 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Representation-Based Domain Generalization on Gaze Estimation
Aug 30, 2024The availability of extensive datasets containing gaze information for each subject has significantly enhanced gaze estimation accuracy. However, the discrepancy between domains severely affects a model's performance explicitly trained for a particular domain. In this paper, we propose the Causal Representation-Based Domain Generalization on Gaze Estimation (CauGE) framework designed based on the general principle of causal mechanisms, which is consistent with the domain difference. We employ an adversarial training manner and an additional penalizing term to extract domain-invariant features. After extracting features, we position the attention layer to make features sufficient for inferring the actual gaze. By leveraging these modules, CauGE ensures that the neural networks learn from representations that meet the causal mechanisms' general principles. By this, CauGE generalizes across domains by extracting domain-invariant features, and spurious correlations cannot influence the model. Our method achieves state-of-the-art performance in the domain generalization on gaze estimation benchmark.
Boost Your Own Human Image Generation Model via Direct Preference Optimization with AI Feedback
May 30, 2024The generation of high-quality human images through text-to-image (T2I) methods is a significant yet challenging task. Distinct from general image generation, human image synthesis must satisfy stringent criteria related to human pose, anatomy, and alignment with textual prompts, making it particularly difficult to achieve realistic results. Recent advancements in T2I generation based on diffusion models have shown promise, yet challenges remain in meeting human-specific preferences. In this paper, we introduce a novel approach tailored specifically for human image generation utilizing Direct Preference Optimization (DPO). Specifically, we introduce an efficient method for constructing a specialized DPO dataset for training human image generation models without the need for costly human feedback. We also propose a modified loss function that enhances the DPO training process by minimizing artifacts and improving image fidelity. Our method demonstrates its versatility and effectiveness in generating human images, including personalized text-to-image generation. Through comprehensive evaluations, we show that our approach significantly advances the state of human image generation, achieving superior results in terms of natural anatomies, poses, and text-image alignment.
Improving Face Recognition with Large Age Gaps by Learning to Distinguish Children
Oct 22, 2021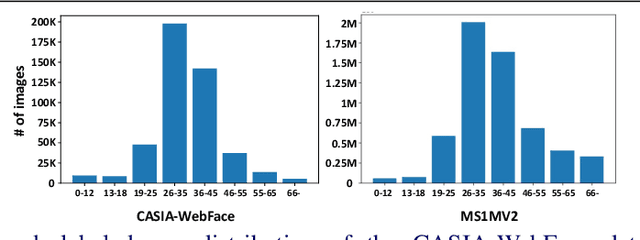
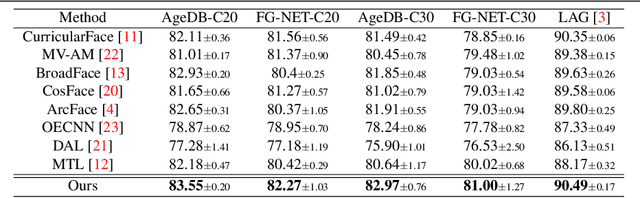
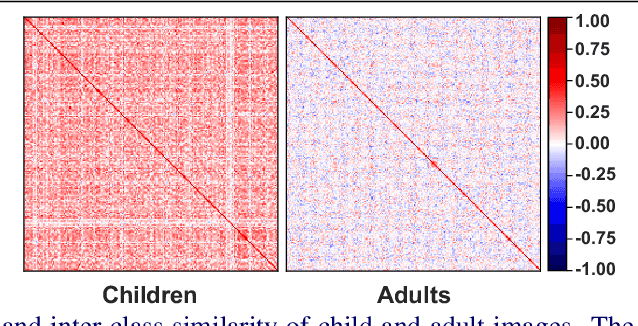
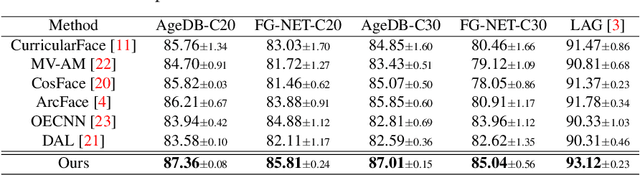
Despite the unprecedented improvement of face recognition, existing face recognition models still show considerably low performances in determining whether a pair of child and adult images belong to the same identity. Previous approaches mainly focused on increasing the similarity between child and adult images of a given identity to overcome the discrepancy of facial appearances due to aging. However, we observe that reducing the similarity between child images of different identities is crucial for learning distinct features among children and thus improving face recognition performance in child-adult pairs. Based on this intuition, we propose a novel loss function called the Inter-Prototype loss which minimizes the similarity between child images. Unlike the previous studies, the Inter-Prototype loss does not require additional child images or training additional learnable parameters. Our extensive experiments and in-depth analyses show that our approach outperforms existing baselines in face recognition with child-adult pairs. Our code and newly-constructed test sets of child-adult pairs are available at https://github.com/leebebeto/Inter-Prototype.