 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025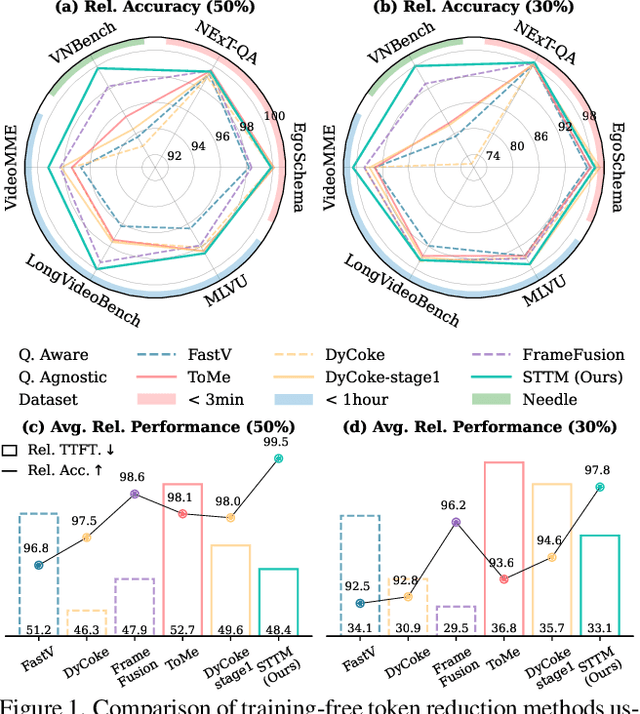

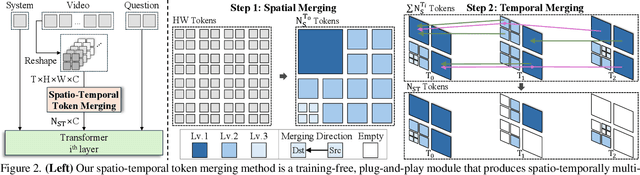

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Exploring Scalability of Self-Training for Open-Vocabulary Temporal Action Localization
Jul 09, 2024The vocabulary size in temporal action localization (TAL) is constrained by the scarcity of large-scale annotated datasets. To address this, recent works incorporate powerful pre-trained vision-language models (VLMs), such as CLIP, to perform open-vocabulary TAL (OV-TAL). However, unlike VLMs trained on extensive image/video-text pairs, existing OV-TAL methods still rely on small, fully labeled TAL datasets for training an action localizer. In this paper, we explore the scalability of self-training with unlabeled YouTube videos for OV-TAL. Our self-training approach consists of two stages. First, a class-agnostic action localizer is trained on a human-labeled TAL dataset and used to generate pseudo-labels for unlabeled videos. Second, the large-scale pseudo-labeled dataset is combined with the human-labeled dataset to train the localizer. Extensive experiments demonstrate that leveraging web-scale videos in self-training significantly enhances the generalizability of an action localizer. Additionally, we highlighted issues with existing OV-TAL evaluation schemes and proposed a new evaluation protocol. Code is released at https://github.com/HYUNJS/STOV-TAL
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Dec 08, 2021
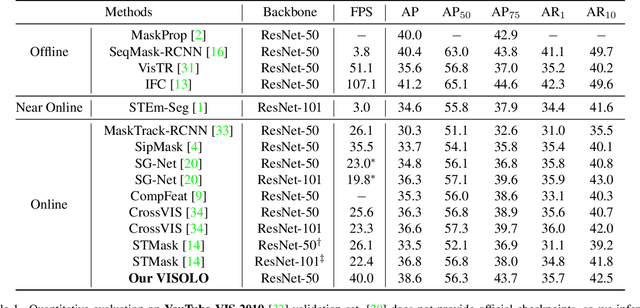
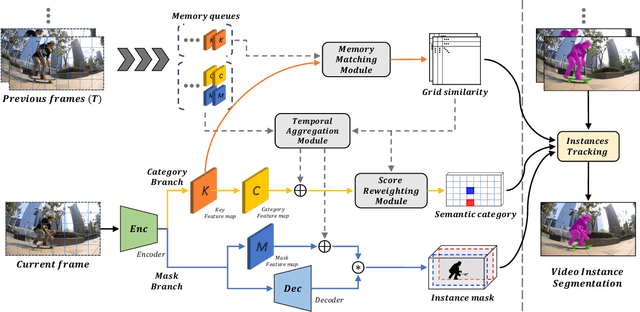
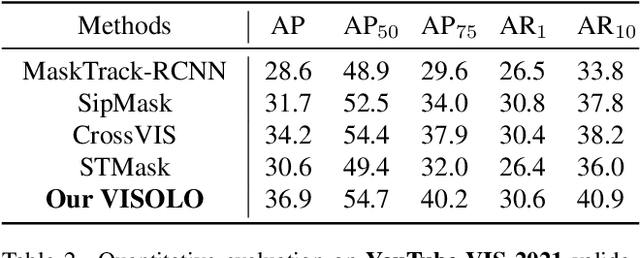
For online video instance segmentation (VIS), fully utilizing the information from previous frames in an efficient manner is essential for real-time applications. Most previous methods follow a two-stage approach requiring additional computations such as RPN and RoIAlign, and do not fully exploit the available information in the video for all subtasks in VIS. In this paper, we propose a novel single-stage framework for online VIS built based on the grid structured feature representation. The grid-based features allow us to employ fully convolutional networks for real-time processing, and also to easily reuse and share features within different components. We also introduce cooperatively operating modules that aggregate information from available frames, in order to enrich the features for all subtasks in VIS. Our design fully takes advantage of previous information in a grid form for all tasks in VIS in an efficient way, and we achieved the new state-of-the-art accuracy (38.6 AP and 36.9 AP) and speed (40.0 FPS) on YouTube-VIS 2019 and 2021 datasets among online VIS methods.