 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Horizon Manipulation via Trace-Conditioned VLA Planning
Apr 23, 2026Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing
Mar 23, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have shown impressive reasoning abilities, yet they struggle with spatial understanding and layout consistency when performing fine-grained visual editing. We introduce a Structured Reasoning framework that performs text-conditioned spatial layout editing via scene-graph reasoning. Given an input scene graph and a natural-language instruction, the model reasons over the graph to generate an updated scene graph that satisfies the text condition while maintaining spatial coherence. By explicitly guiding the reasoning process through structured relational representations, our approach improves both interpretability and control over spatial relationships. We evaluate our method on a new text-guided layout editing benchmark encompassing sorting, spatial alignment, and room-editing tasks. Our training paradigm yields an average 15% improvement in IoU and 25% reduction in center-distance error compared to Chain of Thought Fine-tuning (CoT-SFT) and vanilla GRPO baselines. Compared to SOTA zero-shot LLMs, our best models achieve up to 20% higher mIoU, demonstrating markedly improved spatial precision.
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Dec 22, 2025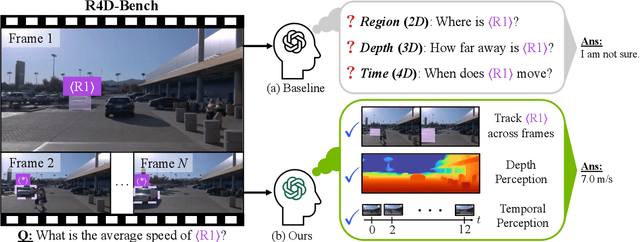

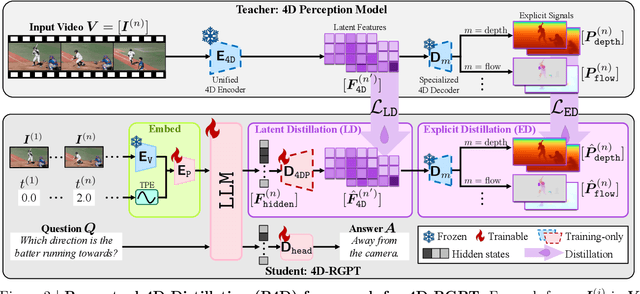
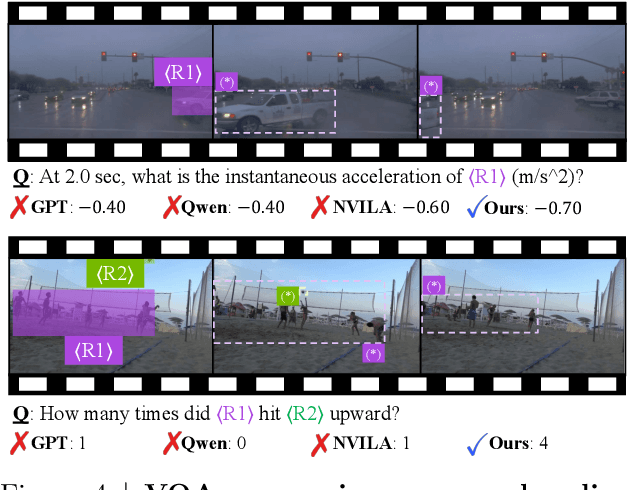
Despite advances in Multimodal LLMs (MLLMs), their ability to reason over 3D structures and temporal dynamics remains limited, constrained by weak 4D perception and temporal understanding. Existing 3D and 4D Video Question Answering (VQA) benchmarks also emphasize static scenes and lack region-level prompting. We tackle these issues by introducing: (a) 4D-RGPT, a specialized MLLM designed to capture 4D representations from video inputs with enhanced temporal perception; (b) Perceptual 4D Distillation (P4D), a training framework that transfers 4D representations from a frozen expert model into 4D-RGPT for comprehensive 4D perception; and (c) R4D-Bench, a benchmark for depth-aware dynamic scenes with region-level prompting, built via a hybrid automated and human-verified pipeline. Our 4D-RGPT achieves notable improvements on both existing 4D VQA benchmarks and the proposed R4D-Bench benchmark.
Real Deep Research for AI, Robotics and Beyond
Oct 23, 2025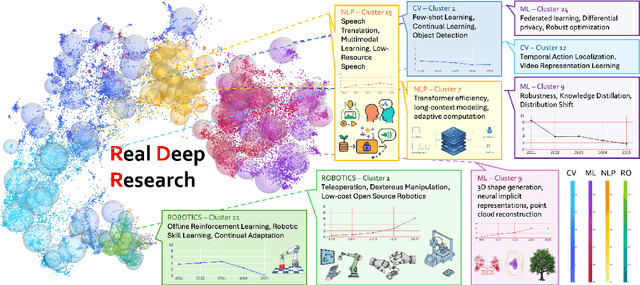
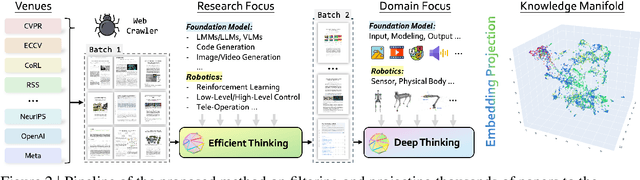
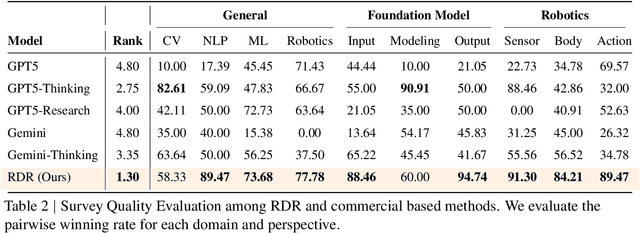
With the rapid growth of research in AI and robotics now producing over 10,000 papers annually it has become increasingly difficult for researchers to stay up to date. Fast evolving trends, the rise of interdisciplinary work, and the need to explore domains beyond one's expertise all contribute to this challenge. To address these issues, we propose a generalizable pipeline capable of systematically analyzing any research area: identifying emerging trends, uncovering cross domain opportunities, and offering concrete starting points for new inquiry. In this work, we present Real Deep Research (RDR) a comprehensive framework applied to the domains of AI and robotics, with a particular focus on foundation models and robotics advancements. We also briefly extend our analysis to other areas of science. The main paper details the construction of the RDR pipeline, while the appendix provides extensive results across each analyzed topic. We hope this work sheds light for researchers working in the field of AI and beyond.
Temporal Prompting Matters: Rethinking Referring Video Object Segmentation
Oct 08, 2025Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence in the video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we rethink the RVOS problem and aim to investigate the key to this task. Based on existing foundation segmentation models, we decompose the RVOS task into referring, video, and segmentation factors, and propose a Temporal Prompt Generation and Selection (Tenet) framework to address the referring and video factors while leaving the segmentation problem to foundation models. To efficiently adapt image-based foundation segmentation models to referring video object segmentation, we leverage off-the-shelf object detectors and trackers to produce temporal prompts associated with the referring sentence. While high-quality temporal prompts could be produced, they can not be easily identified from confidence scores. To tackle this issue, we propose Prompt Preference Learning to evaluate the quality of the produced temporal prompts. By taking such prompts to instruct image-based foundation segmentation models, we would be able to produce high-quality masks for the referred object, enabling efficient model adaptation to referring video object segmentation. Experiments on RVOS benchmarks demonstrate the effectiveness of the Tenet framework.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025



We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Jul 16, 2025Real robot data collection for imitation learning has led to significant advancements in robotic manipulation. However, the requirement for robot hardware in the process fundamentally constrains the scale of the data. In this paper, we explore training Vision-Language-Action (VLA) models using egocentric human videos. The benefit of using human videos is not only for their scale but more importantly for the richness of scenes and tasks. With a VLA trained on human video that predicts human wrist and hand actions, we can perform Inverse Kinematics and retargeting to convert the human actions to robot actions. We fine-tune the model using a few robot manipulation demonstrations to obtain the robot policy, namely EgoVLA. We propose a simulation benchmark called Isaac Humanoid Manipulation Benchmark, where we design diverse bimanual manipulation tasks with demonstrations. We fine-tune and evaluate EgoVLA with Isaac Humanoid Manipulation Benchmark and show significant improvements over baselines and ablate the importance of human data. Videos can be found on our website: https://rchalyang.github.io/EgoVLA
Scaling RL to Long Videos
Jul 10, 2025We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
Describe Anything: Detailed Localized Image and Video Captioning
Apr 22, 2025Generating detailed and accurate descriptions for specific regions in images and videos remains a fundamental challenge for vision-language models. We introduce the Describe Anything Model (DAM), a model designed for detailed localized captioning (DLC). DAM preserves both local details and global context through two key innovations: a focal prompt, which ensures high-resolution encoding of targeted regions, and a localized vision backbone, which integrates precise localization with its broader context. To tackle the scarcity of high-quality DLC data, we propose a Semi-supervised learning (SSL)-based Data Pipeline (DLC-SDP). DLC-SDP starts with existing segmentation datasets and expands to unlabeled web images using SSL. We introduce DLC-Bench, a benchmark designed to evaluate DLC without relying on reference captions. DAM sets new state-of-the-art on 7 benchmarks spanning keyword-level, phrase-level, and detailed multi-sentence localized image and video captioning.
Scaling Vision Pre-Training to 4K Resolution
Mar 25, 2025High-resolution perception of visual details is crucial for daily tasks. Current vision pre-training, however, is still limited to low resolutions (e.g., 378 x 378 pixels) due to the quadratic cost of processing larger images. We introduce PS3 that scales CLIP-style vision pre-training to 4K resolution with a near-constant cost. Instead of contrastive learning on global image representation, PS3 is pre-trained by selectively processing local regions and contrasting them with local detailed captions, enabling high-resolution representation learning with greatly reduced computational overhead. The pre-trained PS3 is able to both encode the global image at low resolution and selectively process local high-resolution regions based on their saliency or relevance to a text prompt. When applying PS3 to multi-modal LLM (MLLM), the resulting model, named VILA-HD, significantly improves high-resolution visual perception compared to baselines without high-resolution vision pre-training such as AnyRes and S^2 while using up to 4.3x fewer tokens. PS3 also unlocks appealing scaling properties of VILA-HD, including scaling up resolution for free and scaling up test-time compute for better performance. Compared to state of the arts, VILA-HD outperforms previous MLLMs such as NVILA and Qwen2-VL across multiple benchmarks and achieves better efficiency than latest token pruning approaches. Finally, we find current benchmarks do not require 4K-resolution perception, which motivates us to propose 4KPro, a new benchmark of image QA at 4K resolution, on which VILA-HD outperforms all previous MLLMs, including a 14.5% improvement over GPT-4o, and a 3.2% improvement and 2.96x speedup over Qwen2-VL.