 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Users to Where to Give Color Hints for Efficient Interactive Sketch Colorization via Unsupervised Region Prioritization
Oct 25, 2022



Existing deep interactive colorization models have focused on ways to utilize various types of interactions, such as point-wise color hints, scribbles, or natural-language texts, as methods to reflect a user's intent at runtime. However, another approach, which actively informs the user of the most effective regions to give hints for sketch image colorization, has been under-explored. This paper proposes a novel model-guided deep interactive colorization framework that reduces the required amount of user interactions, by prioritizing the regions in a colorization model. Our method, called GuidingPainter, prioritizes these regions where the model most needs a color hint, rather than just relying on the user's manual decision on where to give a color hint. In our extensive experiments, we show that our approach outperforms existing interactive colorization methods in terms of the conventional metrics, such as PSNR and FID, and reduces required amount of interactions.
WaveBound: Dynamic Error Bounds for Stable Time Series Forecasting
Oct 25, 2022



Time series forecasting has become a critical task due to its high practicality in real-world applications such as traffic, energy consumption, economics and finance, and disease analysis. Recent deep-learning-based approaches have shown remarkable success in time series forecasting. Nonetheless, due to the dynamics of time series data, deep networks still suffer from unstable training and overfitting. Inconsistent patterns appearing in real-world data lead the model to be biased to a particular pattern, thus limiting the generalization. In this work, we introduce the dynamic error bounds on training loss to address the overfitting issue in time series forecasting. Consequently, we propose a regularization method called WaveBound which estimates the adequate error bounds of training loss for each time step and feature at each iteration. By allowing the model to focus less on unpredictable data, WaveBound stabilizes the training process, thus significantly improving generalization. With the extensive experiments, we show that WaveBound consistently improves upon the existing models in large margins, including the state-of-the-art model.
Mining Multi-Label Samples from Single Positive Labels
Jun 12, 2022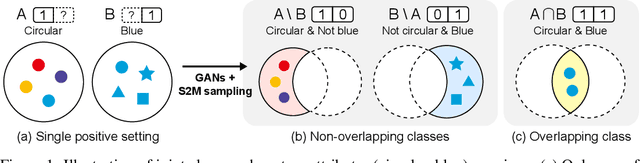
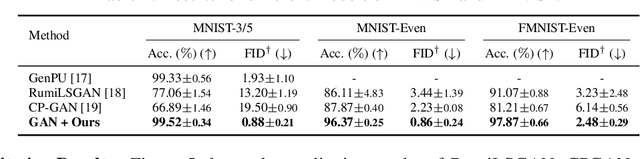
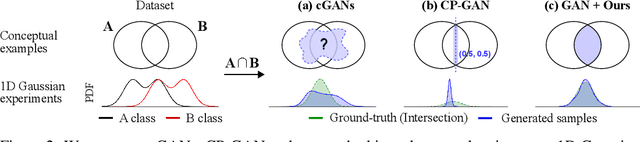
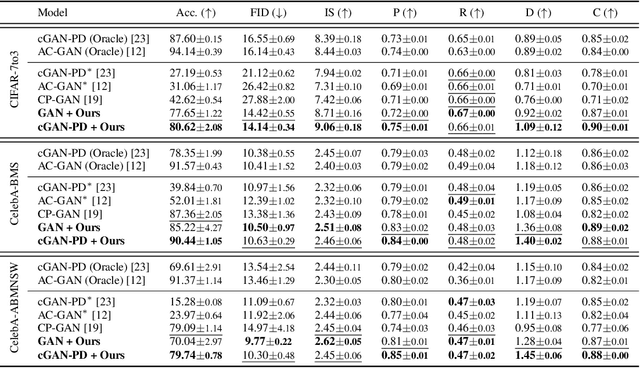
Conditional generative adversarial networks (cGANs) have shown superior results in class-conditional generation tasks. In order to simultaneously control multiple conditions, cGANs require multi-label training datasets, where multiple labels can be assigned to each data instance. Nevertheless, the tremendous annotation cost limits the accessibility of multi-label datasets in the real-world scenarios. Hence, we explore the practical setting called single positive setting, where each data instance is annotated by only one positive label with no explicit negative labels. To generate multi-label data in the single positive setting, we propose a novel sampling approach called single-to-multi-label (S2M) sampling, based on the Markov chain Monte Carlo method. As a widely applicable "add-on" method, our proposed S2M sampling enables existing unconditional and conditional GANs to draw high-quality multi-label data with a minimal annotation cost. Extensive experiments on real image datasets verify the effectiveness and correctness of our method, even when compared to a model trained with fully annotated datasets.
Meta-Learning for Low-Resource Unsupervised Neural MachineTranslation
Oct 18, 2020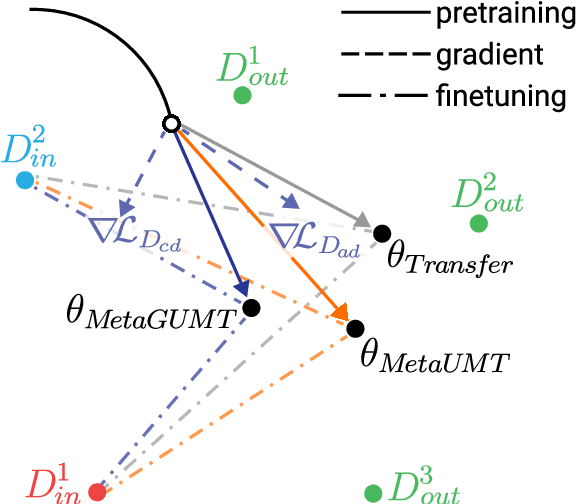
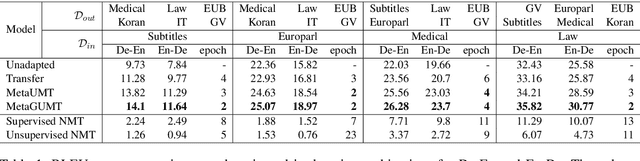
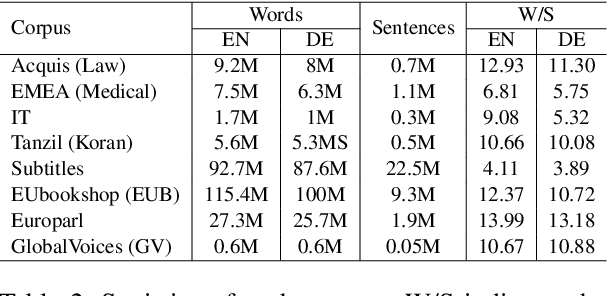

Unsupervised machine translation, which utilizes unpaired monolingual corpora as training data, has achieved comparable performance against supervised machine translation. However, it still suffers from data-scarce domains. To address this issue, this paper presents a meta-learning algorithm for unsupervised neural machine translation (UNMT) that trains the model to adapt to another domain by utilizing only a small amount of training data. We assume that domain-general knowledge is a significant factor in handling data-scarce domains. Hence, we extend the meta-learning algorithm, which utilizes knowledge learned from high-resource domains to boost the performance of low-resource UNMT. Our model surpasses a transfer learning-based approach by up to 2-4 BLEU scores. Extensive experimental results show that our proposed algorithm is pertinent for fast adaptation and consistently outperforms other baseline models.
Towards Lightweight Lane Detection by Optimizing Spatial Embedding
Aug 27, 2020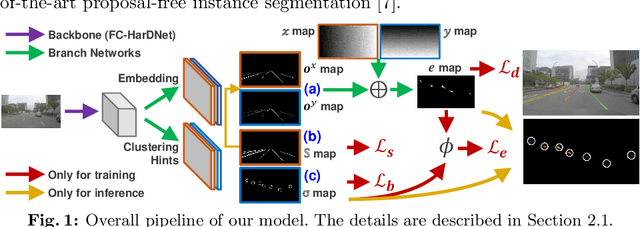


A number of lane detection methods depend on a proposal-free instance segmentation because of its adaptability to flexible object shape, occlusion, and real-time application. This paper addresses the problem that pixel embedding in proposal-free instance segmentation based lane detection is difficult to optimize. A translation invariance of convolution, which is one of the supposed strengths, causes challenges in optimizing pixel embedding. In this work, we propose a lane detection method based on proposal-free instance segmentation, directly optimizing spatial embedding of pixels using image coordinate. Our proposed method allows the post-processing step for center localization and optimizes clustering in an end-to-end manner. The proposed method enables real-time lane detection through the simplicity of post-processing and the adoption of a lightweight backbone. Our proposed method demonstrates competitive performance on public lane detection datasets.