 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance
Mar 24, 2026Despite decades of work, surveillance still struggles to find specific targets across long, multi-camera video. Prior methods -- tracking pipelines, CLIP based models, and VideoRAG -- require heavy manual filtering, capture only shallow attributes, and fail at temporal reasoning. Real-world searches are inherently multimodal (e.g., "When does this person join the fight?" with the person's image), yet this setting remains underexplored. Also, there are no proper benchmarks to evaluate those setting - asking video with multimodal queries. To address this gap, we introduce ForeSeaQA, a new benchmark specifically designed for video QA with image-and-text queries and timestamped annotations of key events. The dataset consists of long-horizon surveillance footage paired with diverse multimodal questions, enabling systematic evaluation of retrieval, temporal grounding, and multimodal reasoning in realistic forensic conditions. Not limited to this benchmark, we propose ForeSea, an AI forensic search system with a 3-stage, plug-and-play pipeline. (1) A tracking module filters irrelevant footage; (2) a multimodal embedding module indexes the remaining clips; and (3) during inference, the system retrieves top-K candidate clips for a Video Large Language Model (VideoLLM) to answer queries and localize events. On ForeSeaQA, ForeSea improves accuracy by 3.5% and temporal IoU by 11.0 over prior VideoRAG models. To our knowledge, ForeSeaQA is the first benchmark to support complex multimodal queries with precise temporal grounding, and ForeSea is the first VideoRAG system built to excel in this setting.
Concept-Aware LoRA for Domain-Aligned Segmentation Dataset Generation
Mar 28, 2025This paper addresses the challenge of data scarcity in semantic segmentation by generating datasets through text-to-image (T2I) generation models, reducing image acquisition and labeling costs. Segmentation dataset generation faces two key challenges: 1) aligning generated samples with the target domain and 2) producing informative samples beyond the training data. Fine-tuning T2I models can help generate samples aligned with the target domain. However, it often overfits and memorizes training data, limiting their ability to generate diverse and well-aligned samples. To overcome these issues, we propose Concept-Aware LoRA (CA-LoRA), a novel fine-tuning approach that selectively identifies and updates only the weights associated with necessary concepts (e.g., style or viewpoint) for domain alignment while preserving the pretrained knowledge of the T2I model to produce informative samples. We demonstrate its effectiveness in generating datasets for urban-scene segmentation, outperforming baseline and state-of-the-art methods in in-domain (few-shot and fully-supervised) settings, as well as in domain generalization tasks, especially under challenging conditions such as adverse weather and varying illumination, further highlighting its superiority.
Towards Open-Set Test-Time Adaptation Utilizing the Wisdom of Crowds in Entropy Minimization
Sep 04, 2023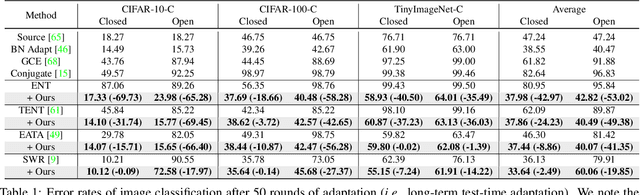
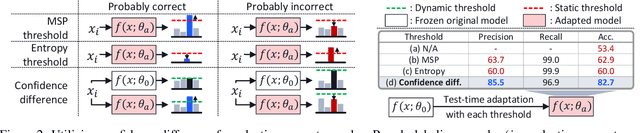
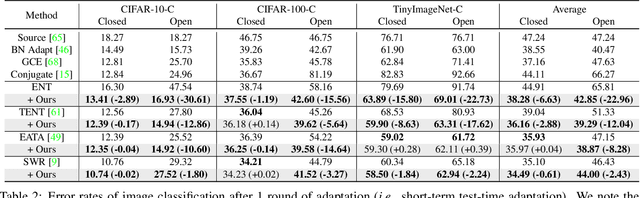
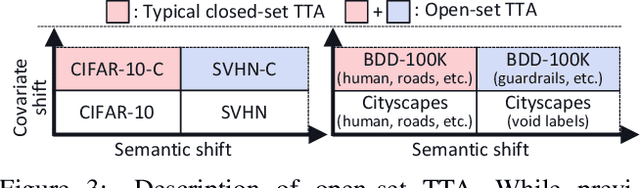
Test-time adaptation (TTA) methods, which generally rely on the model's predictions (e.g., entropy minimization) to adapt the source pretrained model to the unlabeled target domain, suffer from noisy signals originating from 1) incorrect or 2) open-set predictions. Long-term stable adaptation is hampered by such noisy signals, so training models without such error accumulation is crucial for practical TTA. To address these issues, including open-set TTA, we propose a simple yet effective sample selection method inspired by the following crucial empirical finding. While entropy minimization compels the model to increase the probability of its predicted label (i.e., confidence values), we found that noisy samples rather show decreased confidence values. To be more specific, entropy minimization attempts to raise the confidence values of an individual sample's prediction, but individual confidence values may rise or fall due to the influence of signals from numerous other predictions (i.e., wisdom of crowds). Due to this fact, noisy signals misaligned with such 'wisdom of crowds', generally found in the correct signals, fail to raise the individual confidence values of wrong samples, despite attempts to increase them. Based on such findings, we filter out the samples whose confidence values are lower in the adapted model than in the original model, as they are likely to be noisy. Our method is widely applicable to existing TTA methods and improves their long-term adaptation performance in both image classification (e.g., 49.4% reduced error rates with TENT) and semantic segmentation (e.g., 11.7% gain in mIoU with TENT).
Improving Scene Text Recognition for Character-Level Long-Tailed Distribution
Mar 31, 2023Despite the recent remarkable improvements in scene text recognition (STR), the majority of the studies focused mainly on the English language, which only includes few number of characters. However, STR models show a large performance degradation on languages with a numerous number of characters (e.g., Chinese and Korean), especially on characters that rarely appear due to the long-tailed distribution of characters in such languages. To address such an issue, we conducted an empirical analysis using synthetic datasets with different character-level distributions (e.g., balanced and long-tailed distributions). While increasing a substantial number of tail classes without considering the context helps the model to correctly recognize characters individually, training with such a synthetic dataset interferes the model with learning the contextual information (i.e., relation among characters), which is also important for predicting the whole word. Based on this motivation, we propose a novel Context-Aware and Free Experts Network (CAFE-Net) using two experts: 1) context-aware expert learns the contextual representation trained with a long-tailed dataset composed of common words used in everyday life and 2) context-free expert focuses on correctly predicting individual characters by utilizing a dataset with a balanced number of characters. By training two experts to focus on learning contextual and visual representations, respectively, we propose a novel confidence ensemble method to compensate the limitation of each expert. Through the experiments, we demonstrate that CAFE-Net improves the STR performance on languages containing numerous number of characters. Moreover, we show that CAFE-Net is easily applicable to various STR models.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
Mar 13, 2023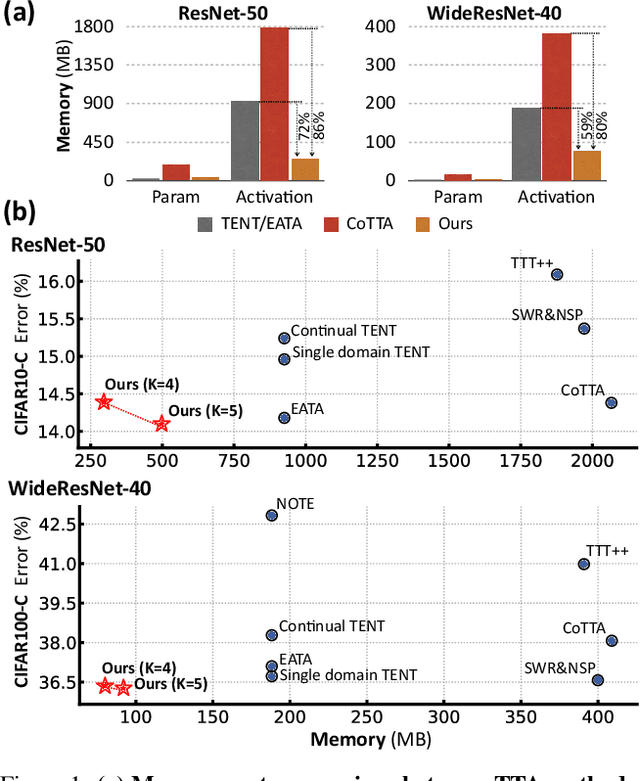
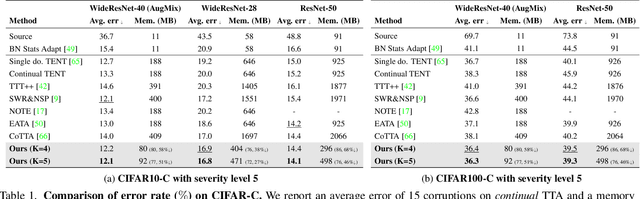

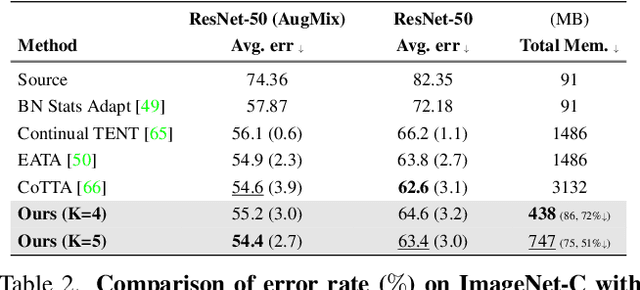
This paper presents a simple yet effective approach that improves continual test-time adaptation (TTA) in a memory-efficient manner. TTA may primarily be conducted on edge devices with limited memory, so reducing memory is crucial but has been overlooked in previous TTA studies. In addition, long-term adaptation often leads to catastrophic forgetting and error accumulation, which hinders applying TTA in real-world deployments. Our approach consists of two components to address these issues. First, we present lightweight meta networks that can adapt the frozen original networks to the target domain. This novel architecture minimizes memory consumption by decreasing the size of intermediate activations required for backpropagation. Second, our novel self-distilled regularization controls the output of the meta networks not to deviate significantly from the output of the frozen original networks, thereby preserving well-trained knowledge from the source domain. Without additional memory, this regularization prevents error accumulation and catastrophic forgetting, resulting in stable performance even in long-term test-time adaptation. We demonstrate that our simple yet effective strategy outperforms other state-of-the-art methods on various benchmarks for image classification and semantic segmentation tasks. Notably, our proposed method with ResNet-50 and WideResNet-40 takes 86% and 80% less memory than the recent state-of-the-art method, CoTTA.
Deep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023



Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
DASH: Visual Analytics for Debiasing Image Classification via User-Driven Synthetic Data Augmentation
Sep 14, 2022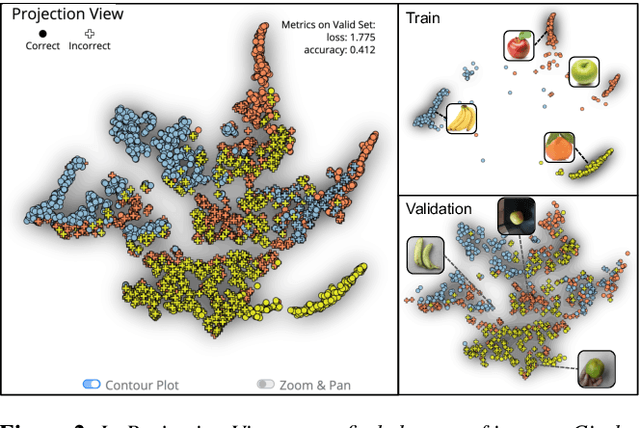
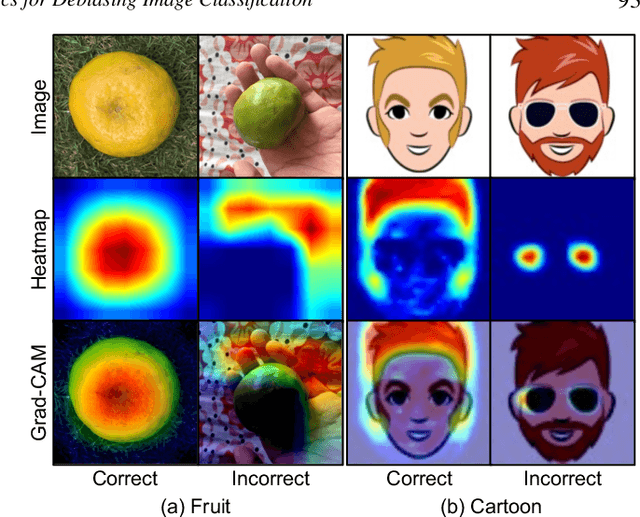
Image classification models often learn to predict a class based on irrelevant co-occurrences between input features and an output class in training data. We call the unwanted correlations "data biases," and the visual features causing data biases "bias factors." It is challenging to identify and mitigate biases automatically without human intervention. Therefore, we conducted a design study to find a human-in-the-loop solution. First, we identified user tasks that capture the bias mitigation process for image classification models with three experts. Then, to support the tasks, we developed a visual analytics system called DASH that allows users to visually identify bias factors, to iteratively generate synthetic images using a state-of-the-art image-to-image translation model, and to supervise the model training process for improving the classification accuracy. Our quantitative evaluation and qualitative study with ten participants demonstrate the usefulness of DASH and provide lessons for future work.
DebiasBench: Benchmark for Fair Comparison of Debiasing in Image Classification
Jun 08, 2022
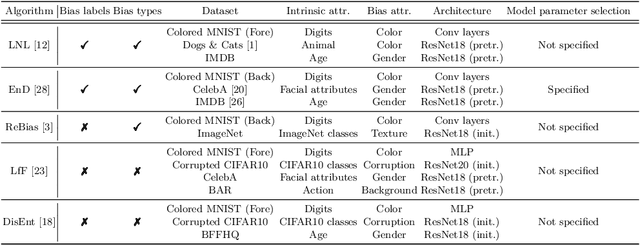
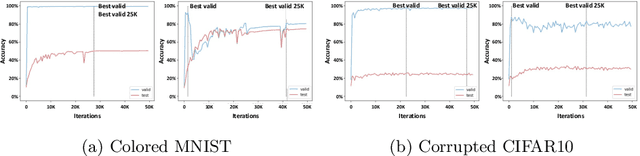
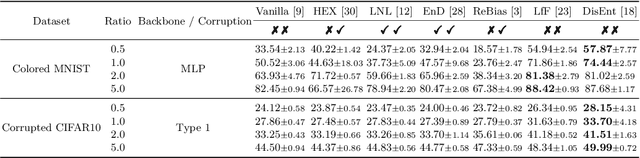
Image classifiers often rely overly on peripheral attributes that have a strong correlation with the target class (i.e., dataset bias) when making predictions. Recently, a myriad of studies focus on mitigating such dataset bias, the task of which is referred to as debiasing. However, these debiasing methods often have inconsistent experimental settings (e.g., datasets and neural network architectures). Additionally, most of the previous studies in debiasing do not specify how they select their model parameters which involve early stopping and hyper-parameter tuning. The goal of this paper is to standardize the inconsistent experimental settings and propose a consistent model parameter selection criterion for debiasing. Based on such unified experimental settings and model parameter selection criterion, we build a benchmark named DebiasBench which includes five datasets and seven debiasing methods. We carefully conduct extensive experiments in various aspects and show that different state-of-the-art methods work best in different datasets, respectively. Even, the vanilla method, the method with no debiasing module, also shows competitive results in datasets with low bias severity. We publicly release the implementation of existing debiasing methods in DebiasBench to encourage future researchers in debiasing to conduct fair comparisons and further push the state-of-the-art performances.
CAFA: Class-Aware Feature Alignment for Test-Time Adaptation
Jun 01, 2022

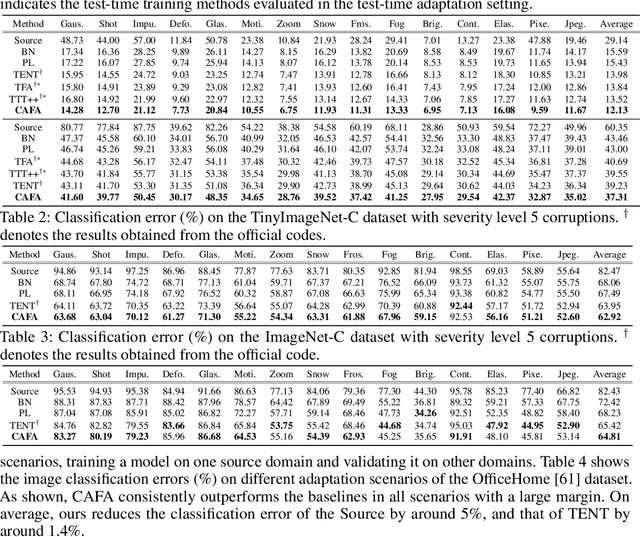

Despite recent advancements in deep learning, deep networks still suffer from performance degradation when they face new and different data from their training distributions. Addressing such a problem, test-time adaptation (TTA) aims to adapt a model to unlabeled test data on test time while making predictions simultaneously. TTA applies to pretrained networks without modifying their training procedures, which enables to utilize the already well-formed source distribution for adaptation. One possible approach is to align the representation space of test samples to the source distribution (\textit{i.e.,} feature alignment). However, performing feature alignments in TTA is especially challenging in that the access to labeled source data is restricted during adaptation. That is, a model does not have a chance to learn test data in a class-discriminative manner, which was feasible in other adaptation tasks (\textit{e.g.,} unsupervised domain adaptation) via supervised loss on the source data. Based on such an observation, this paper proposes \emph{a simple yet effective} feature alignment loss, termed as Class-Aware Feature Alignment (CAFA), which 1) encourages a model to learn target representations in a class-discriminative manner and 2) effectively mitigates the distribution shifts in test time, simultaneously. Our method does not require any hyper-parameters or additional losses, which are required in the previous approaches. We conduct extensive experiments and show our proposed method consistently outperforms existing baselines.
BiasEnsemble: Revisiting the Importance of Amplifying Bias for Debiasing
May 29, 2022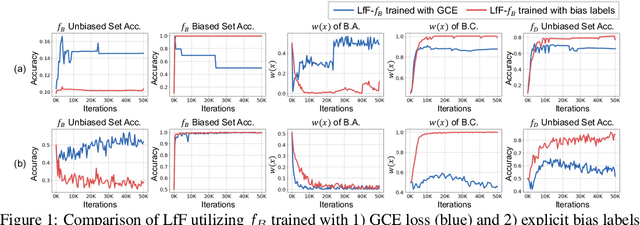
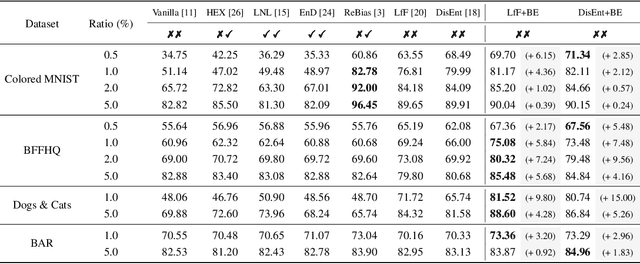
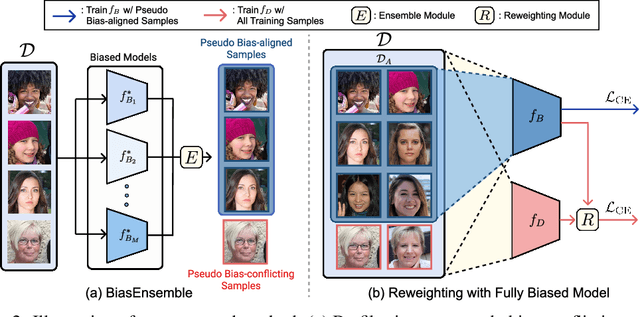

In image classification, "debiasing" aims to train a classifier to be less susceptible to dataset bias, the strong correlation between peripheral attributes of data samples and a target class. For example, even if the frog class in the dataset mainly consists of frog images with a swamp background (i.e., bias-aligned samples), a debiased classifier should be able to correctly classify a frog at a beach (i.e., bias-conflicting samples). Recent debiasing approaches commonly use two components for debiasing, a biased model $f_B$ and a debiased model $f_D$. $f_B$ is trained to focus on bias-aligned samples while $f_D$ is mainly trained with bias-conflicting samples by concentrating on samples which $f_B$ fails to learn, leading $f_D$ to be less susceptible to the dataset bias. While the state-of-the-art debiasing techniques have aimed to better train $f_D$, we focus on training $f_B$, an overlooked component until now. Our empirical analysis reveals that removing the bias-conflicting samples from the training set for $f_B$ is important for improving the debiasing performance of $f_D$. This is due to the fact that the bias-conflicting samples work as noisy samples for amplifying the bias for $f_B$. To this end, we propose a novel biased sample selection method BiasEnsemble which removes the bias-conflicting samples via leveraging additional biased models to construct a bias-amplified dataset for training $f_B$. Our simple yet effective approach can be directly applied to existing reweighting-based debiasing approaches, obtaining consistent performance boost and achieving the state-of-the-art performance on both synthetic and real-world datasets.