 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinite-Homography as Robust Conditioning for Camera-Controlled Video Generation
Dec 18, 2025



Recent progress in video diffusion models has spurred growing interest in camera-controlled novel-view video generation for dynamic scenes, aiming to provide creators with cinematic camera control capabilities in post-production. A key challenge in camera-controlled video generation is ensuring fidelity to the specified camera pose, while maintaining view consistency and reasoning about occluded geometry from limited observations. To address this, existing methods either train trajectory-conditioned video generation model on trajectory-video pair dataset, or estimate depth from the input video to reproject it along a target trajectory and generate the unprojected regions. Nevertheless, existing methods struggle to generate camera-pose-faithful, high-quality videos for two main reasons: (1) reprojection-based approaches are highly susceptible to errors caused by inaccurate depth estimation; and (2) the limited diversity of camera trajectories in existing datasets restricts learned models. To address these limitations, we present InfCam, a depth-free, camera-controlled video-to-video generation framework with high pose fidelity. The framework integrates two key components: (1) infinite homography warping, which encodes 3D camera rotations directly within the 2D latent space of a video diffusion model. Conditioning on this noise-free rotational information, the residual parallax term is predicted through end-to-end training to achieve high camera-pose fidelity; and (2) a data augmentation pipeline that transforms existing synthetic multiview datasets into sequences with diverse trajectories and focal lengths. Experimental results demonstrate that InfCam outperforms baseline methods in camera-pose accuracy and visual fidelity, generalizing well from synthetic to real-world data. Link to our project page:https://emjay73.github.io/InfCam/
TV-LiVE: Training-Free, Text-Guided Video Editing via Layer Informed Vitality Exploitation
Jun 08, 2025

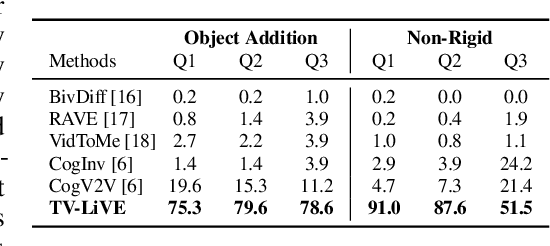

Video editing has garnered increasing attention alongside the rapid progress of diffusion-based video generation models. As part of these advancements, there is a growing demand for more accessible and controllable forms of video editing, such as prompt-based editing. Previous studies have primarily focused on tasks such as style transfer, background replacement, object substitution, and attribute modification, while maintaining the content structure of the source video. However, more complex tasks, including the addition of novel objects and nonrigid transformations, remain relatively unexplored. In this paper, we present TV-LiVE, a Training-free and text-guided Video editing framework via Layerinformed Vitality Exploitation. We empirically identify vital layers within the video generation model that significantly influence the quality of generated outputs. Notably, these layers are closely associated with Rotary Position Embeddings (RoPE). Based on this observation, our method enables both object addition and non-rigid video editing by selectively injecting key and value features from the source model into the corresponding layers of the target model guided by the layer vitality. For object addition, we further identify prominent layers to extract the mask regions corresponding to the newly added target prompt. We found that the extracted masks from the prominent layers faithfully indicate the region to be edited. Experimental results demonstrate that TV-LiVE outperforms existing approaches for both object addition and non-rigid video editing. Project Page: https://emjay73.github.io/TV_LiVE/
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling
Nov 27, 2024



Diffusion models have emerged as a powerful tool for generating high-quality images, videos, and 3D content. While sampling guidance techniques like CFG improve quality, they reduce diversity and motion. Autoguidance mitigates these issues but demands extra weak model training, limiting its practicality for large-scale models. In this work, we introduce Spatiotemporal Skip Guidance (STG), a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree. Our contributions include: (1) introducing STG as an efficient, high-performing guidance technique for video diffusion models, (2) eliminating the need for auxiliary models by simulating a weak model through layer skipping, and (3) ensuring quality-enhanced guidance without compromising sample diversity or dynamics unlike CFG. For additional results, visit https://junhahyung.github.io/STGuidance.
SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
Oct 15, 2024Recent advancements in head avatar rendering using Gaussian primitives have achieved significantly high-fidelity results. Although precise head geometry is crucial for applications like mesh reconstruction and relighting, current methods struggle to capture intricate geometric details and render unseen poses due to their reliance on similarity transformations, which cannot handle stretch and shear transforms essential for detailed deformations of geometry. To address this, we propose SurFhead, a novel method that reconstructs riggable head geometry from RGB videos using 2D Gaussian surfels, which offer well-defined geometric properties, such as precise depth from fixed ray intersections and normals derived from their surface orientation, making them advantageous over 3D counterparts. SurFhead ensures high-fidelity rendering of both normals and images, even in extreme poses, by leveraging classical mesh-based deformation transfer and affine transformation interpolation. SurFhead introduces precise geometric deformation and blends surfels through polar decomposition of transformations, including those affecting normals. Our key contribution lies in bridging classical graphics techniques, such as mesh-based deformation, with modern Gaussian primitives, achieving state-of-the-art geometry reconstruction and rendering quality. Unlike previous avatar rendering approaches, SurFhead enables efficient reconstruction driven by Gaussian primitives while preserving high-fidelity geometry.
TCAN: Animating Human Images with Temporally Consistent Pose Guidance using Diffusion Models
Jul 12, 2024
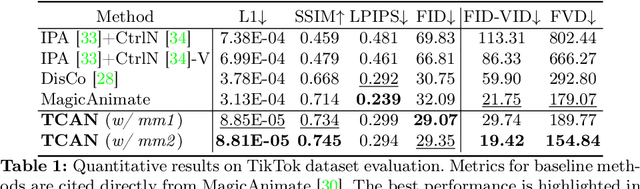
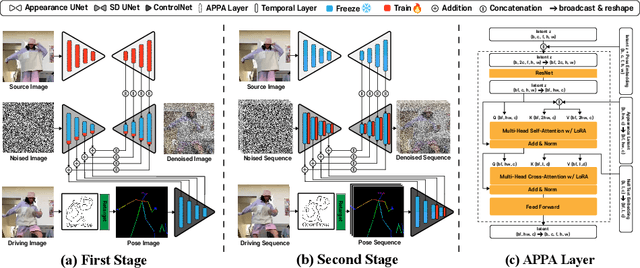

Pose-driven human-image animation diffusion models have shown remarkable capabilities in realistic human video synthesis. Despite the promising results achieved by previous approaches, challenges persist in achieving temporally consistent animation and ensuring robustness with off-the-shelf pose detectors. In this paper, we present TCAN, a pose-driven human image animation method that is robust to erroneous poses and consistent over time. In contrast to previous methods, we utilize the pre-trained ControlNet without fine-tuning to leverage its extensive pre-acquired knowledge from numerous pose-image-caption pairs. To keep the ControlNet frozen, we adapt LoRA to the UNet layers, enabling the network to align the latent space between the pose and appearance features. Additionally, by introducing an additional temporal layer to the ControlNet, we enhance robustness against outliers of the pose detector. Through the analysis of attention maps over the temporal axis, we also designed a novel temperature map leveraging pose information, allowing for a more static background. Extensive experiments demonstrate that the proposed method can achieve promising results in video synthesis tasks encompassing various poses, like chibi. Project Page: https://eccv2024tcan.github.io/
VEGS: View Extrapolation of Urban Scenes in 3D Gaussian Splatting using Learned Priors
Jul 03, 2024



Neural rendering-based urban scene reconstruction methods commonly rely on images collected from driving vehicles with cameras facing and moving forward. Although these methods can successfully synthesize from views similar to training camera trajectory, directing the novel view outside the training camera distribution does not guarantee on-par performance. In this paper, we tackle the Extrapolated View Synthesis (EVS) problem by evaluating the reconstructions on views such as looking left, right or downwards with respect to training camera distributions. To improve rendering quality for EVS, we initialize our model by constructing dense LiDAR map, and propose to leverage prior scene knowledge such as surface normal estimator and large-scale diffusion model. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS. To the best of our knowledge, we are the first to address the EVS problem in urban scene reconstruction. Link to our project page: https://vegs3d.github.io/.
FaceCLIPNeRF: Text-driven 3D Face Manipulation using Deformable Neural Radiance Fields
Aug 07, 2023



As recent advances in Neural Radiance Fields (NeRF) have enabled high-fidelity 3D face reconstruction and novel view synthesis, its manipulation also became an essential task in 3D vision. However, existing manipulation methods require extensive human labor, such as a user-provided semantic mask and manual attribute search unsuitable for non-expert users. Instead, our approach is designed to require a single text to manipulate a face reconstructed with NeRF. To do so, we first train a scene manipulator, a latent code-conditional deformable NeRF, over a dynamic scene to control a face deformation using the latent code. However, representing a scene deformation with a single latent code is unfavorable for compositing local deformations observed in different instances. As so, our proposed Position-conditional Anchor Compositor (PAC) learns to represent a manipulated scene with spatially varying latent codes. Their renderings with the scene manipulator are then optimized to yield high cosine similarity to a target text in CLIP embedding space for text-driven manipulation. To the best of our knowledge, our approach is the first to address the text-driven manipulation of a face reconstructed with NeRF. Extensive results, comparisons, and ablation studies demonstrate the effectiveness of our approach.
VISOLO: Grid-Based Space-Time Aggregation for Efficient Online Video Instance Segmentation
Dec 08, 2021
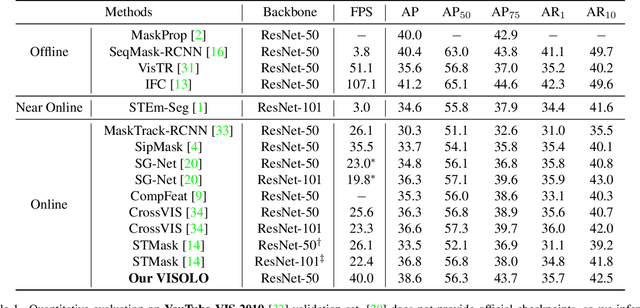
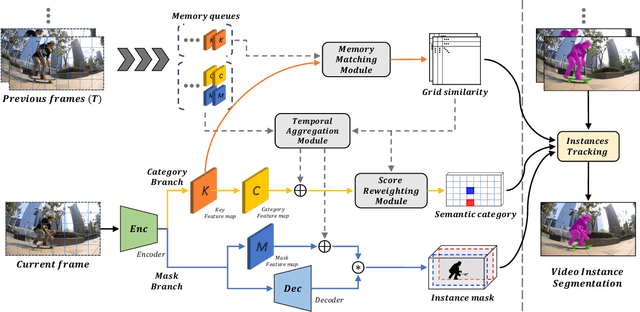
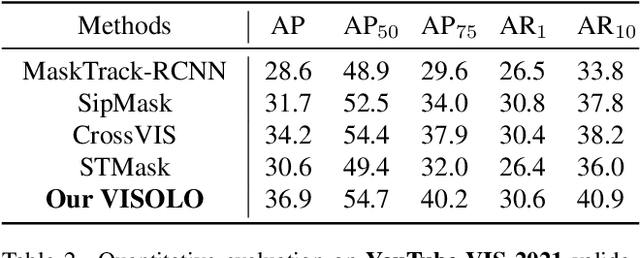
For online video instance segmentation (VIS), fully utilizing the information from previous frames in an efficient manner is essential for real-time applications. Most previous methods follow a two-stage approach requiring additional computations such as RPN and RoIAlign, and do not fully exploit the available information in the video for all subtasks in VIS. In this paper, we propose a novel single-stage framework for online VIS built based on the grid structured feature representation. The grid-based features allow us to employ fully convolutional networks for real-time processing, and also to easily reuse and share features within different components. We also introduce cooperatively operating modules that aggregate information from available frames, in order to enrich the features for all subtasks in VIS. Our design fully takes advantage of previous information in a grid form for all tasks in VIS in an efficient way, and we achieved the new state-of-the-art accuracy (38.6 AP and 36.9 AP) and speed (40.0 FPS) on YouTube-VIS 2019 and 2021 datasets among online VIS methods.