 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Scene Text Recognition for Character-Level Long-Tailed Distribution
Mar 31, 2023Despite the recent remarkable improvements in scene text recognition (STR), the majority of the studies focused mainly on the English language, which only includes few number of characters. However, STR models show a large performance degradation on languages with a numerous number of characters (e.g., Chinese and Korean), especially on characters that rarely appear due to the long-tailed distribution of characters in such languages. To address such an issue, we conducted an empirical analysis using synthetic datasets with different character-level distributions (e.g., balanced and long-tailed distributions). While increasing a substantial number of tail classes without considering the context helps the model to correctly recognize characters individually, training with such a synthetic dataset interferes the model with learning the contextual information (i.e., relation among characters), which is also important for predicting the whole word. Based on this motivation, we propose a novel Context-Aware and Free Experts Network (CAFE-Net) using two experts: 1) context-aware expert learns the contextual representation trained with a long-tailed dataset composed of common words used in everyday life and 2) context-free expert focuses on correctly predicting individual characters by utilizing a dataset with a balanced number of characters. By training two experts to focus on learning contextual and visual representations, respectively, we propose a novel confidence ensemble method to compensate the limitation of each expert. Through the experiments, we demonstrate that CAFE-Net improves the STR performance on languages containing numerous number of characters. Moreover, we show that CAFE-Net is easily applicable to various STR models.
AnimeCeleb: Large-Scale Animation CelebFaces Dataset via Controllable 3D Synthetic Models
Nov 15, 2021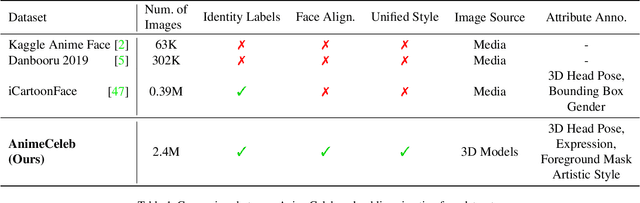
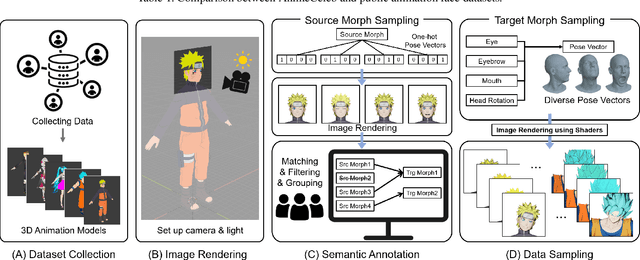
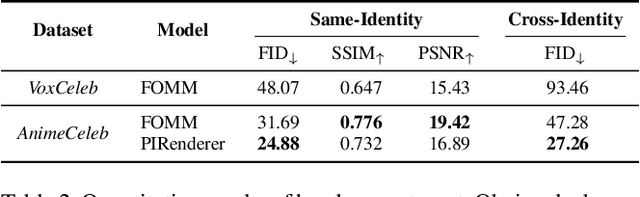

Despite remarkable success in deep learning-based face-related models, these models are still limited to the domain of real human faces. On the other hand, the domain of animation faces has been studied less intensively due to the absence of a well-organized dataset. In this paper, we present a large-scale animation celebfaces dataset (AnimeCeleb) via controllable synthetic animation models to boost research on the animation face domain. To facilitate the data generation process, we build a semi-automatic pipeline based on an open 3D software and a developed annotation system. This leads to constructing a large-scale animation face dataset that includes multi-pose and multi-style animation faces with rich annotations. Experiments suggest that our dataset is applicable to various animation-related tasks such as head reenactment and colorization.
Exploring Unlabeled Faces for Novel Attribute Discovery
Dec 06, 2019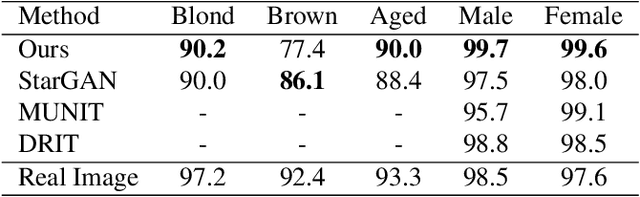

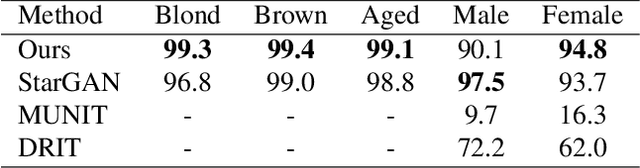

Despite remarkable success in unpaired image-to-image translation, existing systems still require a large amount of labeled images. This is a bottleneck for their real-world applications; in practice, a model trained on labeled CelebA dataset does not work well for test images from a different distribution -- greatly limiting their application to unlabeled images of a much larger quantity. In this paper, we attempt to alleviate this necessity for labeled data in the facial image translation domain. We aim to explore the degree to which you can discover novel attributes from unlabeled faces and perform high-quality translation. To this end, we use prior knowledge about the visual world as guidance to discover novel attributes and transfer them via a novel normalization method. Experiments show that our method trained on unlabeled data produces high-quality translations, preserves identity, and be perceptually realistic as good as, or better than, state-of-the-art methods trained on labeled data.
Coloring With Limited Data: Few-Shot Colorization via Memory-Augmented Networks
Jun 09, 2019
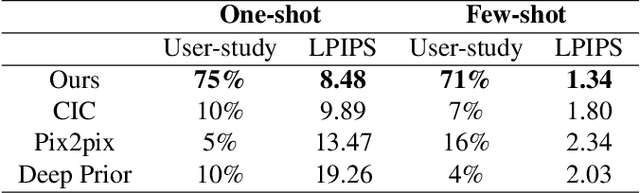

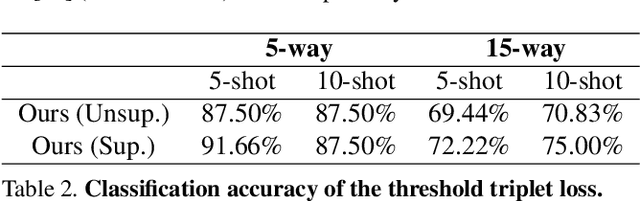
Despite recent advancements in deep learning-based automatic colorization, they are still limited when it comes to few-shot learning. Existing models require a significant amount of training data. To tackle this issue, we present a novel memory-augmented colorization model MemoPainter that can produce high-quality colorization with limited data. In particular, our model is able to capture rare instances and successfully colorize them. We also propose a novel threshold triplet loss that enables unsupervised training of memory networks without the need of class labels. Experiments show that our model has superior quality in both few-shot and one-shot colorization tasks.