 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Unlabeled Faces for Novel Attribute Discovery
Dec 06, 2019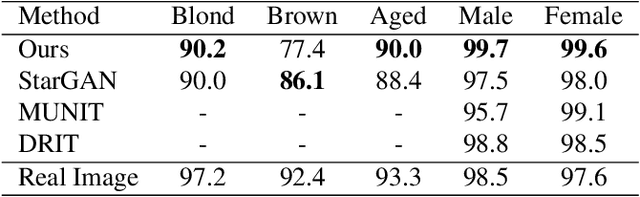

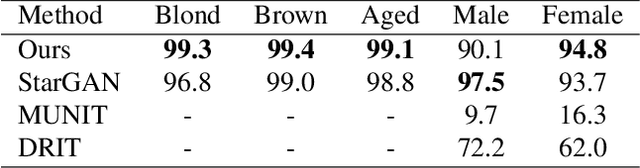

Despite remarkable success in unpaired image-to-image translation, existing systems still require a large amount of labeled images. This is a bottleneck for their real-world applications; in practice, a model trained on labeled CelebA dataset does not work well for test images from a different distribution -- greatly limiting their application to unlabeled images of a much larger quantity. In this paper, we attempt to alleviate this necessity for labeled data in the facial image translation domain. We aim to explore the degree to which you can discover novel attributes from unlabeled faces and perform high-quality translation. To this end, we use prior knowledge about the visual world as guidance to discover novel attributes and transfer them via a novel normalization method. Experiments show that our method trained on unlabeled data produces high-quality translations, preserves identity, and be perceptually realistic as good as, or better than, state-of-the-art methods trained on labeled data.
Coloring With Limited Data: Few-Shot Colorization via Memory-Augmented Networks
Jun 09, 2019
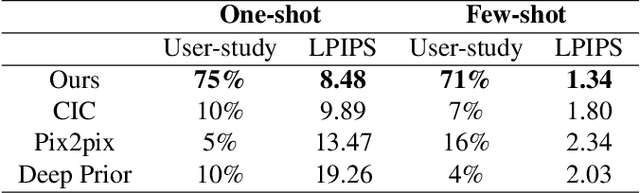

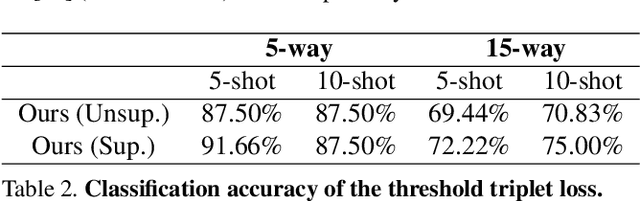
Despite recent advancements in deep learning-based automatic colorization, they are still limited when it comes to few-shot learning. Existing models require a significant amount of training data. To tackle this issue, we present a novel memory-augmented colorization model MemoPainter that can produce high-quality colorization with limited data. In particular, our model is able to capture rare instances and successfully colorize them. We also propose a novel threshold triplet loss that enables unsupervised training of memory networks without the need of class labels. Experiments show that our model has superior quality in both few-shot and one-shot colorization tasks.
MISO: Mutual Information Loss with Stochastic Style Representations for Multimodal Image-to-Image Translation
Feb 11, 2019
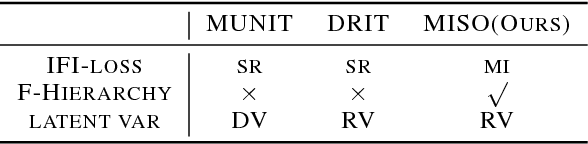

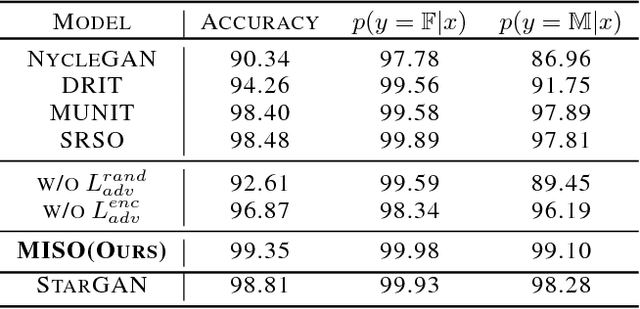
Unpaired multimodal image-to-image translation is a task of translating a given image in a source domain into diverse images in the target domain, overcoming the limitation of one-to-one mapping. Existing multimodal translation models are mainly based on the disentangled representations with an image reconstruction loss. We propose two approaches to improve multimodal translation quality. First, we use a content representation from the source domain conditioned on a style representation from the target domain. Second, rather than using a typical image reconstruction loss, we design MILO (Mutual Information LOss), a new stochastically-defined loss function based on information theory. This loss function directly reflects the interpretation of latent variables as a random variable. We show that our proposed model Mutual Information with StOchastic Style Representation(MISO) achieves state-of-the-art performance through extensive experiments on various real-world datasets.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
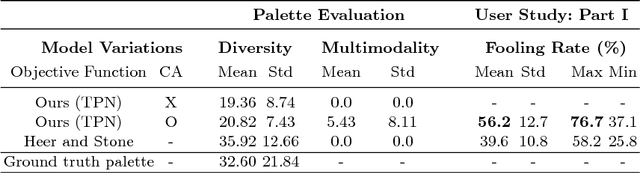


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures
MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation
May 08, 2018

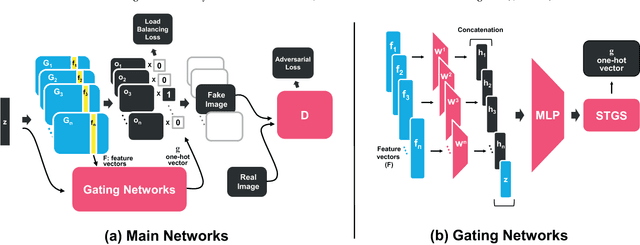
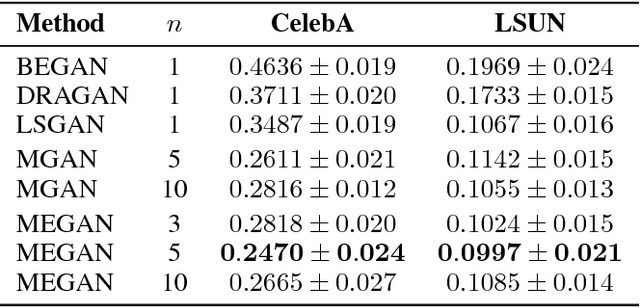
Recently, generative adversarial networks (GANs) have shown promising performance in generating realistic images. However, they often struggle in learning complex underlying modalities in a given dataset, resulting in poor-quality generated images. To mitigate this problem, we present a novel approach called mixture of experts GAN (MEGAN), an ensemble approach of multiple generator networks. Each generator network in MEGAN specializes in generating images with a particular subset of modalities, e.g., an image class. Instead of incorporating a separate step of handcrafted clustering of multiple modalities, our proposed model is trained through an end-to-end learning of multiple generators via gating networks, which is responsible for choosing the appropriate generator network for a given condition. We adopt the categorical reparameterization trick for a categorical decision to be made in selecting a generator while maintaining the flow of the gradients. We demonstrate that individual generators learn different and salient subparts of the data and achieve a multiscale structural similarity (MS-SSIM) score of 0.2470 for CelebA and a competitive unsupervised inception score of 8.33 in CIFAR-10.