 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Prism: Animating Vector Graphics by Stratifying Semantic Structure
Dec 16, 2025Scalable Vector Graphics (SVG) are central to modern web design, and the demand to animate them continues to grow as web environments become increasingly dynamic. Yet automating the animation of vector graphics remains challenging for vision-language models (VLMs) despite recent progress in code generation and motion planning. VLMs routinely mis-handle SVGs, since visually coherent parts are often fragmented into low-level shapes that offer little guidance of which elements should move together. In this paper, we introduce a framework that recovers the semantic structure required for reliable SVG animation and reveals the missing layer that current VLM systems overlook. This is achieved through a statistical aggregation of multiple weak part predictions, allowing the system to stably infer semantics from noisy predictions. By reorganizing SVGs into semantic groups, our approach enables VLMs to produce animations with far greater coherence. Our experiments demonstrate substantial gains over existing approaches, suggesting that semantic recovery is the key step that unlocks robust SVG animation and supports more interpretable interactions between VLMs and vector graphics.
DesignLab: Designing Slides Through Iterative Detection and Correction
Jul 23, 2025Designing high-quality presentation slides can be challenging for non-experts due to the complexity involved in navigating various design choices. Numerous automated tools can suggest layouts and color schemes, yet often lack the ability to refine their own output, which is a key aspect in real-world workflows. We propose DesignLab, which separates the design process into two roles, the design reviewer, who identifies design-related issues, and the design contributor who corrects them. This decomposition enables an iterative loop where the reviewer continuously detects issues and the contributor corrects them, allowing a draft to be further polished with each iteration, reaching qualities that were unattainable. We fine-tune large language models for these roles and simulate intermediate drafts by introducing controlled perturbations, enabling the design reviewer learn design errors and the contributor learn how to fix them. Our experiments show that DesignLab outperforms existing design-generation methods, including a commercial tool, by embracing the iterative nature of designing which can result in polished, professional slides.
Talk to Your Slides: Efficient Slide Editing Agent with Large Language Models
May 16, 2025Existing research on large language models (LLMs) for PowerPoint predominantly focuses on slide generation, overlooking the common yet tedious task of editing existing slides. We introduce Talk-to-Your-Slides, an LLM-powered agent that directly edits slides within active PowerPoint sessions through COM communication. Our system employs a two-level approach: (1) high-level processing where an LLM agent interprets instructions and formulates editing plans, and (2) low-level execution where Python scripts directly manipulate PowerPoint objects. Unlike previous methods relying on predefined operations, our approach enables more flexible and contextually-aware editing. To facilitate evaluation, we present TSBench, a human-annotated dataset of 379 diverse editing instructions with corresponding slide variations. Experimental results demonstrate that Talk-to-Your-Slides significantly outperforms baseline methods in execution success rate, instruction fidelity, and editing efficiency. Our code and benchmark are available at https://anonymous.4open.science/r/talk-to-your-slides/
SphereDiff: Tuning-free Omnidirectional Panoramic Image and Video Generation via Spherical Latent Representation
Apr 19, 2025The increasing demand for AR/VR applications has highlighted the need for high-quality 360-degree panoramic content. However, generating high-quality 360-degree panoramic images and videos remains a challenging task due to the severe distortions introduced by equirectangular projection (ERP). Existing approaches either fine-tune pretrained diffusion models on limited ERP datasets or attempt tuning-free methods that still rely on ERP latent representations, leading to discontinuities near the poles. In this paper, we introduce SphereDiff, a novel approach for seamless 360-degree panoramic image and video generation using state-of-the-art diffusion models without additional tuning. We define a spherical latent representation that ensures uniform distribution across all perspectives, mitigating the distortions inherent in ERP. We extend MultiDiffusion to spherical latent space and propose a spherical latent sampling method to enable direct use of pretrained diffusion models. Moreover, we introduce distortion-aware weighted averaging to further improve the generation quality in the projection process. Our method outperforms existing approaches in generating 360-degree panoramic content while maintaining high fidelity, making it a robust solution for immersive AR/VR applications. The code is available here. https://github.com/pmh9960/SphereDiff
Enabling Region-Specific Control via Lassos in Point-Based Colorization
Dec 18, 2024



Point-based interactive colorization techniques allow users to effortlessly colorize grayscale images using user-provided color hints. However, point-based methods often face challenges when different colors are given to semantically similar areas, leading to color intermingling and unsatisfactory results-an issue we refer to as color collapse. The fundamental cause of color collapse is the inadequacy of points for defining the boundaries for each color. To mitigate color collapse, we introduce a lasso tool that can control the scope of each color hint. Additionally, we design a framework that leverages the user-provided lassos to localize the attention masks. The experimental results show that using a single lasso is as effective as applying 4.18 individual color hints and can achieve the desired outcomes in 30% less time than using points alone.
Generative Location Modeling for Spatially Aware Object Insertion
Oct 17, 2024



Generative models have become a powerful tool for image editing tasks, including object insertion. However, these methods often lack spatial awareness, generating objects with unrealistic locations and scales, or unintentionally altering the scene background. A key challenge lies in maintaining visual coherence, which requires both a geometrically suitable object location and a high-quality image edit. In this paper, we focus on the former, creating a location model dedicated to identifying realistic object locations. Specifically, we train an autoregressive model that generates bounding box coordinates, conditioned on the background image and the desired object class. This formulation allows to effectively handle sparse placement annotations and to incorporate implausible locations into a preference dataset by performing direct preference optimization. Our extensive experiments demonstrate that our generative location model, when paired with an inpainting method, substantially outperforms state-of-the-art instruction-tuned models and location modeling baselines in object insertion tasks, delivering accurate and visually coherent results.
Scaling Up Personalized Aesthetic Assessment via Task Vector Customization
Jul 09, 2024The task of personalized image aesthetic assessment seeks to tailor aesthetic score prediction models to match individual preferences with just a few user-provided inputs. However, the scalability and generalization capabilities of current approaches are considerably restricted by their reliance on an expensive curated database. To overcome this long-standing scalability challenge, we present a unique approach that leverages readily available databases for general image aesthetic assessment and image quality assessment. Specifically, we view each database as a distinct image score regression task that exhibits varying degrees of personalization potential. By determining optimal combinations of task vectors, known to represent specific traits of each database, we successfully create personalized models for individuals. This approach of integrating multiple models allows us to harness a substantial amount of data. Our extensive experiments demonstrate the effectiveness of our approach in generalizing to previously unseen domains-a challenge previous approaches have struggled to achieve-making it highly applicable to real-world scenarios. Our novel approach significantly advances the field by offering scalable solutions for personalized aesthetic assessment and establishing high standards for future research. https://yeolj00.github.io/personal-projects/personalized-aesthetics/
Regularized Training with Generated Datasets for Name-Only Transfer of Vision-Language Models
Jun 08, 2024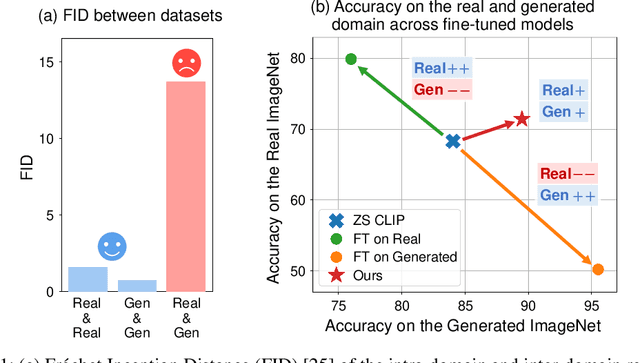
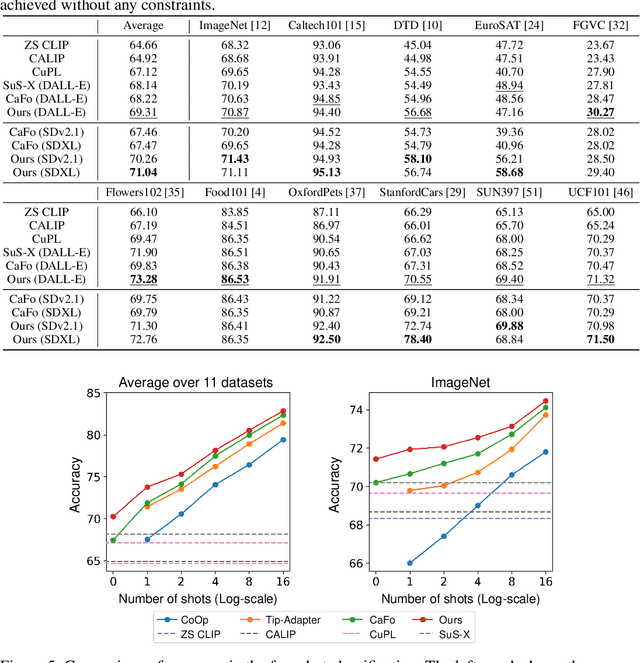
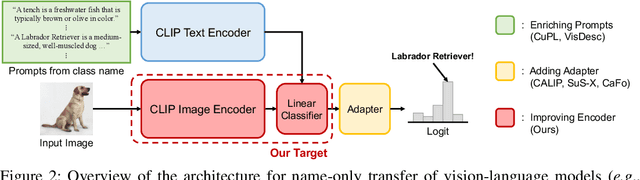
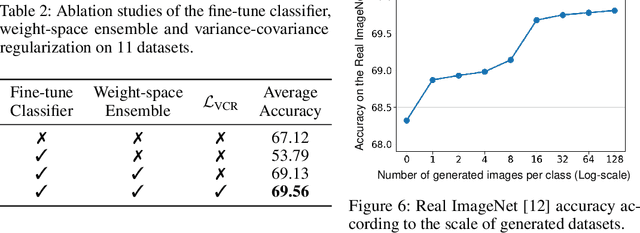
Recent advancements in text-to-image generation have inspired researchers to generate datasets tailored for perception models using generative models, which prove particularly valuable in scenarios where real-world data is limited. In this study, our goal is to address the challenges when fine-tuning vision-language models (e.g., CLIP) on generated datasets. Specifically, we aim to fine-tune vision-language models to a specific classification model without access to any real images, also known as name-only transfer. However, despite the high fidelity of generated images, we observed a significant performance degradation when fine-tuning the model using the generated datasets due to the domain gap between real and generated images. To overcome the domain gap, we provide two regularization methods for training and post-training, respectively. First, we leverage the domain-agnostic knowledge from the original pre-trained vision-language model by conducting the weight-space ensemble of the fine-tuned model on the generated dataset with the original pre-trained model at the post-training. Secondly, we reveal that fine-tuned models with high feature diversity score high performance in the real domain, which indicates that increasing feature diversity prevents learning the generated domain-specific knowledge. Thus, we encourage feature diversity by providing additional regularization at training time. Extensive experiments on various classification datasets and various text-to-image generation models demonstrated that our analysis and regularization techniques effectively mitigate the domain gap, which has long been overlooked, and enable us to achieve state-of-the-art performance by training with generated images. Code is available at https://github.com/pmh9960/regft-for-gen
Learning to Generate Semantic Layouts for Higher Text-Image Correspondence in Text-to-Image Synthesis
Aug 16, 2023Existing text-to-image generation approaches have set high standards for photorealism and text-image correspondence, largely benefiting from web-scale text-image datasets, which can include up to 5~billion pairs. However, text-to-image generation models trained on domain-specific datasets, such as urban scenes, medical images, and faces, still suffer from low text-image correspondence due to the lack of text-image pairs. Additionally, collecting billions of text-image pairs for a specific domain can be time-consuming and costly. Thus, ensuring high text-image correspondence without relying on web-scale text-image datasets remains a challenging task. In this paper, we present a novel approach for enhancing text-image correspondence by leveraging available semantic layouts. Specifically, we propose a Gaussian-categorical diffusion process that simultaneously generates both images and corresponding layout pairs. Our experiments reveal that we can guide text-to-image generation models to be aware of the semantics of different image regions, by training the model to generate semantic labels for each pixel. We demonstrate that our approach achieves higher text-image correspondence compared to existing text-to-image generation approaches in the Multi-Modal CelebA-HQ and the Cityscapes dataset, where text-image pairs are scarce. Codes are available in this https://pmh9960.github.io/research/GCDP
iColoriT: Towards Propagating Local Hint to the Right Region in Interactive Colorization by Leveraging Vision Transformer
Jul 15, 2022
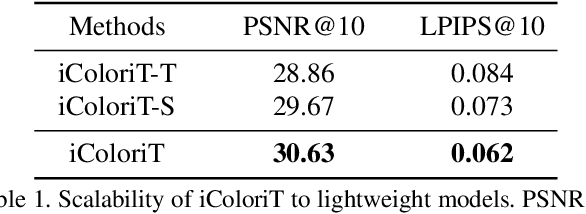


Point-interactive image colorization aims to colorize grayscale images when a user provides the colors for specific locations. It is essential for point-interactive colorization methods to appropriately propagate user-provided colors (i.e., user hints) in the entire image to obtain a reasonably colorized image with minimal user effort. However, existing approaches often produce partially colorized results due to the inefficient design of stacking convolutional layers to propagate hints to distant relevant regions. To address this problem, we present iColoriT, a novel point-interactive colorization Vision Transformer capable of propagating user hints to relevant regions, leveraging the global receptive field of Transformers. The self-attention mechanism of Transformers enables iColoriT to selectively colorize relevant regions with only a few local hints. Our approach colorizes images in real-time by utilizing pixel shuffling, an efficient upsampling technique that replaces the decoder architecture. Also, in order to mitigate the artifacts caused by pixel shuffling with large upsampling ratios, we present the local stabilizing layer. Extensive quantitative and qualitative results demonstrate that our approach highly outperforms existing methods for point-interactive colorization, producing accurately colorized images with a user's minimal effort.