 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoX: Egocentric Video Generation from a Single Exocentric Video
Dec 09, 2025Egocentric perception enables humans to experience and understand the world directly from their own point of view. Translating exocentric (third-person) videos into egocentric (first-person) videos opens up new possibilities for immersive understanding but remains highly challenging due to extreme camera pose variations and minimal view overlap. This task requires faithfully preserving visible content while synthesizing unseen regions in a geometrically consistent manner. To achieve this, we present EgoX, a novel framework for generating egocentric videos from a single exocentric input. EgoX leverages the pretrained spatio temporal knowledge of large-scale video diffusion models through lightweight LoRA adaptation and introduces a unified conditioning strategy that combines exocentric and egocentric priors via width and channel wise concatenation. Additionally, a geometry-guided self-attention mechanism selectively attends to spatially relevant regions, ensuring geometric coherence and high visual fidelity. Our approach achieves coherent and realistic egocentric video generation while demonstrating strong scalability and robustness across unseen and in-the-wild videos.
PHUMA: Physically-Grounded Humanoid Locomotion Dataset
Oct 30, 2025



Motion imitation is a promising approach for humanoid locomotion, enabling agents to acquire humanlike behaviors. Existing methods typically rely on high-quality motion capture datasets such as AMASS, but these are scarce and expensive, limiting scalability and diversity. Recent studies attempt to scale data collection by converting large-scale internet videos, exemplified by Humanoid-X. However, they often introduce physical artifacts such as floating, penetration, and foot skating, which hinder stable imitation. In response, we introduce PHUMA, a Physically-grounded HUMAnoid locomotion dataset that leverages human video at scale, while addressing physical artifacts through careful data curation and physics-constrained retargeting. PHUMA enforces joint limits, ensures ground contact, and eliminates foot skating, producing motions that are both large-scale and physically reliable. We evaluated PHUMA in two sets of conditions: (i) imitation of unseen motion from self-recorded test videos and (ii) path following with pelvis-only guidance. In both cases, PHUMA-trained policies outperform Humanoid-X and AMASS, achieving significant gains in imitating diverse motions. The code is available at https://davian-robotics.github.io/PHUMA.
Cross-Frame Representation Alignment for Fine-Tuning Video Diffusion Models
Jun 10, 2025Fine-tuning Video Diffusion Models (VDMs) at the user level to generate videos that reflect specific attributes of training data presents notable challenges, yet remains underexplored despite its practical importance. Meanwhile, recent work such as Representation Alignment (REPA) has shown promise in improving the convergence and quality of DiT-based image diffusion models by aligning, or assimilating, its internal hidden states with external pretrained visual features, suggesting its potential for VDM fine-tuning. In this work, we first propose a straightforward adaptation of REPA for VDMs and empirically show that, while effective for convergence, it is suboptimal in preserving semantic consistency across frames. To address this limitation, we introduce Cross-frame Representation Alignment (CREPA), a novel regularization technique that aligns hidden states of a frame with external features from neighboring frames. Empirical evaluations on large-scale VDMs, including CogVideoX-5B and Hunyuan Video, demonstrate that CREPA improves both visual fidelity and cross-frame semantic coherence when fine-tuned with parameter-efficient methods such as LoRA. We further validate CREPA across diverse datasets with varying attributes, confirming its broad applicability. Project page: https://crepavideo.github.io
SphereDiff: Tuning-free Omnidirectional Panoramic Image and Video Generation via Spherical Latent Representation
Apr 19, 2025The increasing demand for AR/VR applications has highlighted the need for high-quality 360-degree panoramic content. However, generating high-quality 360-degree panoramic images and videos remains a challenging task due to the severe distortions introduced by equirectangular projection (ERP). Existing approaches either fine-tune pretrained diffusion models on limited ERP datasets or attempt tuning-free methods that still rely on ERP latent representations, leading to discontinuities near the poles. In this paper, we introduce SphereDiff, a novel approach for seamless 360-degree panoramic image and video generation using state-of-the-art diffusion models without additional tuning. We define a spherical latent representation that ensures uniform distribution across all perspectives, mitigating the distortions inherent in ERP. We extend MultiDiffusion to spherical latent space and propose a spherical latent sampling method to enable direct use of pretrained diffusion models. Moreover, we introduce distortion-aware weighted averaging to further improve the generation quality in the projection process. Our method outperforms existing approaches in generating 360-degree panoramic content while maintaining high fidelity, making it a robust solution for immersive AR/VR applications. The code is available here. https://github.com/pmh9960/SphereDiff
Concept-Aware LoRA for Domain-Aligned Segmentation Dataset Generation
Mar 28, 2025This paper addresses the challenge of data scarcity in semantic segmentation by generating datasets through text-to-image (T2I) generation models, reducing image acquisition and labeling costs. Segmentation dataset generation faces two key challenges: 1) aligning generated samples with the target domain and 2) producing informative samples beyond the training data. Fine-tuning T2I models can help generate samples aligned with the target domain. However, it often overfits and memorizes training data, limiting their ability to generate diverse and well-aligned samples. To overcome these issues, we propose Concept-Aware LoRA (CA-LoRA), a novel fine-tuning approach that selectively identifies and updates only the weights associated with necessary concepts (e.g., style or viewpoint) for domain alignment while preserving the pretrained knowledge of the T2I model to produce informative samples. We demonstrate its effectiveness in generating datasets for urban-scene segmentation, outperforming baseline and state-of-the-art methods in in-domain (few-shot and fully-supervised) settings, as well as in domain generalization tasks, especially under challenging conditions such as adverse weather and varying illumination, further highlighting its superiority.
Forecasting Future International Events: A Reliable Dataset for Text-Based Event Modeling
Nov 21, 2024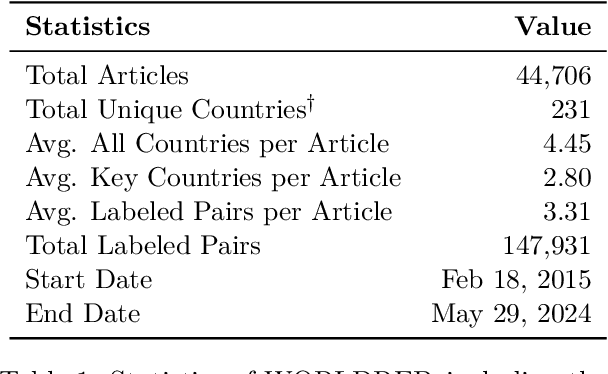
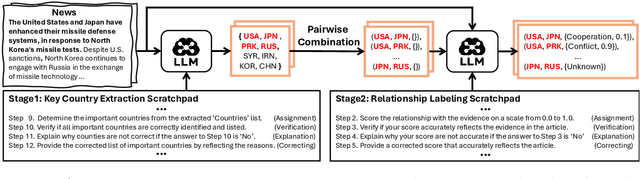

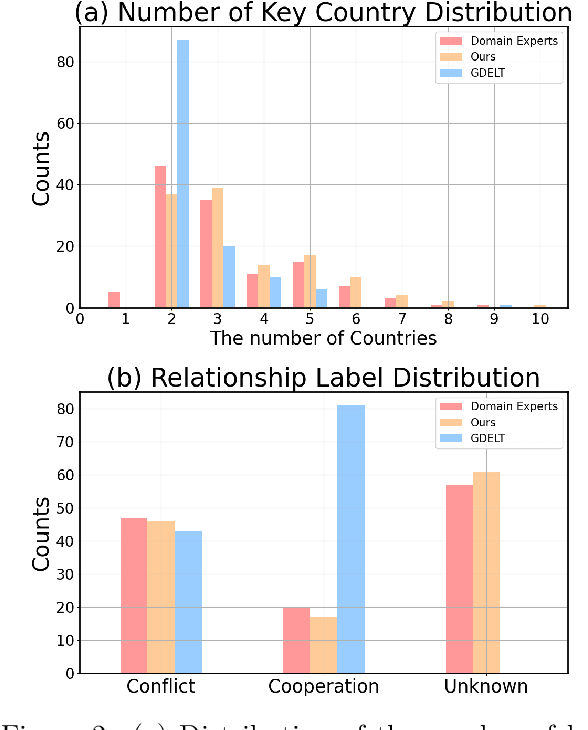
Predicting future international events from textual information, such as news articles, has tremendous potential for applications in global policy, strategic decision-making, and geopolitics. However, existing datasets available for this task are often limited in quality, hindering the progress of related research. In this paper, we introduce WORLDREP (WORLD Relationship and Event Prediction), a novel dataset designed to address these limitations by leveraging the advanced reasoning capabilities of large-language models (LLMs). Our dataset features high-quality scoring labels generated through advanced prompt modeling and rigorously validated by domain experts in political science. We showcase the quality and utility of WORLDREP for real-world event prediction tasks, demonstrating its effectiveness through extensive experiments and analysis. Furthermore, we publicly release our dataset along with the full automation source code for data collection, labeling, and benchmarking, aiming to support and advance research in text-based event prediction.
Regularized Training with Generated Datasets for Name-Only Transfer of Vision-Language Models
Jun 08, 2024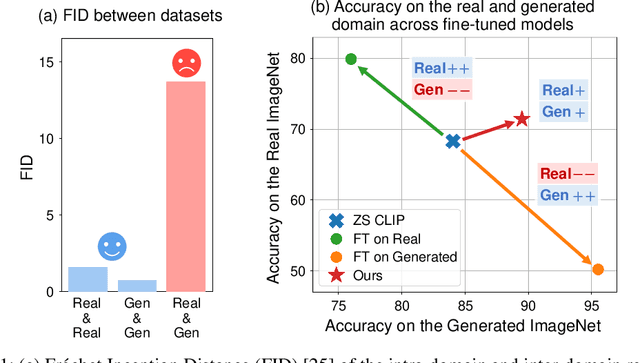
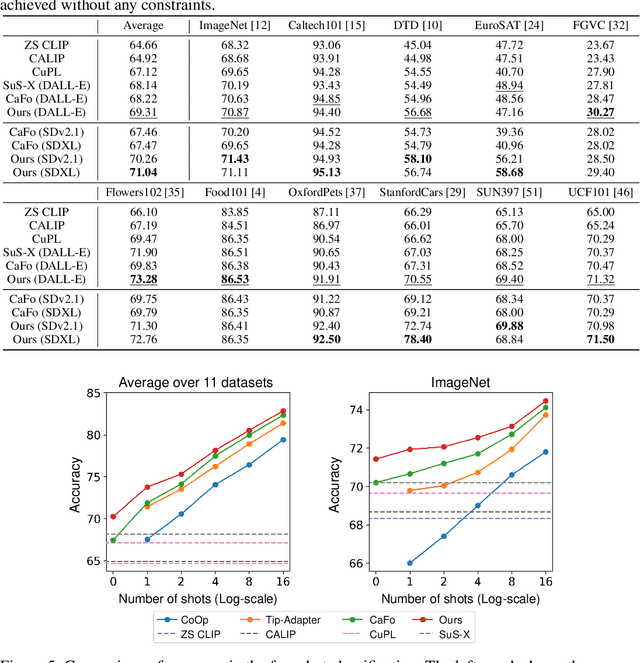
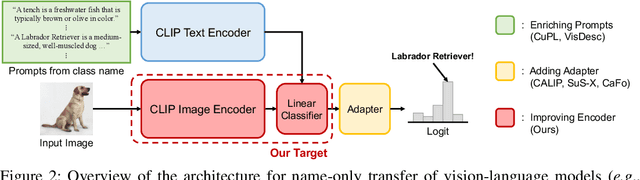
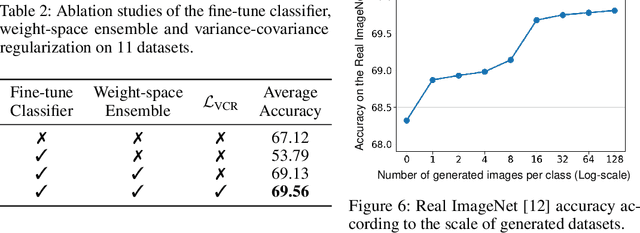
Recent advancements in text-to-image generation have inspired researchers to generate datasets tailored for perception models using generative models, which prove particularly valuable in scenarios where real-world data is limited. In this study, our goal is to address the challenges when fine-tuning vision-language models (e.g., CLIP) on generated datasets. Specifically, we aim to fine-tune vision-language models to a specific classification model without access to any real images, also known as name-only transfer. However, despite the high fidelity of generated images, we observed a significant performance degradation when fine-tuning the model using the generated datasets due to the domain gap between real and generated images. To overcome the domain gap, we provide two regularization methods for training and post-training, respectively. First, we leverage the domain-agnostic knowledge from the original pre-trained vision-language model by conducting the weight-space ensemble of the fine-tuned model on the generated dataset with the original pre-trained model at the post-training. Secondly, we reveal that fine-tuned models with high feature diversity score high performance in the real domain, which indicates that increasing feature diversity prevents learning the generated domain-specific knowledge. Thus, we encourage feature diversity by providing additional regularization at training time. Extensive experiments on various classification datasets and various text-to-image generation models demonstrated that our analysis and regularization techniques effectively mitigate the domain gap, which has long been overlooked, and enable us to achieve state-of-the-art performance by training with generated images. Code is available at https://github.com/pmh9960/regft-for-gen
StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
Dec 04, 2023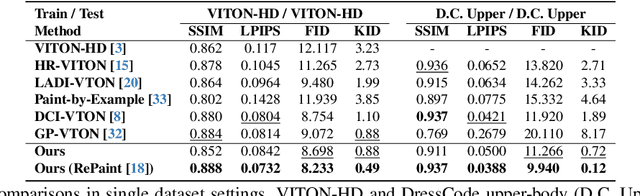

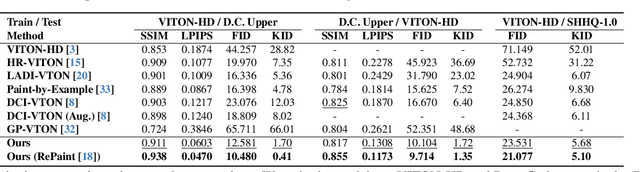

Given a clothing image and a person image, an image-based virtual try-on aims to generate a customized image that appears natural and accurately reflects the characteristics of the clothing image. In this work, we aim to expand the applicability of the pre-trained diffusion model so that it can be utilized independently for the virtual try-on task.The main challenge is to preserve the clothing details while effectively utilizing the robust generative capability of the pre-trained model. In order to tackle these issues, we propose StableVITON, learning the semantic correspondence between the clothing and the human body within the latent space of the pre-trained diffusion model in an end-to-end manner. Our proposed zero cross-attention blocks not only preserve the clothing details by learning the semantic correspondence but also generate high-fidelity images by utilizing the inherent knowledge of the pre-trained model in the warping process. Through our proposed novel attention total variation loss and applying augmentation, we achieve the sharp attention map, resulting in a more precise representation of clothing details. StableVITON outperforms the baselines in qualitative and quantitative evaluation, showing promising quality in arbitrary person images. Our code is available at https://github.com/rlawjdghek/StableVITON.
Learning to Generate Semantic Layouts for Higher Text-Image Correspondence in Text-to-Image Synthesis
Aug 16, 2023Existing text-to-image generation approaches have set high standards for photorealism and text-image correspondence, largely benefiting from web-scale text-image datasets, which can include up to 5~billion pairs. However, text-to-image generation models trained on domain-specific datasets, such as urban scenes, medical images, and faces, still suffer from low text-image correspondence due to the lack of text-image pairs. Additionally, collecting billions of text-image pairs for a specific domain can be time-consuming and costly. Thus, ensuring high text-image correspondence without relying on web-scale text-image datasets remains a challenging task. In this paper, we present a novel approach for enhancing text-image correspondence by leveraging available semantic layouts. Specifically, we propose a Gaussian-categorical diffusion process that simultaneously generates both images and corresponding layout pairs. Our experiments reveal that we can guide text-to-image generation models to be aware of the semantics of different image regions, by training the model to generate semantic labels for each pixel. We demonstrate that our approach achieves higher text-image correspondence compared to existing text-to-image generation approaches in the Multi-Modal CelebA-HQ and the Cityscapes dataset, where text-image pairs are scarce. Codes are available in this https://pmh9960.github.io/research/GCDP
iColoriT: Towards Propagating Local Hint to the Right Region in Interactive Colorization by Leveraging Vision Transformer
Jul 15, 2022
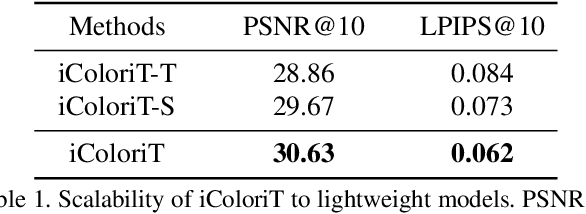


Point-interactive image colorization aims to colorize grayscale images when a user provides the colors for specific locations. It is essential for point-interactive colorization methods to appropriately propagate user-provided colors (i.e., user hints) in the entire image to obtain a reasonably colorized image with minimal user effort. However, existing approaches often produce partially colorized results due to the inefficient design of stacking convolutional layers to propagate hints to distant relevant regions. To address this problem, we present iColoriT, a novel point-interactive colorization Vision Transformer capable of propagating user hints to relevant regions, leveraging the global receptive field of Transformers. The self-attention mechanism of Transformers enables iColoriT to selectively colorize relevant regions with only a few local hints. Our approach colorizes images in real-time by utilizing pixel shuffling, an efficient upsampling technique that replaces the decoder architecture. Also, in order to mitigate the artifacts caused by pixel shuffling with large upsampling ratios, we present the local stabilizing layer. Extensive quantitative and qualitative results demonstrate that our approach highly outperforms existing methods for point-interactive colorization, producing accurately colorized images with a user's minimal effort.