.3 increase in Top-1 accuracy over prior art at 90% ERK sparsity. Compared with the SOTA latency pruning method HALP, we reduced its training cost by over 70% while attaining a faster and more accurate pruned model.
SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
Sep 20, 2024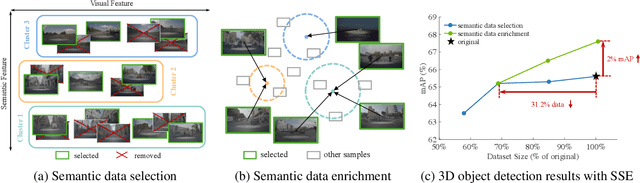


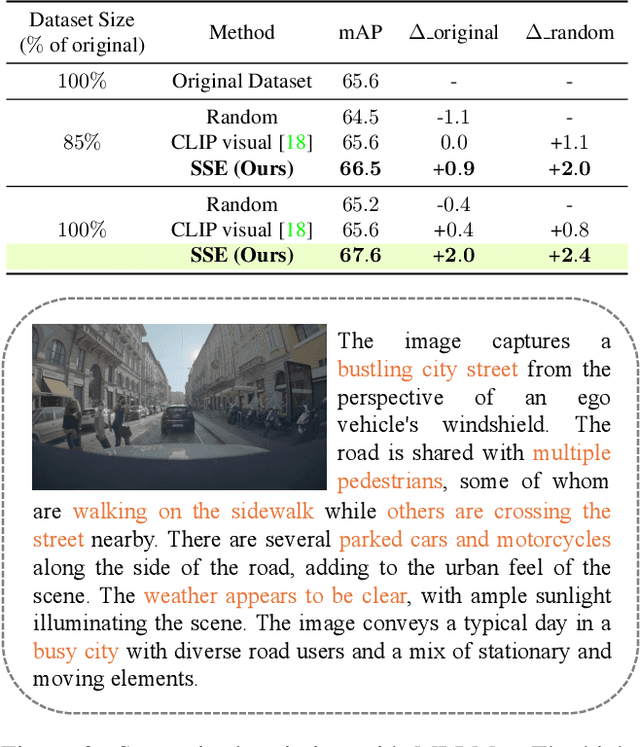
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.
Exploring Camera Encoder Designs for Autonomous Driving Perception
Jul 09, 2024The cornerstone of autonomous vehicles (AV) is a solid perception system, where camera encoders play a crucial role. Existing works usually leverage pre-trained Convolutional Neural Networks (CNN) or Vision Transformers (ViTs) designed for general vision tasks, such as image classification, segmentation, and 2D detection. Although those well-known architectures have achieved state-of-the-art accuracy in AV-related tasks, e.g., 3D Object Detection, there remains significant potential for improvement in network design due to the nuanced complexities of industrial-level AV dataset. Moreover, existing public AV benchmarks usually contain insufficient data, which might lead to inaccurate evaluation of those architectures.To reveal the AV-specific model insights, we start from a standard general-purpose encoder, ConvNeXt and progressively transform the design. We adjust different design parameters including width and depth of the model, stage compute ratio, attention mechanisms, and input resolution, supported by systematic analysis to each modifications. This customization yields an architecture optimized for AV camera encoder achieving 8.79% mAP improvement over the baseline. We believe our effort could become a sweet cookbook of image encoders for AV and pave the way to the next-level drive system.
Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Jun 17, 2024As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
Step Out and Seek Around: On Warm-Start Training with Incremental Data
Jun 06, 2024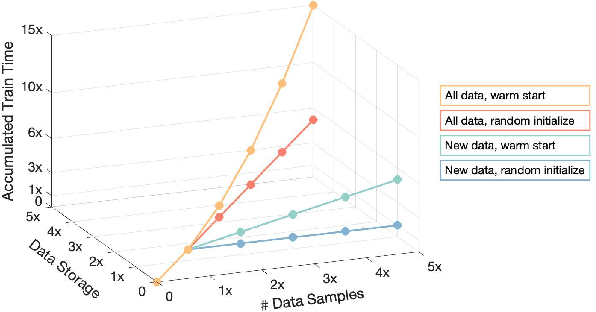
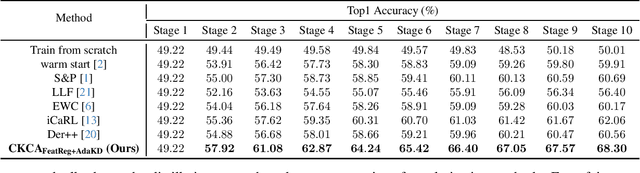
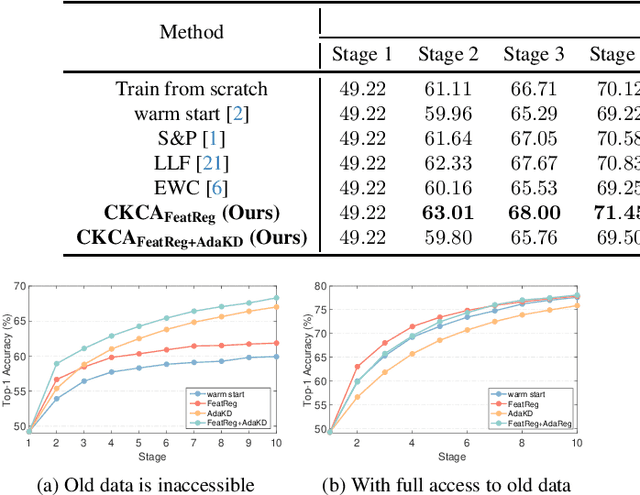

Data often arrives in sequence over time in real-world deep learning applications such as autonomous driving. When new training data is available, training the model from scratch undermines the benefit of leveraging the learned knowledge, leading to significant training costs. Warm-starting from a previously trained checkpoint is the most intuitive way to retain knowledge and advance learning. However, existing literature suggests that this warm-starting degrades generalization. In this paper, we advocate for warm-starting but stepping out of the previous converging point, thus allowing a better adaptation to new data without compromising previous knowledge. We propose Knowledge Consolidation and Acquisition (CKCA), a continuous model improvement algorithm with two novel components. First, a novel feature regularization (FeatReg) to retain and refine knowledge from existing checkpoints; Second, we propose adaptive knowledge distillation (AdaKD), a novel approach to forget mitigation and knowledge transfer. We tested our method on ImageNet using multiple splits of the training data. Our approach achieves up to $8.39\%$ higher top1 accuracy than the vanilla warm-starting and consistently outperforms the prior art with a large margin.
Adaptive Sharpness-Aware Pruning for Robust Sparse Networks
Jun 25, 2023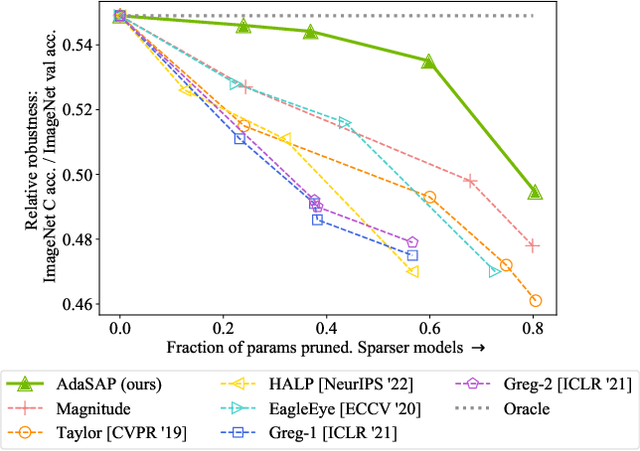
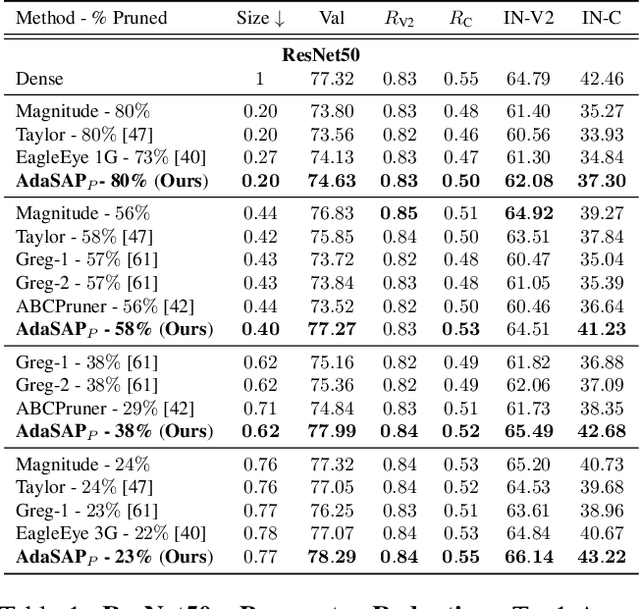

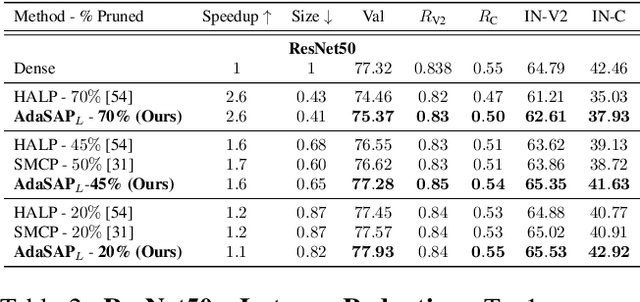
Robustness and compactness are two essential components of deep learning models that are deployed in the real world. The seemingly conflicting aims of (i) generalization across domains as in robustness, and (ii) specificity to one domain as in compression, are why the overall design goal of achieving robust compact models, despite being highly important, is still a challenging open problem. We introduce Adaptive Sharpness-Aware Pruning, or AdaSAP, a method that yields robust sparse networks. The central tenet of our approach is to optimize the loss landscape so that the model is primed for pruning via adaptive weight perturbation, and is also consistently regularized toward flatter regions for improved robustness. This unifies both goals through the lens of network sharpness. AdaSAP achieves strong performance in a comprehensive set of experiments. For classification on ImageNet and object detection on Pascal VOC datasets, AdaSAP improves the robust accuracy of pruned models by +6% on ImageNet C, +4% on ImageNet V2, and +4% on corrupted VOC datasets, over a wide range of compression ratios, saliency criteria, and network architectures, outperforming recent pruning art by large margins.
Soft Masking for Cost-Constrained Channel Pruning
Nov 04, 2022Structured channel pruning has been shown to significantly accelerate inference time for convolution neural networks (CNNs) on modern hardware, with a relatively minor loss of network accuracy. Recent works permanently zero these channels during training, which we observe to significantly hamper final accuracy, particularly as the fraction of the network being pruned increases. We propose Soft Masking for cost-constrained Channel Pruning (SMCP) to allow pruned channels to adaptively return to the network while simultaneously pruning towards a target cost constraint. By adding a soft mask re-parameterization of the weights and channel pruning from the perspective of removing input channels, we allow gradient updates to previously pruned channels and the opportunity for the channels to later return to the network. We then formulate input channel pruning as a global resource allocation problem. Our method outperforms prior works on both the ImageNet classification and PASCAL VOC detection datasets.