 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryTalker: Personalized Speech-Driven 3D Facial Animation via Audio-Guided Stylization
Jul 28, 2025



Speech-driven 3D facial animation aims to synthesize realistic facial motion sequences from given audio, matching the speaker's speaking style. However, previous works often require priors such as class labels of a speaker or additional 3D facial meshes at inference, which makes them fail to reflect the speaking style and limits their practical use. To address these issues, we propose MemoryTalker which enables realistic and accurate 3D facial motion synthesis by reflecting speaking style only with audio input to maximize usability in applications. Our framework consists of two training stages: 1-stage is storing and retrieving general motion (i.e., Memorizing), and 2-stage is to perform the personalized facial motion synthesis (i.e., Animating) with the motion memory stylized by the audio-driven speaking style feature. In this second stage, our model learns about which facial motion types should be emphasized for a particular piece of audio. As a result, our MemoryTalker can generate a reliable personalized facial animation without additional prior information. With quantitative and qualitative evaluations, as well as user study, we show the effectiveness of our model and its performance enhancement for personalized facial animation over state-of-the-art methods.
Learning Phonetic Context-Dependent Viseme for Enhancing Speech-Driven 3D Facial Animation
Jul 28, 2025Speech-driven 3D facial animation aims to generate realistic facial movements synchronized with audio. Traditional methods primarily minimize reconstruction loss by aligning each frame with ground-truth. However, this frame-wise approach often fails to capture the continuity of facial motion, leading to jittery and unnatural outputs due to coarticulation. To address this, we propose a novel phonetic context-aware loss, which explicitly models the influence of phonetic context on viseme transitions. By incorporating a viseme coarticulation weight, we assign adaptive importance to facial movements based on their dynamic changes over time, ensuring smoother and perceptually consistent animations. Extensive experiments demonstrate that replacing the conventional reconstruction loss with ours improves both quantitative metrics and visual quality. It highlights the importance of explicitly modeling phonetic context-dependent visemes in synthesizing natural speech-driven 3D facial animation. Project page: https://cau-irislab.github.io/interspeech25/
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Mar 22, 2024
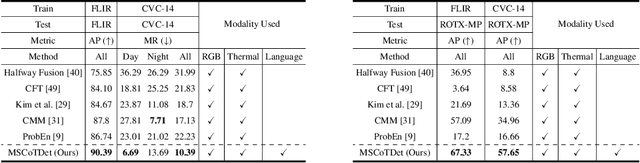

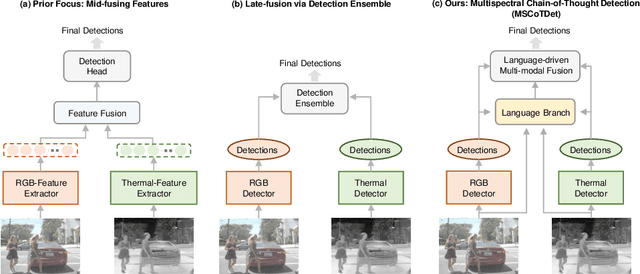
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in obvious cases, especially due to the modality bias learned from statistically biased datasets. From these problems, we anticipate that maybe understanding the complementary information itself is difficult to achieve from vision-only models. Accordingly, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework, which incorporates Large Language Models (LLMs) to understand the complementary information at the semantic level and further enhance the fusion process. Specifically, we generate text descriptions of the pedestrian in each RGB and thermal modality and design a Multispectral Chain-of-Thought (MSCoT) prompting, which models a step-by-step process to facilitate cross-modal reasoning at the semantic level and perform accurate detection. Moreover, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing vision-driven and language-driven detections. Extensive experiments validate that MSCoTDet improves multispectral pedestrian detection.
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Mar 02, 2024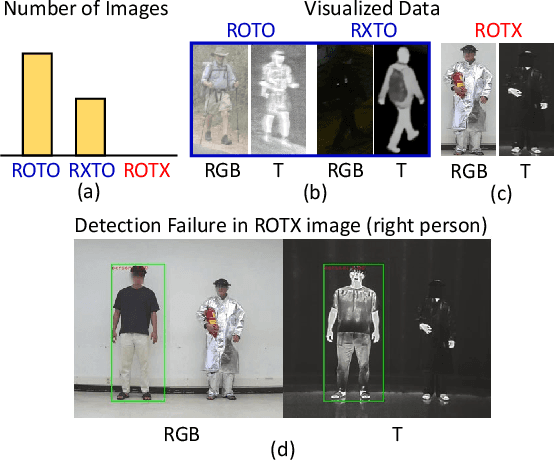
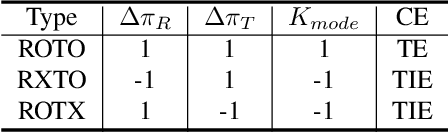
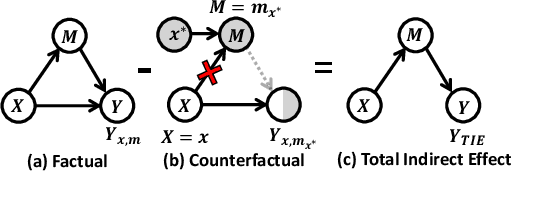
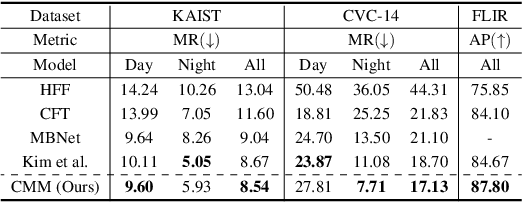
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.
Visual Comfort Aware-Reinforcement Learning for Depth Adjustment of Stereoscopic 3D Images
Apr 14, 2021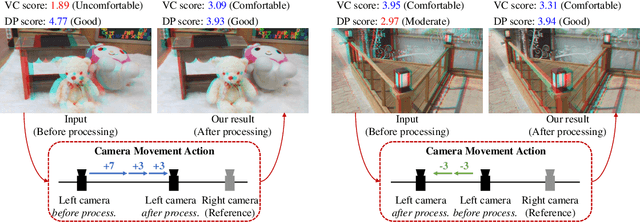

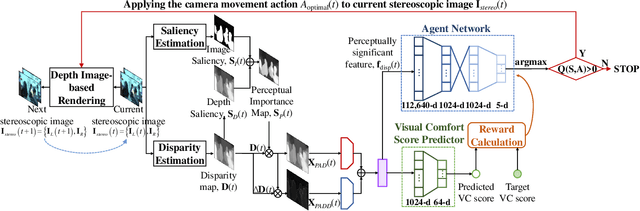
Depth adjustment aims to enhance the visual experience of stereoscopic 3D (S3D) images, which accompanied with improving visual comfort and depth perception. For a human expert, the depth adjustment procedure is a sequence of iterative decision making. The human expert iteratively adjusts the depth until he is satisfied with the both levels of visual comfort and the perceived depth. In this work, we present a novel deep reinforcement learning (DRL)-based approach for depth adjustment named VCA-RL (Visual Comfort Aware Reinforcement Learning) to explicitly model human sequential decision making in depth editing operations. We formulate the depth adjustment process as a Markov decision process where actions are defined as camera movement operations to control the distance between the left and right cameras. Our agent is trained based on the guidance of an objective visual comfort assessment metric to learn the optimal sequence of camera movement actions in terms of perceptual aspects in stereoscopic viewing. With extensive experiments and user studies, we show the effectiveness of our VCA-RL model on three different S3D databases.
Towards a Better Understanding of VR Sickness: Physical Symptom Prediction for VR Contents
Apr 14, 2021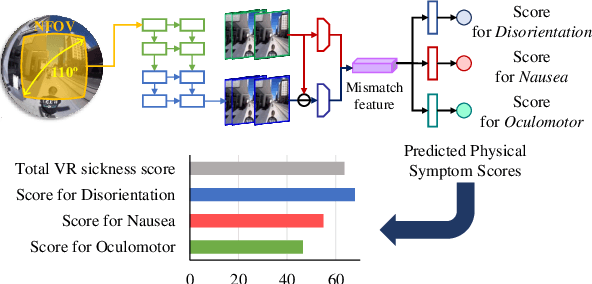
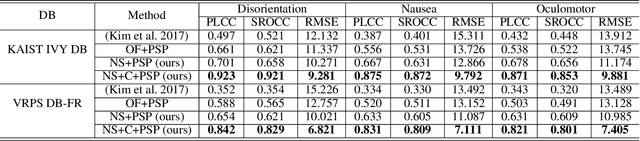
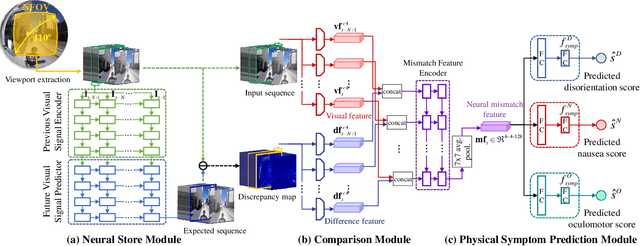
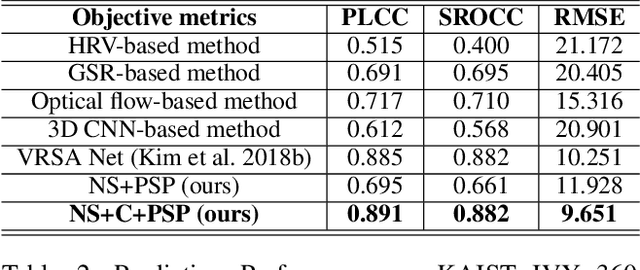
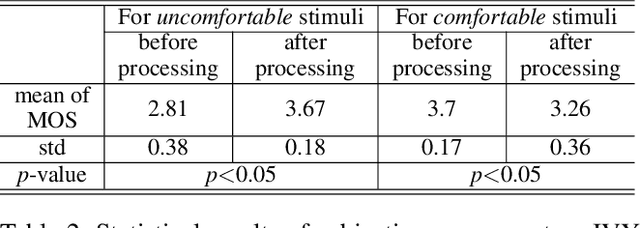
We address the black-box issue of VR sickness assessment (VRSA) by evaluating the level of physical symptoms of VR sickness. For the VR contents inducing the similar VR sickness level, the physical symptoms can vary depending on the characteristics of the contents. Most of existing VRSA methods focused on assessing the overall VR sickness score. To make better understanding of VR sickness, it is required to predict and provide the level of major symptoms of VR sickness rather than overall degree of VR sickness. In this paper, we predict the degrees of main physical symptoms affecting the overall degree of VR sickness, which are disorientation, nausea, and oculomotor. In addition, we introduce a new large-scale dataset for VRSA including 360 videos with various frame rates, physiological signals, and subjective scores. On VRSA benchmark and our newly collected dataset, our approach shows a potential to not only achieve the highest correlation with subjective scores, but also to better understand which symptoms are the main causes of VR sickness.
Video Prediction Recalling Long-term Motion Context via Memory Alignment Learning
Apr 02, 2021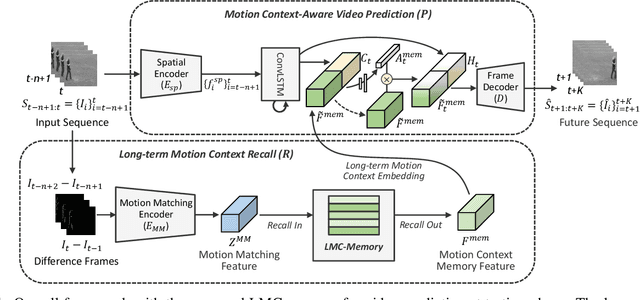
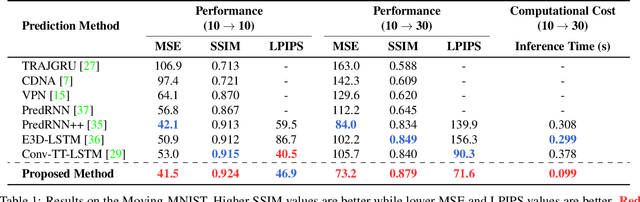
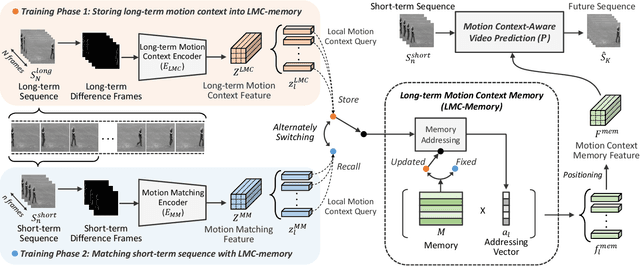
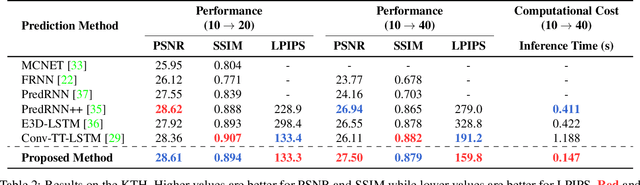
Our work addresses long-term motion context issues for predicting future frames. To predict the future precisely, it is required to capture which long-term motion context (e.g., walking or running) the input motion (e.g., leg movement) belongs to. The bottlenecks arising when dealing with the long-term motion context are: (i) how to predict the long-term motion context naturally matching input sequences with limited dynamics, (ii) how to predict the long-term motion context with high-dimensionality (e.g., complex motion). To address the issues, we propose novel motion context-aware video prediction. To solve the bottleneck (i), we introduce a long-term motion context memory (LMC-Memory) with memory alignment learning. The proposed memory alignment learning enables to store long-term motion contexts into the memory and to match them with sequences including limited dynamics. As a result, the long-term context can be recalled from the limited input sequence. In addition, to resolve the bottleneck (ii), we propose memory query decomposition to store local motion context (i.e., low-dimensional dynamics) and recall the suitable local context for each local part of the input individually. It enables to boost the alignment effects of the memory. Experimental results show that the proposed method outperforms other sophisticated RNN-based methods, especially in long-term condition. Further, we validate the effectiveness of the proposed network designs by conducting ablation studies and memory feature analysis. The source code of this work is available.
Generative Guiding Block: Synthesizing Realistic Looking Variants Capable of Even Large Change Demands
Jul 02, 2019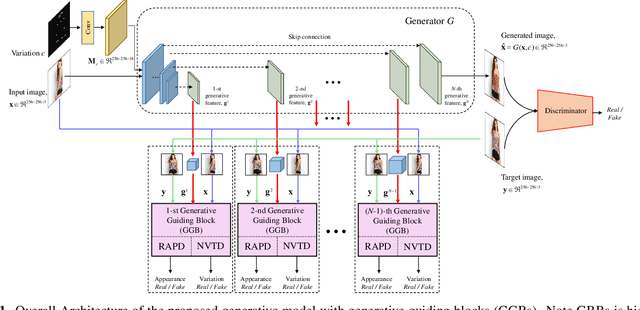
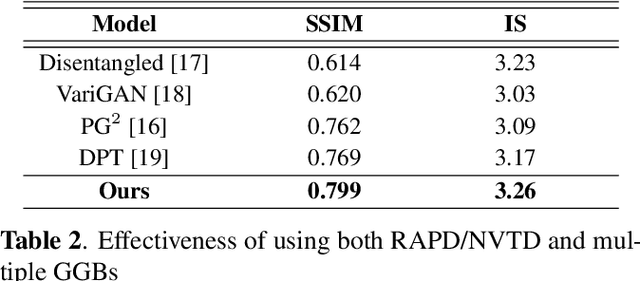
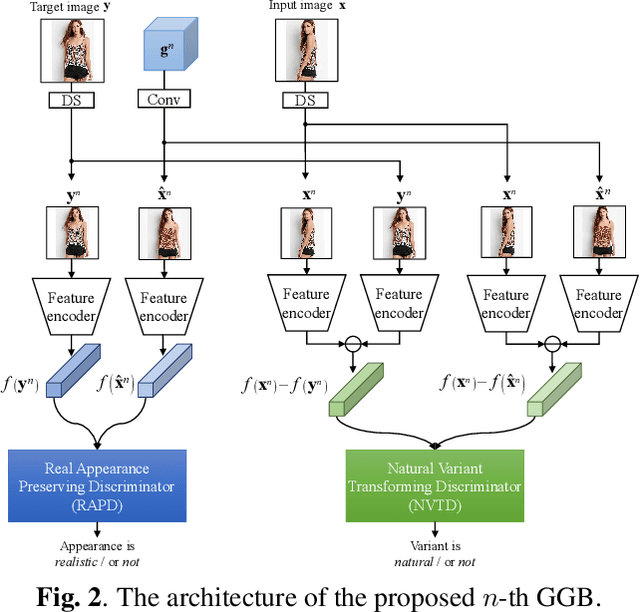
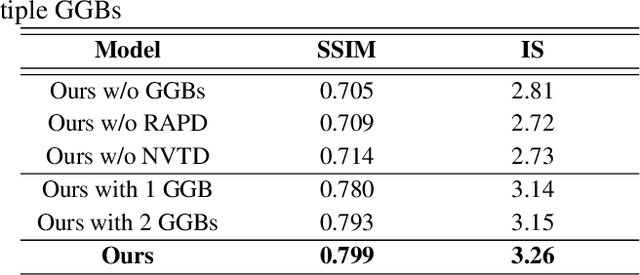
Realistic image synthesis is to generate an image that is perceptually indistinguishable from an actual image. Generating realistic looking images with large variations (e.g., large spatial deformations and large pose change), however, is very challenging. Handing large variations as well as preserving appearance needs to be taken into account in the realistic looking image generation. In this paper, we propose a novel realistic looking image synthesis method, especially in large change demands. To do that, we devise generative guiding blocks. The proposed generative guiding block includes realistic appearance preserving discriminator and naturalistic variation transforming discriminator. By taking the proposed generative guiding blocks into generative model, the latent features at the layer of generative model are enhanced to synthesize both realistic looking- and target variation- image. With qualitative and quantitative evaluation in experiments, we demonstrated the effectiveness of the proposed generative guiding blocks, compared to the state-of-the-arts.
ICADx: Interpretable computer aided diagnosis of breast masses
May 23, 2018In this study, a novel computer aided diagnosis (CADx) framework is devised to investigate interpretability for classifying breast masses. Recently, a deep learning technology has been successfully applied to medical image analysis including CADx. Existing deep learning based CADx approaches, however, have a limitation in explaining the diagnostic decision. In real clinical practice, clinical decisions could be made with reasonable explanation. So current deep learning approaches in CADx are limited in real world deployment. In this paper, we investigate interpretability in CADx with the proposed interpretable CADx (ICADx) framework. The proposed framework is devised with a generative adversarial network, which consists of interpretable diagnosis network and synthetic lesion generative network to learn the relationship between malignancy and a standardized description (BI-RADS). The lesion generative network and the interpretable diagnosis network compete in an adversarial learning so that the two networks are improved. The effectiveness of the proposed method was validated on public mammogram database. Experimental results showed that the proposed ICADx framework could provide the interpretability of mass as well as mass classification. It was mainly attributed to the fact that the proposed method was effectively trained to find the relationship between malignancy and interpretations via the adversarial learning. These results imply that the proposed ICADx framework could be a promising approach to develop the CADx system.
STAN: Spatio-Temporal Adversarial Networks for Abnormal Event Detection
Apr 23, 2018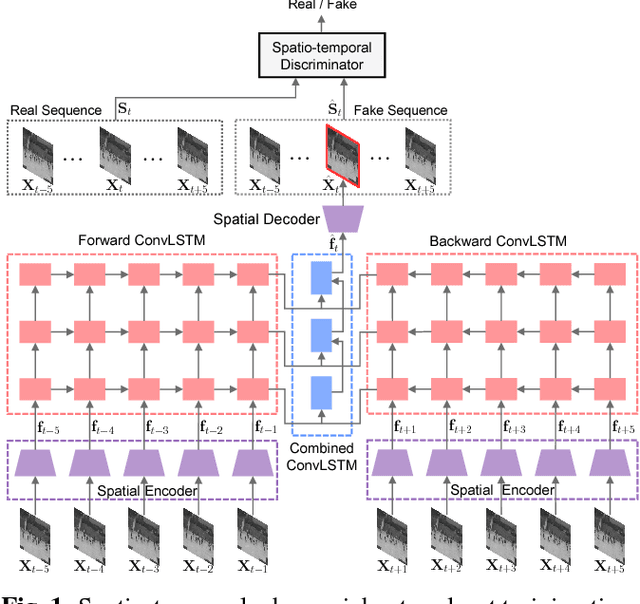
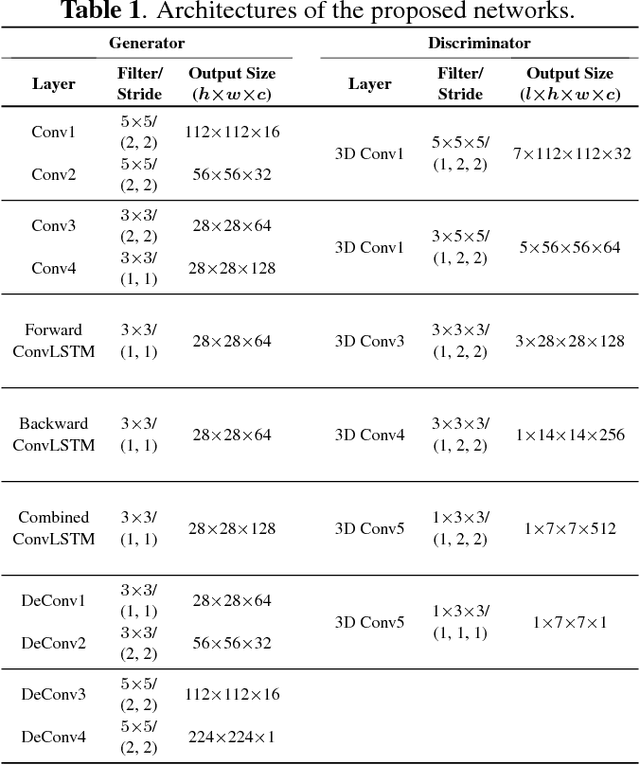

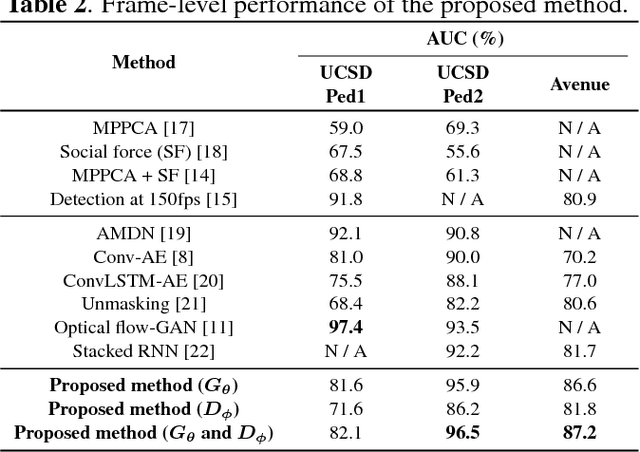
In this paper, we propose a novel abnormal event detection method with spatio-temporal adversarial networks (STAN). We devise a spatio-temporal generator which synthesizes an inter-frame by considering spatio-temporal characteristics with bidirectional ConvLSTM. A proposed spatio-temporal discriminator determines whether an input sequence is real-normal or not with 3D convolutional layers. These two networks are trained in an adversarial way to effectively encode spatio-temporal features of normal patterns. After the learning, the generator and the discriminator can be independently used as detectors, and deviations from the learned normal patterns are detected as abnormalities. Experimental results show that the proposed method achieved competitive performance compared to the state-of-the-art methods. Further, for the interpretation, we visualize the location of abnormal events detected by the proposed networks using a generator loss and discriminator gradients.