 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Straight, Stop Smart: Structured Reasoning for Efficient Multi-Hop RAG
Oct 22, 2025Multi-hop retrieval-augmented generation (RAG) is a promising strategy for complex reasoning, yet existing iterative prompting approaches remain inefficient. They often regenerate predictable token sequences at every step and rely on stochastic stopping, leading to excessive token usage and unstable termination. We propose TSSS (Think Straight, Stop Smart), a structured multi-hop RAG framework designed for efficiency. TSSS introduces (i) a template-based reasoning that caches recurring prefixes and anchors sub-queries to the main question, reducing token generation cost while promoting stable reasoning, and (ii) a retriever-based terminator, which deterministically halts reasoning once additional sub-queries collapse into repetition. This separation of structured reasoning and termination control enables both faster inference and more reliable answers. On HotpotQA, 2WikiMultiHop, and MuSiQue, TSSS achieves state-of-the-art accuracy and competitive efficiency among RAG-CoT approaches, highlighting its effectiveness in efficiency-constrained scenarios such as on-device inference.
Concept-Aware LoRA for Domain-Aligned Segmentation Dataset Generation
Mar 28, 2025This paper addresses the challenge of data scarcity in semantic segmentation by generating datasets through text-to-image (T2I) generation models, reducing image acquisition and labeling costs. Segmentation dataset generation faces two key challenges: 1) aligning generated samples with the target domain and 2) producing informative samples beyond the training data. Fine-tuning T2I models can help generate samples aligned with the target domain. However, it often overfits and memorizes training data, limiting their ability to generate diverse and well-aligned samples. To overcome these issues, we propose Concept-Aware LoRA (CA-LoRA), a novel fine-tuning approach that selectively identifies and updates only the weights associated with necessary concepts (e.g., style or viewpoint) for domain alignment while preserving the pretrained knowledge of the T2I model to produce informative samples. We demonstrate its effectiveness in generating datasets for urban-scene segmentation, outperforming baseline and state-of-the-art methods in in-domain (few-shot and fully-supervised) settings, as well as in domain generalization tasks, especially under challenging conditions such as adverse weather and varying illumination, further highlighting its superiority.
Feature Diversification and Adaptation for Federated Domain Generalization
Jul 11, 2024



Federated learning, a distributed learning paradigm, utilizes multiple clients to build a robust global model. In real-world applications, local clients often operate within their limited domains, leading to a `domain shift' across clients. Privacy concerns limit each client's learning to its own domain data, which increase the risk of overfitting. Moreover, the process of aggregating models trained on own limited domain can be potentially lead to a significant degradation in the global model performance. To deal with these challenges, we introduce the concept of federated feature diversification. Each client diversifies the own limited domain data by leveraging global feature statistics, i.e., the aggregated average statistics over all participating clients, shared through the global model's parameters. This data diversification helps local models to learn client-invariant representations while preserving privacy. Our resultant global model shows robust performance on unseen test domain data. To enhance performance further, we develop an instance-adaptive inference approach tailored for test domain data. Our proposed instance feature adapter dynamically adjusts feature statistics to align with the test input, thereby reducing the domain gap between the test and training domains. We show that our method achieves state-of-the-art performance on several domain generalization benchmarks within a federated learning setting.
Towards Open-Set Test-Time Adaptation Utilizing the Wisdom of Crowds in Entropy Minimization
Sep 04, 2023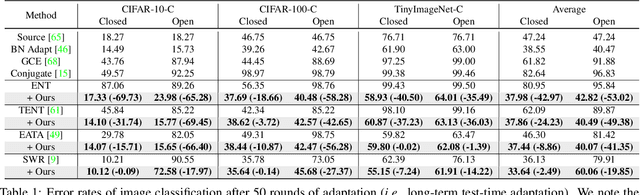
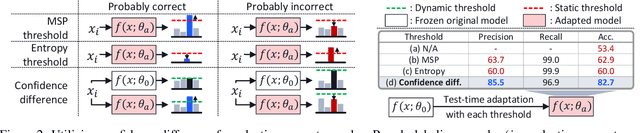
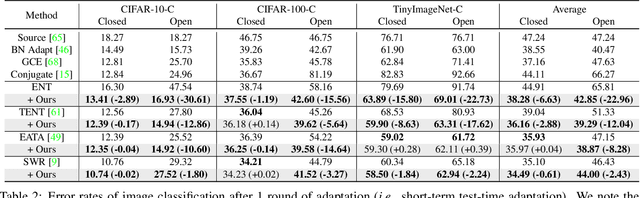
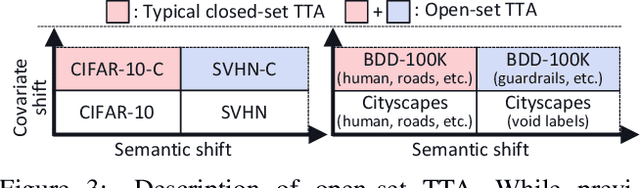
Test-time adaptation (TTA) methods, which generally rely on the model's predictions (e.g., entropy minimization) to adapt the source pretrained model to the unlabeled target domain, suffer from noisy signals originating from 1) incorrect or 2) open-set predictions. Long-term stable adaptation is hampered by such noisy signals, so training models without such error accumulation is crucial for practical TTA. To address these issues, including open-set TTA, we propose a simple yet effective sample selection method inspired by the following crucial empirical finding. While entropy minimization compels the model to increase the probability of its predicted label (i.e., confidence values), we found that noisy samples rather show decreased confidence values. To be more specific, entropy minimization attempts to raise the confidence values of an individual sample's prediction, but individual confidence values may rise or fall due to the influence of signals from numerous other predictions (i.e., wisdom of crowds). Due to this fact, noisy signals misaligned with such 'wisdom of crowds', generally found in the correct signals, fail to raise the individual confidence values of wrong samples, despite attempts to increase them. Based on such findings, we filter out the samples whose confidence values are lower in the adapted model than in the original model, as they are likely to be noisy. Our method is widely applicable to existing TTA methods and improves their long-term adaptation performance in both image classification (e.g., 49.4% reduced error rates with TENT) and semantic segmentation (e.g., 11.7% gain in mIoU with TENT).
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
Mar 13, 2023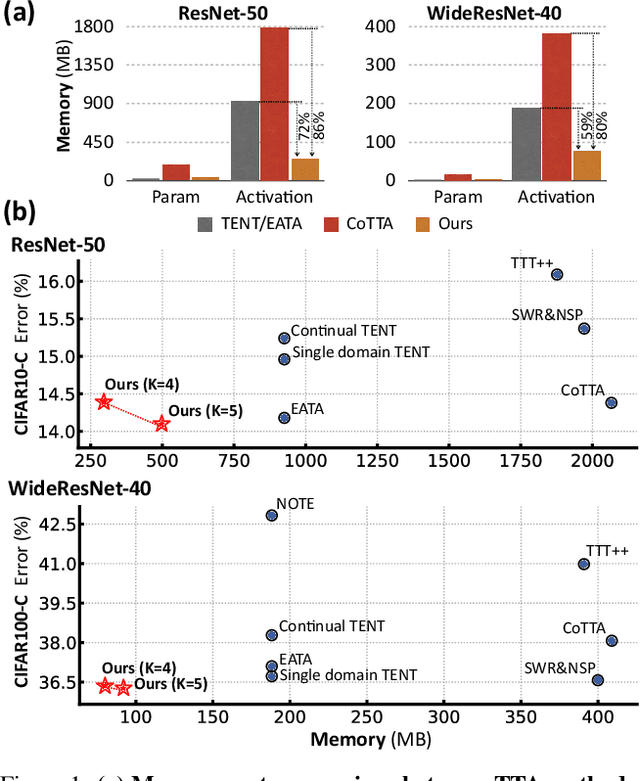
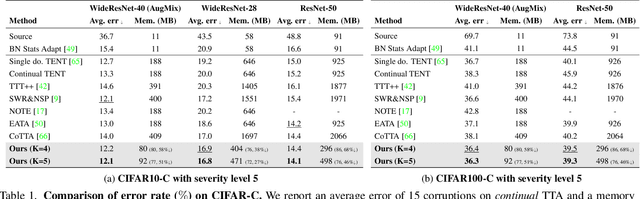

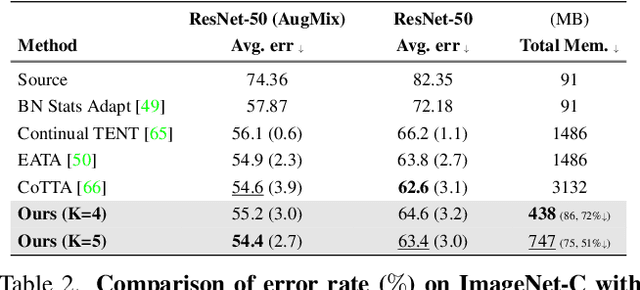
This paper presents a simple yet effective approach that improves continual test-time adaptation (TTA) in a memory-efficient manner. TTA may primarily be conducted on edge devices with limited memory, so reducing memory is crucial but has been overlooked in previous TTA studies. In addition, long-term adaptation often leads to catastrophic forgetting and error accumulation, which hinders applying TTA in real-world deployments. Our approach consists of two components to address these issues. First, we present lightweight meta networks that can adapt the frozen original networks to the target domain. This novel architecture minimizes memory consumption by decreasing the size of intermediate activations required for backpropagation. Second, our novel self-distilled regularization controls the output of the meta networks not to deviate significantly from the output of the frozen original networks, thereby preserving well-trained knowledge from the source domain. Without additional memory, this regularization prevents error accumulation and catastrophic forgetting, resulting in stable performance even in long-term test-time adaptation. We demonstrate that our simple yet effective strategy outperforms other state-of-the-art methods on various benchmarks for image classification and semantic segmentation tasks. Notably, our proposed method with ResNet-50 and WideResNet-40 takes 86% and 80% less memory than the recent state-of-the-art method, CoTTA.
TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Feb 18, 2023This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
Improving Test-Time Adaptation via Shift-agnostic Weight Regularization and Nearest Source Prototypes
Jul 24, 2022
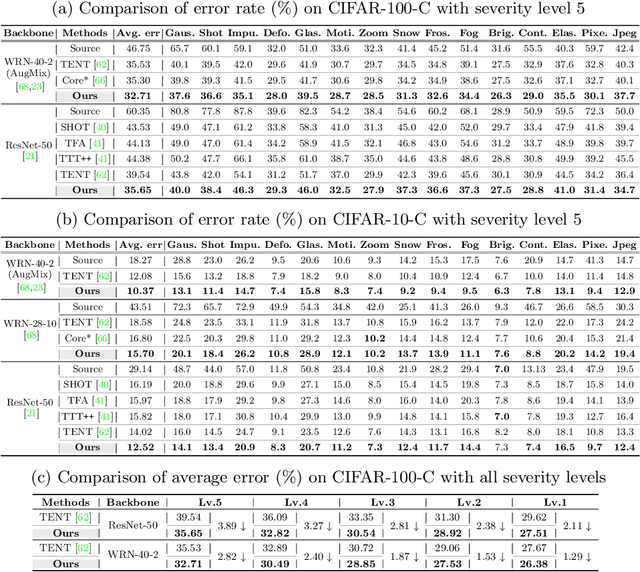

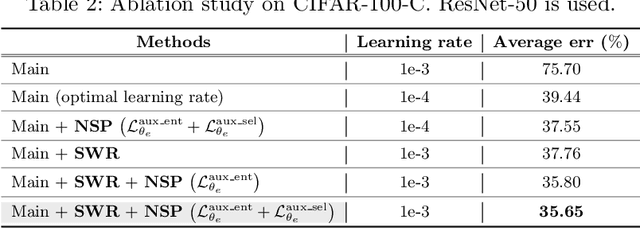
This paper proposes a novel test-time adaptation strategy that adjusts the model pre-trained on the source domain using only unlabeled online data from the target domain to alleviate the performance degradation due to the distribution shift between the source and target domains. Adapting the entire model parameters using the unlabeled online data may be detrimental due to the erroneous signals from an unsupervised objective. To mitigate this problem, we propose a shift-agnostic weight regularization that encourages largely updating the model parameters sensitive to distribution shift while slightly updating those insensitive to the shift, during test-time adaptation. This regularization enables the model to quickly adapt to the target domain without performance degradation by utilizing the benefit of a high learning rate. In addition, we present an auxiliary task based on nearest source prototypes to align the source and target features, which helps reduce the distribution shift and leads to further performance improvement. We show that our method exhibits state-of-the-art performance on various standard benchmarks and even outperforms its supervised counterpart.
Standardized Max Logits: A Simple yet Effective Approach for Identifying Unexpected Road Obstacles in Urban-Scene Segmentation
Aug 19, 2021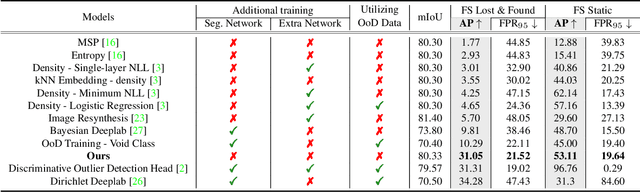
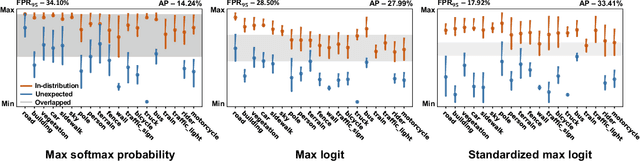


Identifying unexpected objects on roads in semantic segmentation (e.g., identifying dogs on roads) is crucial in safety-critical applications. Existing approaches use images of unexpected objects from external datasets or require additional training (e.g., retraining segmentation networks or training an extra network), which necessitate a non-trivial amount of labor intensity or lengthy inference time. One possible alternative is to use prediction scores of a pre-trained network such as the max logits (i.e., maximum values among classes before the final softmax layer) for detecting such objects. However, the distribution of max logits of each predicted class is significantly different from each other, which degrades the performance of identifying unexpected objects in urban-scene segmentation. To address this issue, we propose a simple yet effective approach that standardizes the max logits in order to align the different distributions and reflect the relative meanings of max logits within each predicted class. Moreover, we consider the local regions from two different perspectives based on the intuition that neighboring pixels share similar semantic information. In contrast to previous approaches, our method does not utilize any external datasets or require additional training, which makes our method widely applicable to existing pre-trained segmentation models. Such a straightforward approach achieves a new state-of-the-art performance on the publicly available Fishyscapes Lost & Found leaderboard with a large margin. Our code is publicly available at this $\href{https://github.com/shjung13/Standardized-max-logits}{link}$.
RobustNet: Improving Domain Generalization in Urban-Scene Segmentation via Instance Selective Whitening
Mar 31, 2021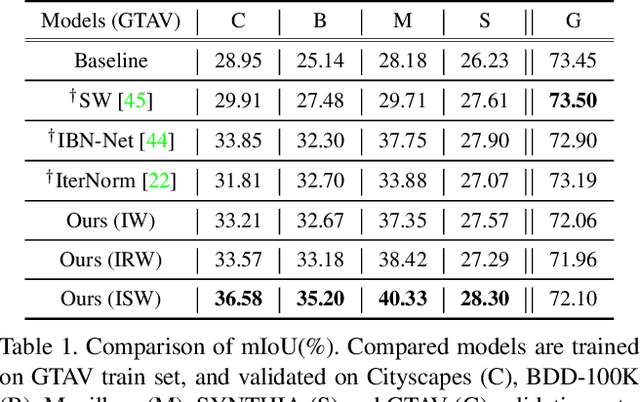


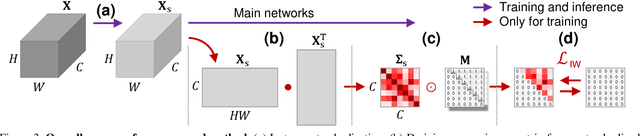
Enhancing the generalization capability of deep neural networks to unseen domains is crucial for safety-critical applications in the real world such as autonomous driving. To address this issue, this paper proposes a novel instance selective whitening loss to improve the robustness of the segmentation networks for unseen domains. Our approach disentangles the domain-specific style and domain-invariant content encoded in higher-order statistics (i.e., feature covariance) of the feature representations and selectively removes only the style information causing domain shift. As shown in Fig. 1, our method provides reasonable predictions for (a) low-illuminated, (b) rainy, and (c) unseen structures. These types of images are not included in the training dataset, where the baseline shows a significant performance drop, contrary to ours. Being simple yet effective, our approach improves the robustness of various backbone networks without additional computational cost. We conduct extensive experiments in urban-scene segmentation and show the superiority of our approach to existing work. Our code is available at https://github.com/shachoi/RobustNet.