 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexAvatars : Hybrid Texel-3D Representations for Stable Rigging of Photorealistic Gaussian Head Avatars
Dec 24, 2025
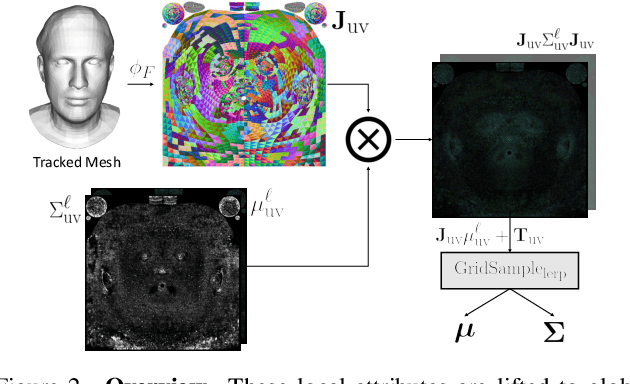


Constructing drivable and photorealistic 3D head avatars has become a central task in AR/XR, enabling immersive and expressive user experiences. With the emergence of high-fidelity and efficient representations such as 3D Gaussians, recent works have pushed toward ultra-detailed head avatars. Existing approaches typically fall into two categories: rule-based analytic rigging or neural network-based deformation fields. While effective in constrained settings, both approaches often fail to generalize to unseen expressions and poses, particularly in extreme reenactment scenarios. Other methods constrain Gaussians to the global texel space of 3DMMs to reduce rendering complexity. However, these texel-based avatars tend to underutilize the underlying mesh structure. They apply minimal analytic deformation and rely heavily on neural regressors and heuristic regularization in UV space, which weakens geometric consistency and limits extrapolation to complex, out-of-distribution deformations. To address these limitations, we introduce TexAvatars, a hybrid avatar representation that combines the explicit geometric grounding of analytic rigging with the spatial continuity of texel space. Our approach predicts local geometric attributes in UV space via CNNs, but drives 3D deformation through mesh-aware Jacobians, enabling smooth and semantically meaningful transitions across triangle boundaries. This hybrid design separates semantic modeling from geometric control, resulting in improved generalization, interpretability, and stability. Furthermore, TexAvatars captures fine-grained expression effects, including muscle-induced wrinkles, glabellar lines, and realistic mouth cavity geometry, with high fidelity. Our method achieves state-of-the-art performance under extreme pose and expression variations, demonstrating strong generalization in challenging head reenactment settings.
EgoX: Egocentric Video Generation from a Single Exocentric Video
Dec 09, 2025Egocentric perception enables humans to experience and understand the world directly from their own point of view. Translating exocentric (third-person) videos into egocentric (first-person) videos opens up new possibilities for immersive understanding but remains highly challenging due to extreme camera pose variations and minimal view overlap. This task requires faithfully preserving visible content while synthesizing unseen regions in a geometrically consistent manner. To achieve this, we present EgoX, a novel framework for generating egocentric videos from a single exocentric input. EgoX leverages the pretrained spatio temporal knowledge of large-scale video diffusion models through lightweight LoRA adaptation and introduces a unified conditioning strategy that combines exocentric and egocentric priors via width and channel wise concatenation. Additionally, a geometry-guided self-attention mechanism selectively attends to spatially relevant regions, ensuring geometric coherence and high visual fidelity. Our approach achieves coherent and realistic egocentric video generation while demonstrating strong scalability and robustness across unseen and in-the-wild videos.
SphereDiff: Tuning-free Omnidirectional Panoramic Image and Video Generation via Spherical Latent Representation
Apr 19, 2025The increasing demand for AR/VR applications has highlighted the need for high-quality 360-degree panoramic content. However, generating high-quality 360-degree panoramic images and videos remains a challenging task due to the severe distortions introduced by equirectangular projection (ERP). Existing approaches either fine-tune pretrained diffusion models on limited ERP datasets or attempt tuning-free methods that still rely on ERP latent representations, leading to discontinuities near the poles. In this paper, we introduce SphereDiff, a novel approach for seamless 360-degree panoramic image and video generation using state-of-the-art diffusion models without additional tuning. We define a spherical latent representation that ensures uniform distribution across all perspectives, mitigating the distortions inherent in ERP. We extend MultiDiffusion to spherical latent space and propose a spherical latent sampling method to enable direct use of pretrained diffusion models. Moreover, we introduce distortion-aware weighted averaging to further improve the generation quality in the projection process. Our method outperforms existing approaches in generating 360-degree panoramic content while maintaining high fidelity, making it a robust solution for immersive AR/VR applications. The code is available here. https://github.com/pmh9960/SphereDiff
SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
Oct 15, 2024Recent advancements in head avatar rendering using Gaussian primitives have achieved significantly high-fidelity results. Although precise head geometry is crucial for applications like mesh reconstruction and relighting, current methods struggle to capture intricate geometric details and render unseen poses due to their reliance on similarity transformations, which cannot handle stretch and shear transforms essential for detailed deformations of geometry. To address this, we propose SurFhead, a novel method that reconstructs riggable head geometry from RGB videos using 2D Gaussian surfels, which offer well-defined geometric properties, such as precise depth from fixed ray intersections and normals derived from their surface orientation, making them advantageous over 3D counterparts. SurFhead ensures high-fidelity rendering of both normals and images, even in extreme poses, by leveraging classical mesh-based deformation transfer and affine transformation interpolation. SurFhead introduces precise geometric deformation and blends surfels through polar decomposition of transformations, including those affecting normals. Our key contribution lies in bridging classical graphics techniques, such as mesh-based deformation, with modern Gaussian primitives, achieving state-of-the-art geometry reconstruction and rendering quality. Unlike previous avatar rendering approaches, SurFhead enables efficient reconstruction driven by Gaussian primitives while preserving high-fidelity geometry.
VEGS: View Extrapolation of Urban Scenes in 3D Gaussian Splatting using Learned Priors
Jul 03, 2024



Neural rendering-based urban scene reconstruction methods commonly rely on images collected from driving vehicles with cameras facing and moving forward. Although these methods can successfully synthesize from views similar to training camera trajectory, directing the novel view outside the training camera distribution does not guarantee on-par performance. In this paper, we tackle the Extrapolated View Synthesis (EVS) problem by evaluating the reconstructions on views such as looking left, right or downwards with respect to training camera distributions. To improve rendering quality for EVS, we initialize our model by constructing dense LiDAR map, and propose to leverage prior scene knowledge such as surface normal estimator and large-scale diffusion model. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS. To the best of our knowledge, we are the first to address the EVS problem in urban scene reconstruction. Link to our project page: https://vegs3d.github.io/.
Expression Domain Translation Network for Cross-domain Head Reenactment
Nov 06, 2023

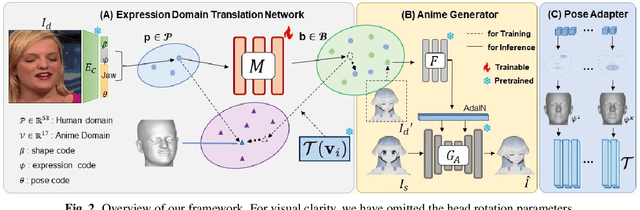

Despite the remarkable advancements in head reenactment, the existing methods face challenges in cross-domain head reenactment, which aims to transfer human motions to domains outside the human, including cartoon characters. It is still difficult to extract motion from out-of-domain images due to the distinct appearances, such as large eyes. Recently, previous work introduced a large-scale anime dataset called AnimeCeleb and a cross-domain head reenactment model, including an optimization-based mapping function to translate the human domain's expressions to the anime domain. However, we found that the mapping function, which relies on a subset of expressions, imposes limitations on the mapping of various expressions. To solve this challenge, we introduce a novel expression domain translation network that transforms human expressions into anime expressions. Specifically, to maintain the geometric consistency of expressions between the input and output of the expression domain translation network, we employ a 3D geometric-aware loss function that reduces the distances between the vertices in the 3D mesh of the human and anime. By doing so, it forces high-fidelity and one-to-one mapping with respect to two cross-expression domains. Our method outperforms existing methods in both qualitative and quantitative analysis, marking a significant advancement in the field of cross-domain head reenactment.