 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Universal Video Segmentation Model
Aug 26, 2025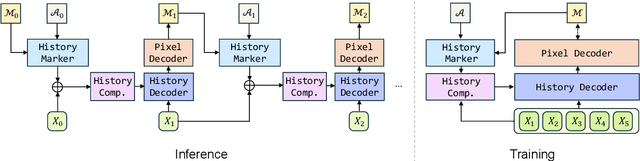
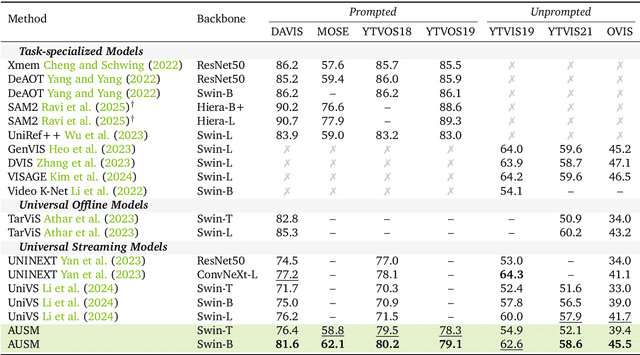
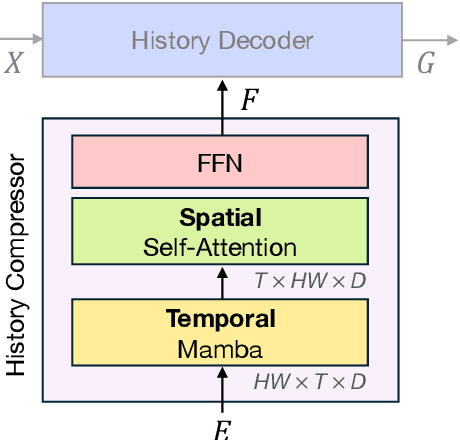

Recent video foundation models such as SAM2 excel at prompted video segmentation by treating masks as a general-purpose primitive. However, many real-world settings require unprompted segmentation that aims to detect and track all objects in a video without external cues, leaving today's landscape fragmented across task-specific models and pipelines. We recast streaming video segmentation as sequential mask prediction, analogous to language modeling, and introduce the Autoregressive Universal Segmentation Model (AUSM), a single architecture that unifies both prompted and unprompted video segmentation. Built on recent state-space models, AUSM maintains a fixed-size spatial state and scales to video streams of arbitrary length. Furthermore, all components of AUSM are designed for parallel training across frames, yielding substantial speedups over iterative training. On standard benchmarks (DAVIS17, YouTube-VOS 2018 & 2019, MOSE, YouTube-VIS 2019 & 2021, and OVIS) AUSM outperforms prior universal streaming video segmentation methods and achieves up to 2.5x faster training on 16-frame sequences.
Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
Jan 14, 2025We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space. These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens. To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video. Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.
VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement
Dec 08, 2023In recent years, online Video Instance Segmentation (VIS) methods have shown remarkable advancement with their powerful query-based detectors. Utilizing the output queries of the detector at the frame level, these methods achieve high accuracy on challenging benchmarks. However, we observe the heavy reliance of these methods on the location information that leads to incorrect matching when positional cues are insufficient for resolving ambiguities. Addressing this issue, we present VISAGE that enhances instance association by explicitly leveraging appearance information. Our method involves a generation of queries that embed appearances from backbone feature maps, which in turn get used in our suggested simple tracker for robust associations. Finally, enabling accurate matching in complex scenarios by resolving the issue of over-reliance on location information, we achieve competitive performance on multiple VIS benchmarks. For instance, on YTVIS19 and YTVIS21, our method achieves 54.5 AP and 50.8 AP. Furthermore, to highlight appearance-awareness not fully addressed by existing benchmarks, we generate a synthetic dataset where our method outperforms others significantly by leveraging the appearance cue. Code will be made available at https://github.com/KimHanjung/VISAGE.
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022



Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
VITA: Video Instance Segmentation via Object Token Association
Jun 09, 2022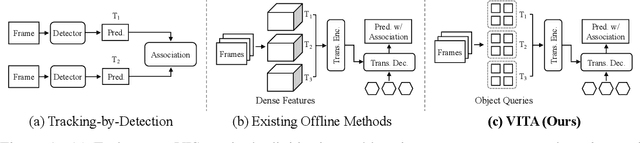
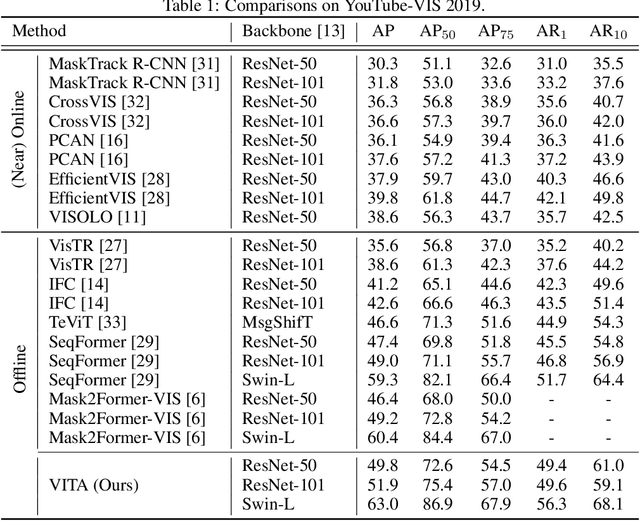
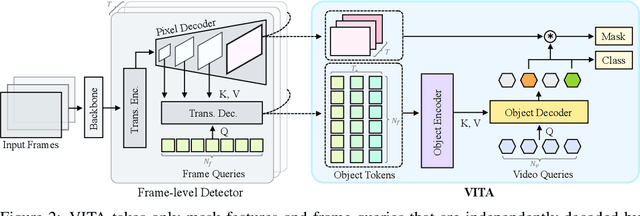
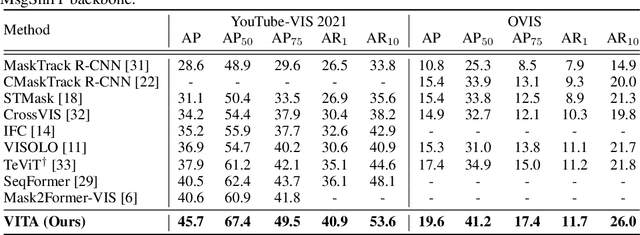
We introduce a novel paradigm for offline Video Instance Segmentation (VIS), based on the hypothesis that explicit object-oriented information can be a strong clue for understanding the context of the entire sequence. To this end, we propose VITA, a simple structure built on top of an off-the-shelf Transformer-based image instance segmentation model. Specifically, we use an image object detector as a means of distilling object-specific contexts into object tokens. VITA accomplishes video-level understanding by associating frame-level object tokens without using spatio-temporal backbone features. By effectively building relationships between objects using the condensed information, VITA achieves the state-of-the-art on VIS benchmarks with a ResNet-50 backbone: 49.8 AP, 45.7 AP on YouTube-VIS 2019 & 2021 and 19.6 AP on OVIS. Moreover, thanks to its object token-based structure that is disjoint from the backbone features, VITA shows several practical advantages that previous offline VIS methods have not explored - handling long and high-resolution videos with a common GPU and freezing a frame-level detector trained on image domain. Code will be made available at https://github.com/sukjunhwang/VITA.
Cannot See the Forest for the Trees: Aggregating Multiple Viewpoints to Better Classify Objects in Videos
Jun 05, 2022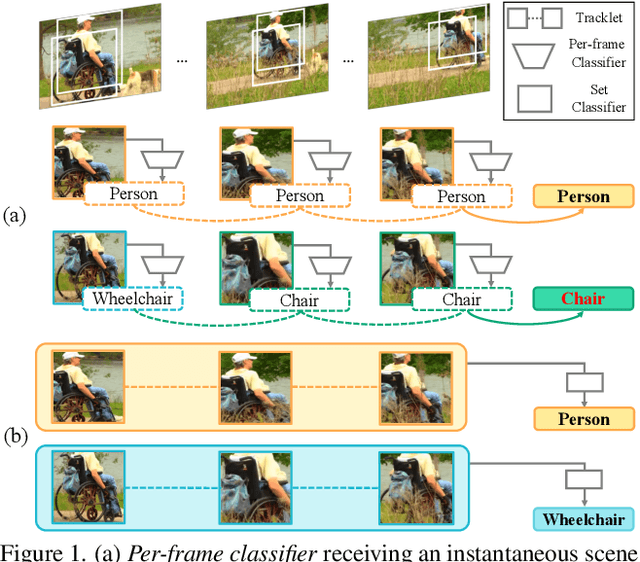

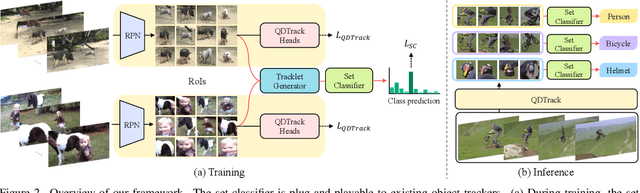
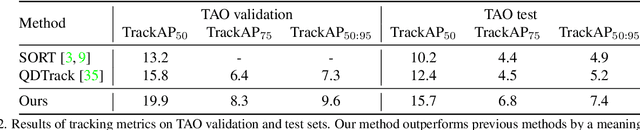
Recently, both long-tailed recognition and object tracking have made great advances individually. TAO benchmark presented a mixture of the two, long-tailed object tracking, in order to further reflect the aspect of the real-world. To date, existing solutions have adopted detectors showing robustness in long-tailed distributions, which derive per-frame results. Then, they used tracking algorithms that combine the temporally independent detections to finalize tracklets. However, as the approaches did not take temporal changes in scenes into account, inconsistent classification results in videos led to low overall performance. In this paper, we present a set classifier that improves accuracy of classifying tracklets by aggregating information from multiple viewpoints contained in a tracklet. To cope with sparse annotations in videos, we further propose augmentation of tracklets that can maximize data efficiency. The set classifier is plug-and-playable to existing object trackers, and highly improves the performance of long-tailed object tracking. By simply attaching our method to QDTrack on top of ResNet-101, we achieve the new state-of-the-art, 19.9% and 15.7% TrackAP_50 on TAO validation and test sets, respectively.
Video Instance Segmentation using Inter-Frame Communication Transformers
Jun 07, 2021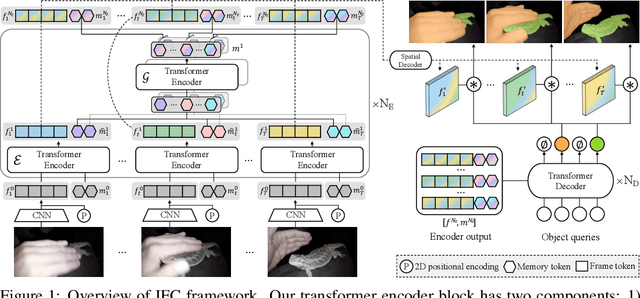

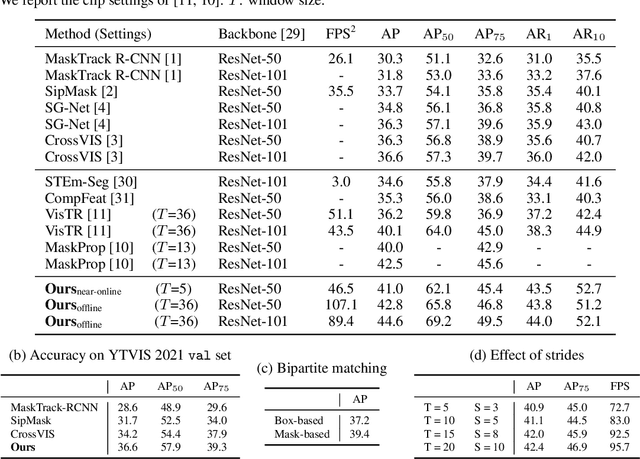

We propose a novel end-to-end solution for video instance segmentation (VIS) based on transformers. Recently, the per-clip pipeline shows superior performance over per-frame methods leveraging richer information from multiple frames. However, previous per-clip models require heavy computation and memory usage to achieve frame-to-frame communications, limiting practicality. In this work, we propose Inter-frame Communication Transformers (IFC), which significantly reduces the overhead for information-passing between frames by efficiently encoding the context within the input clip. Specifically, we propose to utilize concise memory tokens as a mean of conveying information as well as summarizing each frame scene. The features of each frame are enriched and correlated with other frames through exchange of information between the precisely encoded memory tokens. We validate our method on the latest benchmark sets and achieved the state-of-the-art performance (AP 44.6 on YouTube-VIS 2019 val set using the offline inference) while having a considerably fast runtime (89.4 FPS). Our method can also be applied to near-online inference for processing a video in real-time with only a small delay. The code will be made available.
Polygonal Point Set Tracking
May 30, 2021
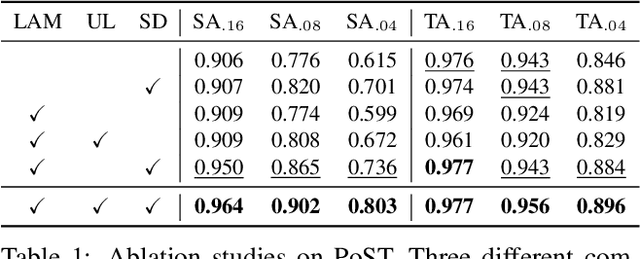
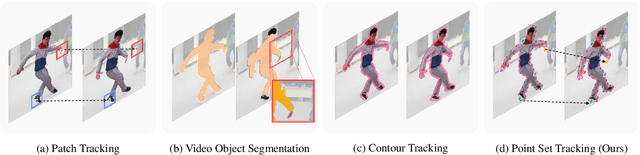
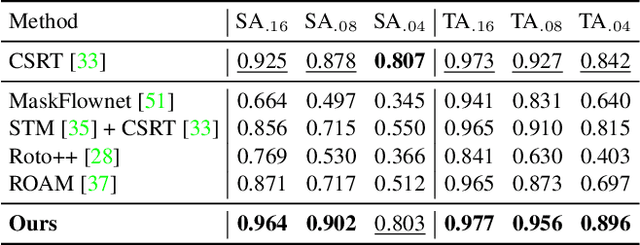
In this paper, we propose a novel learning-based polygonal point set tracking method. Compared to existing video object segmentation~(VOS) methods that propagate pixel-wise object mask information, we propagate a polygonal point set over frames. Specifically, the set is defined as a subset of points in the target contour, and our goal is to track corresponding points on the target contour. Those outputs enable us to apply various visual effects such as motion tracking, part deformation, and texture mapping. To this end, we propose a new method to track the corresponding points between frames by the global-local alignment with delicately designed losses and regularization terms. We also introduce a novel learning strategy using synthetic and VOS datasets that makes it possible to tackle the problem without developing the point correspondence dataset. Since the existing datasets are not suitable to validate our method, we build a new polygonal point set tracking dataset and demonstrate the superior performance of our method over the baselines and existing contour-based VOS methods. In addition, we present visual-effects applications of our method on part distortion and text mapping.