 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgednaHNet: A Scalable and Hierarchical Foundation Model for Genomic Sequence Learning
Feb 14, 2026Genomic foundation models have the potential to decode DNA syntax, yet face a fundamental tradeoff in their input representation. Standard fixed-vocabulary tokenizers fragment biologically meaningful motifs such as codons and regulatory elements, while nucleotide-level models preserve biological coherence but incur prohibitive computational costs for long contexts. We introduce dnaHNet, a state-of-the-art tokenizer-free autoregressive model that segments and models genomic sequences end-to-end. Using a differentiable dynamic chunking mechanism, dnaHNet compresses raw nucleotides into latent tokens adaptively, balancing compression with predictive accuracy. Pretrained on prokaryotic genomes, dnaHNet outperforms leading architectures including StripedHyena2 in scaling and efficiency. This recursive chunking yields quadratic FLOP reductions, enabling $>3 \times$ inference speedup over Transformers. On zero-shot tasks, dnaHNet achieves superior performance in predicting protein variant fitness and gene essentiality, while automatically discovering hierarchical biological structures without supervision. These results establish dnaHNet as a scalable, interpretable framework for next-generation genomic modeling.
Autoregressive Universal Video Segmentation Model
Aug 26, 2025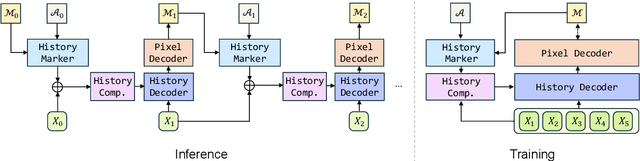
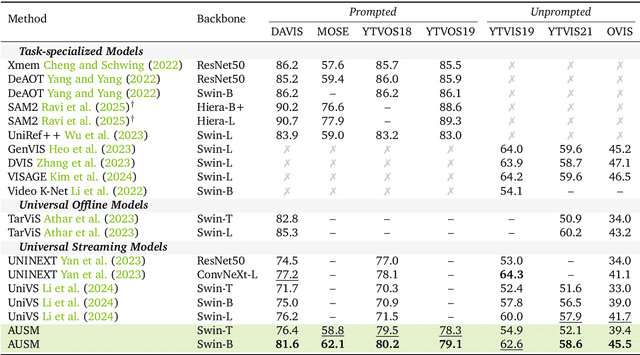
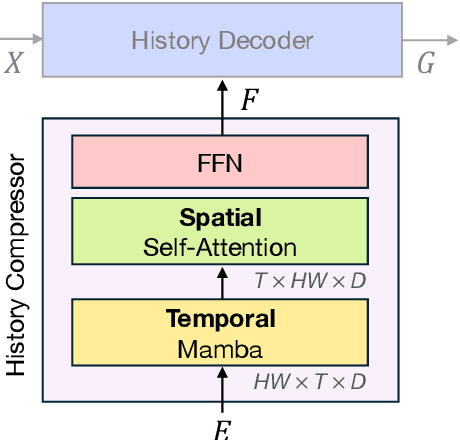

Recent video foundation models such as SAM2 excel at prompted video segmentation by treating masks as a general-purpose primitive. However, many real-world settings require unprompted segmentation that aims to detect and track all objects in a video without external cues, leaving today's landscape fragmented across task-specific models and pipelines. We recast streaming video segmentation as sequential mask prediction, analogous to language modeling, and introduce the Autoregressive Universal Segmentation Model (AUSM), a single architecture that unifies both prompted and unprompted video segmentation. Built on recent state-space models, AUSM maintains a fixed-size spatial state and scales to video streams of arbitrary length. Furthermore, all components of AUSM are designed for parallel training across frames, yielding substantial speedups over iterative training. On standard benchmarks (DAVIS17, YouTube-VOS 2018 & 2019, MOSE, YouTube-VIS 2019 & 2021, and OVIS) AUSM outperforms prior universal streaming video segmentation methods and achieves up to 2.5x faster training on 16-frame sequences.
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling
Jul 10, 2025Despite incredible progress in language models (LMs) in recent years, largely resulting from moving away from specialized models designed for specific tasks to general models based on powerful architectures (e.g. the Transformer) that learn everything from raw data, pre-processing steps such as tokenization remain a barrier to true end-to-end foundation models. We introduce a collection of new techniques that enable a dynamic chunking mechanism which automatically learns content -- and context -- dependent segmentation strategies learned jointly with the rest of the model. Incorporating this into an explicit hierarchical network (H-Net) allows replacing the (implicitly hierarchical) tokenization-LM-detokenization pipeline with a single model learned fully end-to-end. When compute- and data- matched, an H-Net with one stage of hierarchy operating at the byte level outperforms a strong Transformer language model operating over BPE tokens. Iterating the hierarchy to multiple stages further increases its performance by modeling multiple levels of abstraction, demonstrating significantly better scaling with data and matching a token-based Transformer of twice its size. H-Nets pretrained on English show significantly increased character-level robustness, and qualitatively learn meaningful data-dependent chunking strategies without any heuristics or explicit supervision. Finally, the H-Net's improvement over tokenized pipelines is further increased in languages and modalities with weaker tokenization heuristics, such as Chinese and code, or DNA sequences (nearly 4x improvement in data efficiency over baselines), showing the potential of true end-to-end models that learn and scale better from unprocessed data.
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025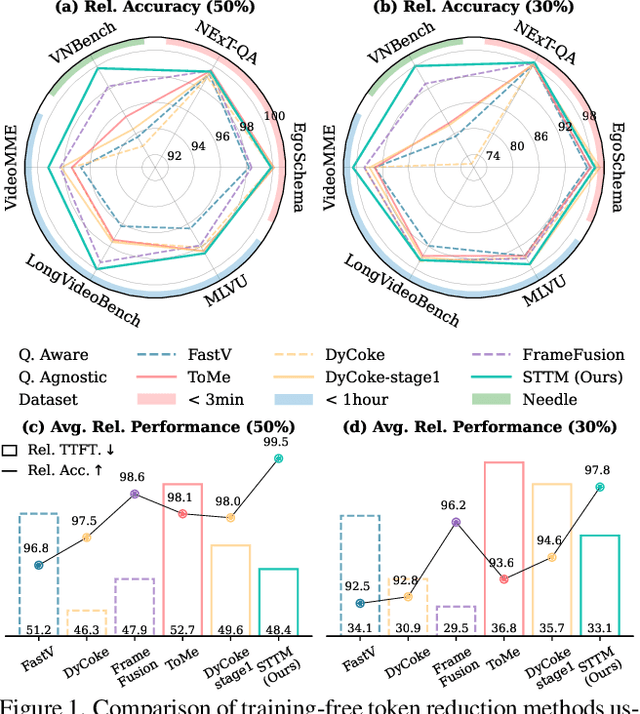

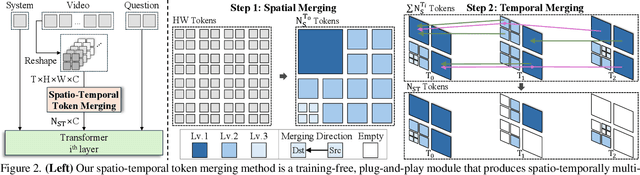

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Hydra: Bidirectional State Space Models Through Generalized Matrix Mixers
Jul 13, 2024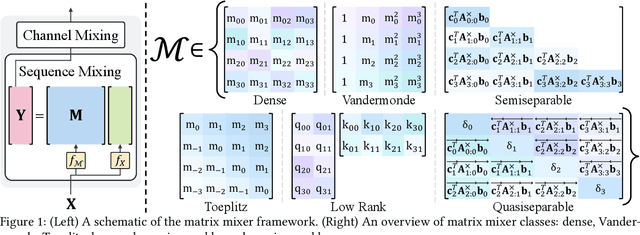
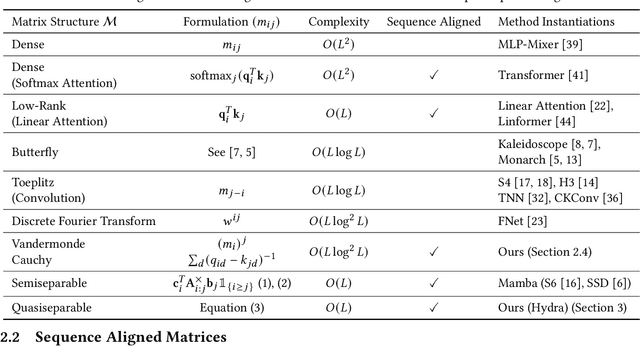
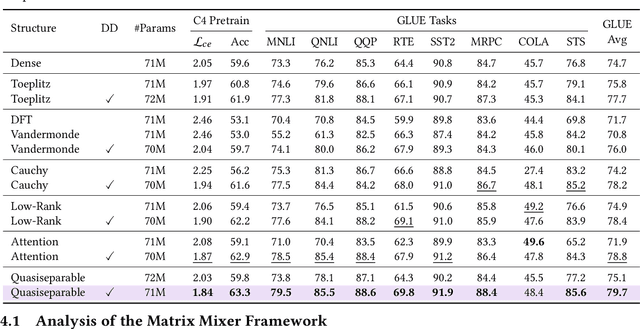
A wide array of sequence models are built on a framework modeled after Transformers, comprising alternating sequence mixer and channel mixer layers. This paper studies a unifying matrix mixer view of sequence mixers that can be conceptualized as a linear map on the input sequence. This framework encompasses a broad range of well-known sequence models, including the self-attention of Transformers as well as recent strong alternatives such as structured state space models (SSMs), and allows understanding downstream characteristics such as efficiency and expressivity through properties of their structured matrix class. We identify a key axis of matrix parameterizations termed sequence alignment, which increases the flexibility and performance of matrix mixers, providing insights into the strong performance of Transformers and recent SSMs such as Mamba. Furthermore, the matrix mixer framework offers a systematic approach to developing sequence mixers with desired properties, allowing us to develop several new sub-quadratic sequence models. In particular, we propose a natural bidirectional extension of the Mamba model (Hydra), parameterized as a quasiseparable matrix mixer, which demonstrates superior performance over other sequence models including Transformers on non-causal tasks. As a drop-in replacement for attention layers, Hydra outperforms BERT by 0.8 points on the GLUE benchmark and ViT by 2% Top-1 accuracy on ImageNet.
VISAGE: Video Instance Segmentation with Appearance-Guided Enhancement
Dec 08, 2023In recent years, online Video Instance Segmentation (VIS) methods have shown remarkable advancement with their powerful query-based detectors. Utilizing the output queries of the detector at the frame level, these methods achieve high accuracy on challenging benchmarks. However, we observe the heavy reliance of these methods on the location information that leads to incorrect matching when positional cues are insufficient for resolving ambiguities. Addressing this issue, we present VISAGE that enhances instance association by explicitly leveraging appearance information. Our method involves a generation of queries that embed appearances from backbone feature maps, which in turn get used in our suggested simple tracker for robust associations. Finally, enabling accurate matching in complex scenarios by resolving the issue of over-reliance on location information, we achieve competitive performance on multiple VIS benchmarks. For instance, on YTVIS19 and YTVIS21, our method achieves 54.5 AP and 50.8 AP. Furthermore, to highlight appearance-awareness not fully addressed by existing benchmarks, we generate a synthetic dataset where our method outperforms others significantly by leveraging the appearance cue. Code will be made available at https://github.com/KimHanjung/VISAGE.
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022



Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
VITA: Video Instance Segmentation via Object Token Association
Jun 09, 2022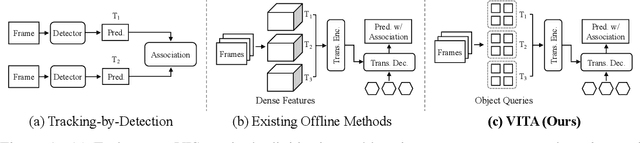
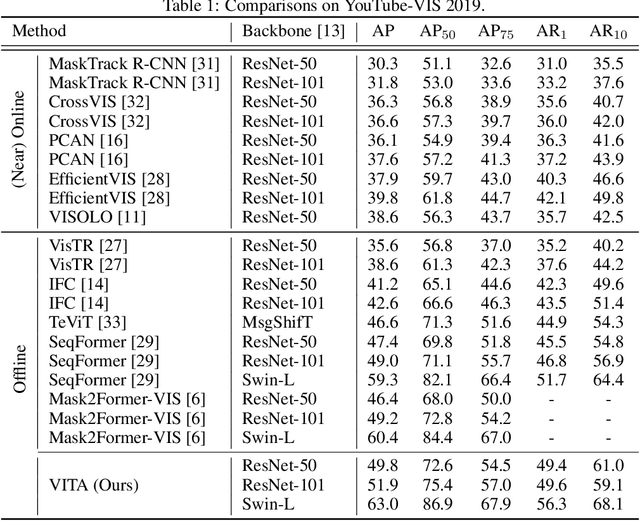
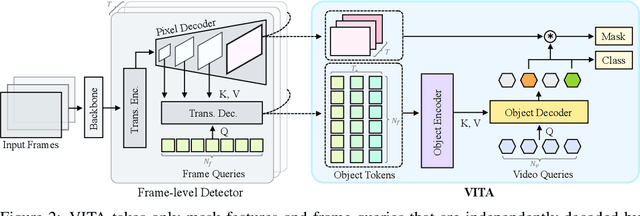
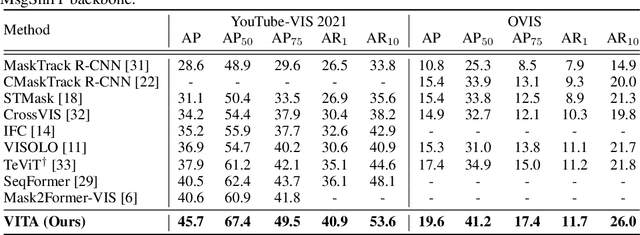
We introduce a novel paradigm for offline Video Instance Segmentation (VIS), based on the hypothesis that explicit object-oriented information can be a strong clue for understanding the context of the entire sequence. To this end, we propose VITA, a simple structure built on top of an off-the-shelf Transformer-based image instance segmentation model. Specifically, we use an image object detector as a means of distilling object-specific contexts into object tokens. VITA accomplishes video-level understanding by associating frame-level object tokens without using spatio-temporal backbone features. By effectively building relationships between objects using the condensed information, VITA achieves the state-of-the-art on VIS benchmarks with a ResNet-50 backbone: 49.8 AP, 45.7 AP on YouTube-VIS 2019 & 2021 and 19.6 AP on OVIS. Moreover, thanks to its object token-based structure that is disjoint from the backbone features, VITA shows several practical advantages that previous offline VIS methods have not explored - handling long and high-resolution videos with a common GPU and freezing a frame-level detector trained on image domain. Code will be made available at https://github.com/sukjunhwang/VITA.
Cannot See the Forest for the Trees: Aggregating Multiple Viewpoints to Better Classify Objects in Videos
Jun 05, 2022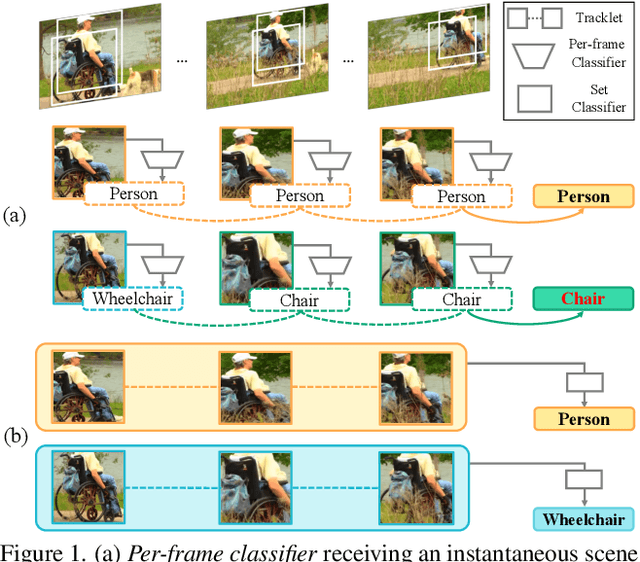

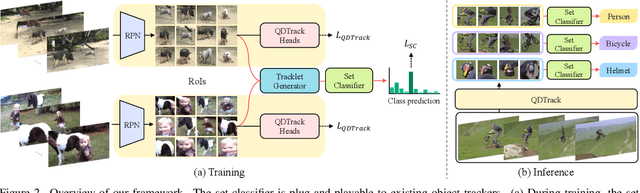
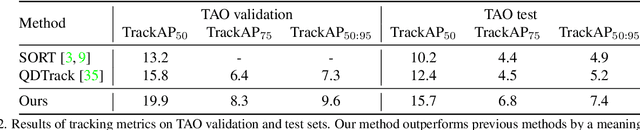
Recently, both long-tailed recognition and object tracking have made great advances individually. TAO benchmark presented a mixture of the two, long-tailed object tracking, in order to further reflect the aspect of the real-world. To date, existing solutions have adopted detectors showing robustness in long-tailed distributions, which derive per-frame results. Then, they used tracking algorithms that combine the temporally independent detections to finalize tracklets. However, as the approaches did not take temporal changes in scenes into account, inconsistent classification results in videos led to low overall performance. In this paper, we present a set classifier that improves accuracy of classifying tracklets by aggregating information from multiple viewpoints contained in a tracklet. To cope with sparse annotations in videos, we further propose augmentation of tracklets that can maximize data efficiency. The set classifier is plug-and-playable to existing object trackers, and highly improves the performance of long-tailed object tracking. By simply attaching our method to QDTrack on top of ResNet-101, we achieve the new state-of-the-art, 19.9% and 15.7% TrackAP_50 on TAO validation and test sets, respectively.
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Dec 08, 2021
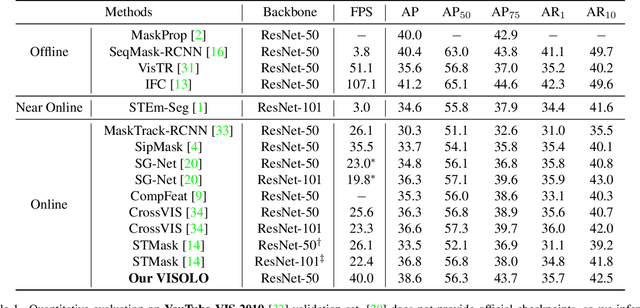
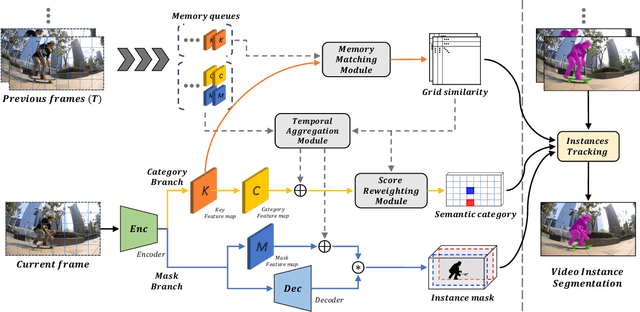
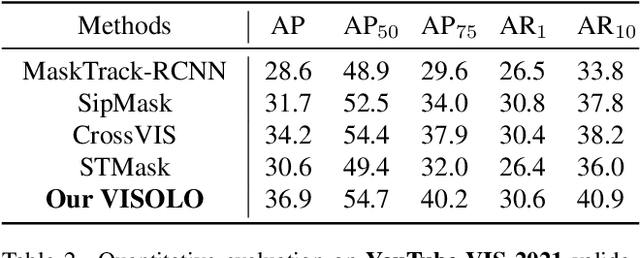
For online video instance segmentation (VIS), fully utilizing the information from previous frames in an efficient manner is essential for real-time applications. Most previous methods follow a two-stage approach requiring additional computations such as RPN and RoIAlign, and do not fully exploit the available information in the video for all subtasks in VIS. In this paper, we propose a novel single-stage framework for online VIS built based on the grid structured feature representation. The grid-based features allow us to employ fully convolutional networks for real-time processing, and also to easily reuse and share features within different components. We also introduce cooperatively operating modules that aggregate information from available frames, in order to enrich the features for all subtasks in VIS. Our design fully takes advantage of previous information in a grid form for all tasks in VIS in an efficient way, and we achieved the new state-of-the-art accuracy (38.6 AP and 36.9 AP) and speed (40.0 FPS) on YouTube-VIS 2019 and 2021 datasets among online VIS methods.