 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023



Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting
Oct 25, 2022



Time series forecasting has become a critical task due to its high practicality in real-world applications such as traffic, energy consumption, economics and finance, and disease analysis. Recent deep-learning-based approaches have shown remarkable success in time series forecasting. Nonetheless, due to the dynamics of time series data, deep networks still suffer from unstable training and overfitting. Inconsistent patterns appearing in real-world data lead the model to be biased to a particular pattern, thus limiting the generalization. In this work, we introduce the dynamic error bounds on training loss to address the overfitting issue in time series forecasting. Consequently, we propose a regularization method called WaveBound which estimates the adequate error bounds of training loss for each time step and feature at each iteration. By allowing the model to focus less on unpredictable data, WaveBound stabilizes the training process, thus significantly improving generalization. With the extensive experiments, we show that WaveBound consistently improves upon the existing models in large margins, including the state-of-the-art model.
Guiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.
Residual Correction in Real-Time Traffic Forecasting
Sep 12, 2022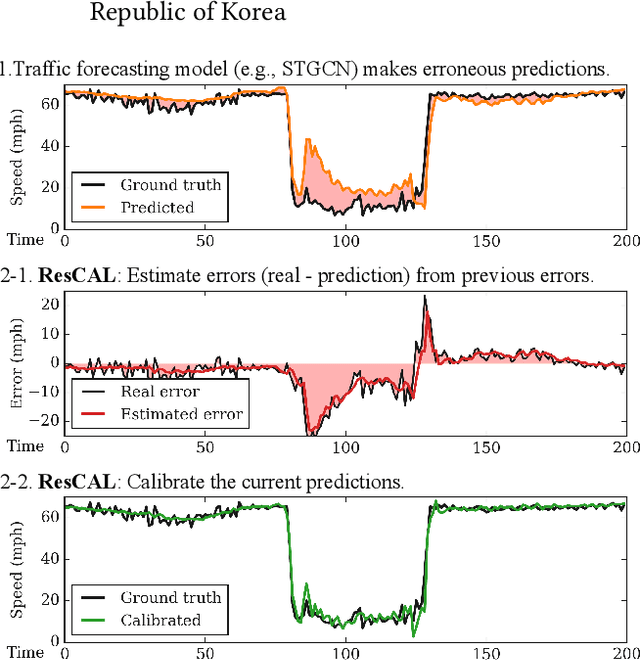
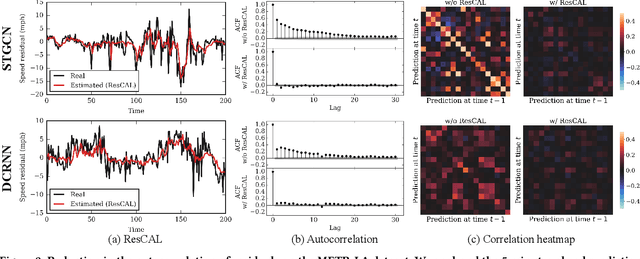
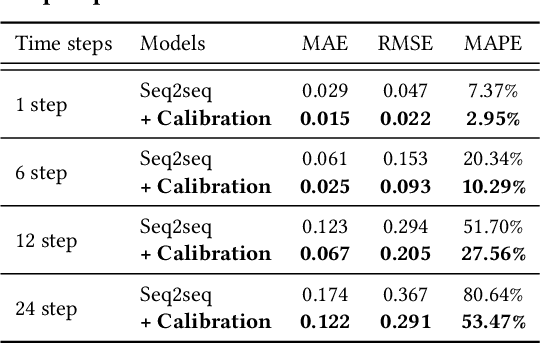
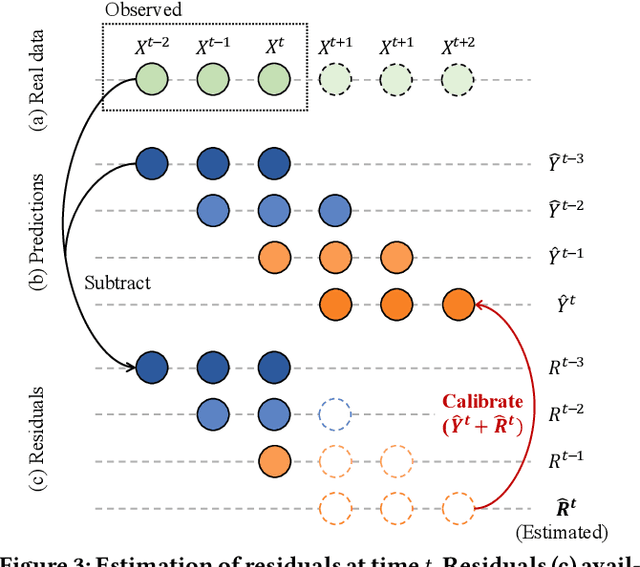
Predicting traffic conditions is tremendously challenging since every road is highly dependent on each other, both spatially and temporally. Recently, to capture this spatial and temporal dependency, specially designed architectures such as graph convolutional networks and temporal convolutional networks have been introduced. While there has been remarkable progress in traffic forecasting, we found that deep-learning-based traffic forecasting models still fail in certain patterns, mainly in event situations (e.g., rapid speed drops). Although it is commonly accepted that these failures are due to unpredictable noise, we found that these failures can be corrected by considering previous failures. Specifically, we observe autocorrelated errors in these failures, which indicates that some predictable information remains. In this study, to capture the correlation of errors, we introduce ResCAL, a residual estimation module for traffic forecasting, as a widely applicable add-on module to existing traffic forecasting models. Our ResCAL calibrates the prediction of the existing models in real time by estimating future errors using previous errors and graph signals. Extensive experiments on METR-LA and PEMS-BAY demonstrate that our ResCAL can correctly capture the correlation of errors and correct the failures of various traffic forecasting models in event situations.
Mining Multi-Label Samples from Single Positive Labels
Jun 12, 2022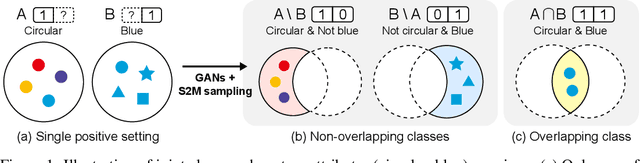
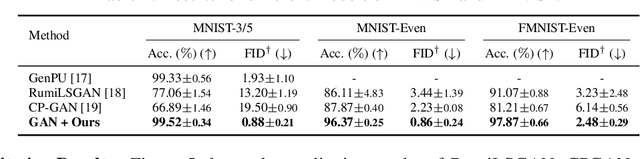
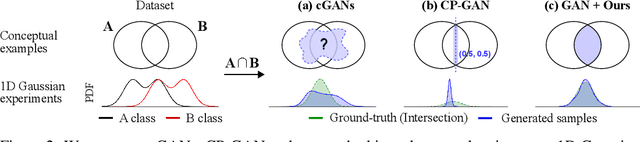
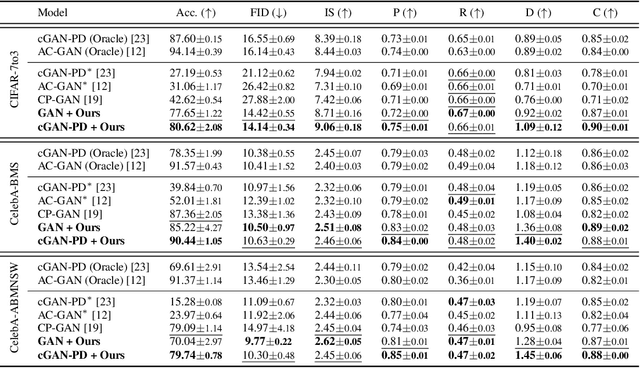
Conditional generative adversarial networks (cGANs) have shown superior results in class-conditional generation tasks. In order to simultaneously control multiple conditions, cGANs require multi-label training datasets, where multiple labels can be assigned to each data instance. Nevertheless, the tremendous annotation cost limits the accessibility of multi-label datasets in the real-world scenarios. Hence, we explore the practical setting called single positive setting, where each data instance is annotated by only one positive label with no explicit negative labels. To generate multi-label data in the single positive setting, we propose a novel sampling approach called single-to-multi-label (S2M) sampling, based on the Markov chain Monte Carlo method. As a widely applicable "add-on" method, our proposed S2M sampling enables existing unconditional and conditional GANs to draw high-quality multi-label data with a minimal annotation cost. Extensive experiments on real image datasets verify the effectiveness and correctness of our method, even when compared to a model trained with fully annotated datasets.