 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoost Your Own Human Image Generation Model via Direct Preference Optimization with AI Feedback
May 30, 2024The generation of high-quality human images through text-to-image (T2I) methods is a significant yet challenging task. Distinct from general image generation, human image synthesis must satisfy stringent criteria related to human pose, anatomy, and alignment with textual prompts, making it particularly difficult to achieve realistic results. Recent advancements in T2I generation based on diffusion models have shown promise, yet challenges remain in meeting human-specific preferences. In this paper, we introduce a novel approach tailored specifically for human image generation utilizing Direct Preference Optimization (DPO). Specifically, we introduce an efficient method for constructing a specialized DPO dataset for training human image generation models without the need for costly human feedback. We also propose a modified loss function that enhances the DPO training process by minimizing artifacts and improving image fidelity. Our method demonstrates its versatility and effectiveness in generating human images, including personalized text-to-image generation. Through comprehensive evaluations, we show that our approach significantly advances the state of human image generation, achieving superior results in terms of natural anatomies, poses, and text-image alignment.
MFIM: Megapixel Facial Identity Manipulation
Aug 03, 2023Face swapping is a task that changes a facial identity of a given image to that of another person. In this work, we propose a novel face-swapping framework called Megapixel Facial Identity Manipulation (MFIM). The face-swapping model should achieve two goals. First, it should be able to generate a high-quality image. We argue that a model which is proficient in generating a megapixel image can achieve this goal. However, generating a megapixel image is generally difficult without careful model design. Therefore, our model exploits pretrained StyleGAN in the manner of GAN-inversion to effectively generate a megapixel image. Second, it should be able to effectively transform the identity of a given image. Specifically, it should be able to actively transform ID attributes (e.g., face shape and eyes) of a given image into those of another person, while preserving ID-irrelevant attributes (e.g., pose and expression). To achieve this goal, we exploit 3DMM that can capture various facial attributes. Specifically, we explicitly supervise our model to generate a face-swapped image with the desirable attributes using 3DMM. We show that our model achieves state-of-the-art performance through extensive experiments. Furthermore, we propose a new operation called ID mixing, which creates a new identity by semantically mixing the identities of several people. It allows the user to customize the new identity.
MISO: Mutual Information Loss with Stochastic Style Representations for Multimodal Image-to-Image Translation
Feb 11, 2019
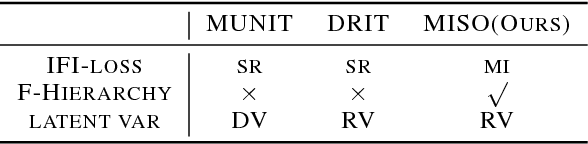

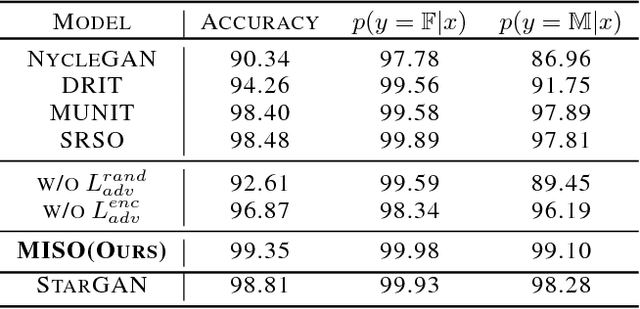
Unpaired multimodal image-to-image translation is a task of translating a given image in a source domain into diverse images in the target domain, overcoming the limitation of one-to-one mapping. Existing multimodal translation models are mainly based on the disentangled representations with an image reconstruction loss. We propose two approaches to improve multimodal translation quality. First, we use a content representation from the source domain conditioned on a style representation from the target domain. Second, rather than using a typical image reconstruction loss, we design MILO (Mutual Information LOss), a new stochastically-defined loss function based on information theory. This loss function directly reflects the interpretation of latent variables as a random variable. We show that our proposed model Mutual Information with StOchastic Style Representation(MISO) achieves state-of-the-art performance through extensive experiments on various real-world datasets.