 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Vision-Language Models Truly Understanding Multi-vision Sensor?
Dec 30, 2024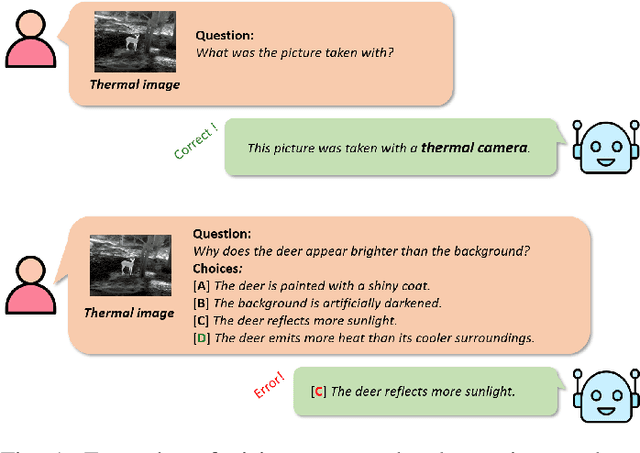

Large-scale Vision-Language Models (VLMs) have advanced by aligning vision inputs with text, significantly improving performance in computer vision tasks. Moreover, for VLMs to be effectively utilized in real-world applications, an understanding of diverse multi-vision sensor data, such as thermal, depth, and X-ray information, is essential. However, we find that current VLMs process multi-vision sensor images without deep understanding of sensor information, disregarding each sensor's unique physical properties. This limitation restricts their capacity to interpret and respond to complex questions requiring multi-vision sensor reasoning. To address this, we propose a novel Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark, assessing VLMs on their capacity for sensor-specific reasoning. Moreover, we introduce Diverse Negative Attributes (DNA) optimization to enable VLMs to perform deep reasoning on multi-vision sensor tasks, helping to bridge the core information gap between images and sensor data. Extensive experimental results validate that the proposed DNA method can significantly improve the multi-vision sensor reasoning for VLMs.
Revisiting Misalignment in Multispectral Pedestrian Detection: A Language-Driven Approach for Cross-modal Alignment Fusion
Nov 27, 2024



Multispectral pedestrian detection is a crucial component in various critical applications. However, a significant challenge arises due to the misalignment between these modalities, particularly under real-world conditions where data often appear heavily misaligned. Conventional methods developed on well-aligned or minimally misaligned datasets fail to address these discrepancies adequately. This paper introduces a new framework for multispectral pedestrian detection designed specifically to handle heavily misaligned datasets without the need for costly and complex traditional pre-processing calibration. By leveraging Large-scale Vision-Language Models (LVLM) for cross-modal semantic alignment, our approach seeks to enhance detection accuracy by aligning semantic information across the RGB and thermal domains. This method not only simplifies the operational requirements but also extends the practical usability of multispectral detection technologies in practical applications.
SPARK: Multi-Vision Sensor Perception and Reasoning Benchmark for Large-scale Vision-Language Models
Aug 23, 2024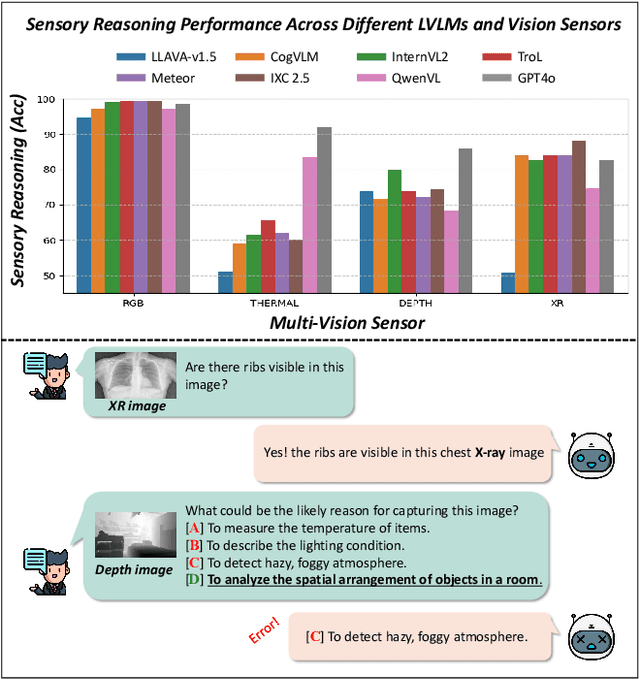
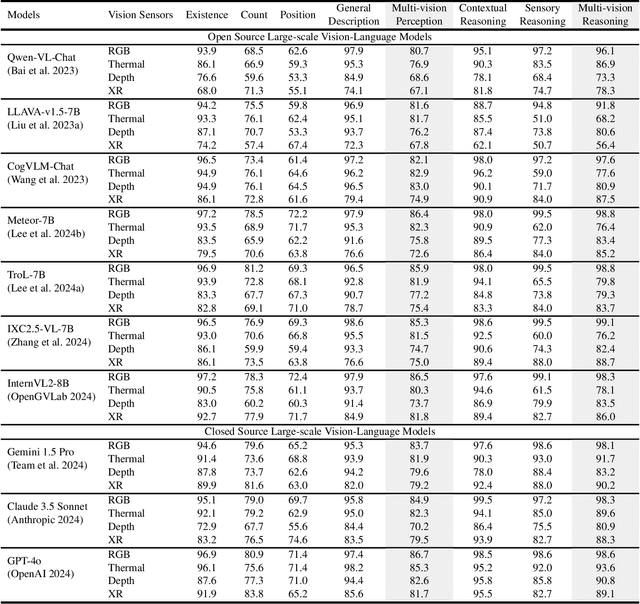
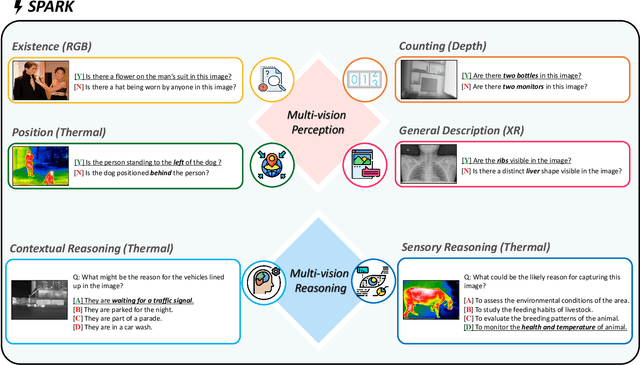
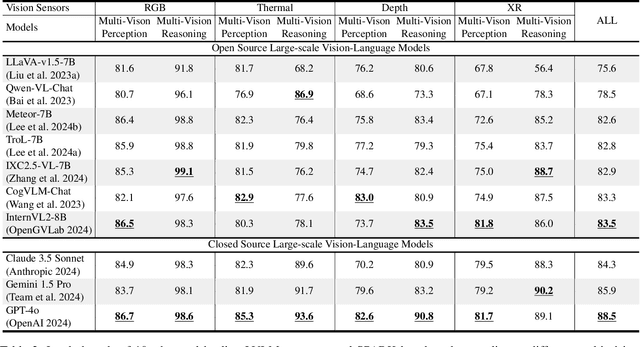
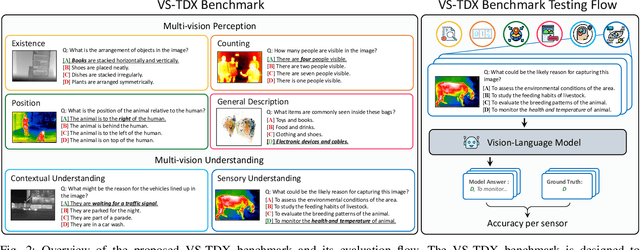
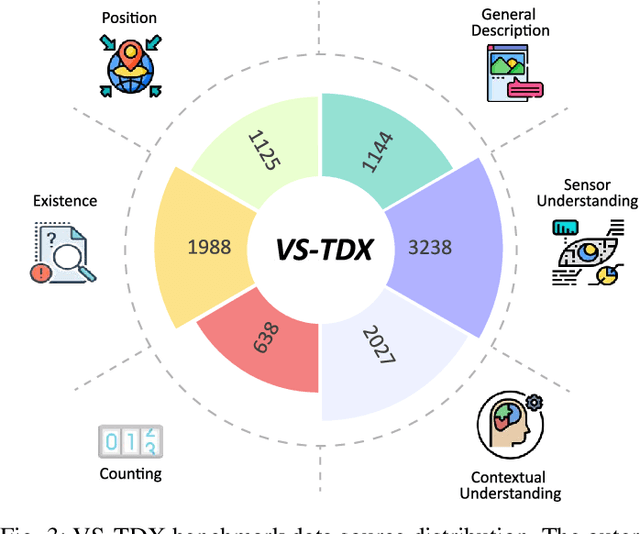
Large-scale Vision-Language Models (LVLMs) have significantly advanced with text-aligned vision inputs. They have made remarkable progress in computer vision tasks by aligning text modality with vision inputs. There are also endeavors to incorporate multi-vision sensors beyond RGB, including thermal, depth, and medical X-ray images. However, we observe that current LVLMs view images taken from multi-vision sensors as if they were in the same RGB domain without considering the physical characteristics of multi-vision sensors. They fail to convey the fundamental multi-vision sensor information from the dataset and the corresponding contextual knowledge properly. Consequently, alignment between the information from the actual physical environment and the text is not achieved correctly, making it difficult to answer complex sensor-related questions that consider the physical environment. In this paper, we aim to establish a multi-vision Sensor Perception And Reasoning benchmarK called SPARK that can reduce the fundamental multi-vision sensor information gap between images and multi-vision sensors. We generated 6,248 vision-language test samples to investigate multi-vision sensory perception and multi-vision sensory reasoning on physical sensor knowledge proficiency across different formats, covering different types of sensor-related questions. We utilized these samples to assess ten leading LVLMs. The results showed that most models displayed deficiencies in multi-vision sensory reasoning to varying extents. Codes and data are available at https://github.com/top-yun/SPARK
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Mar 22, 2024
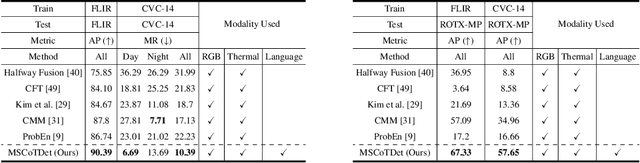

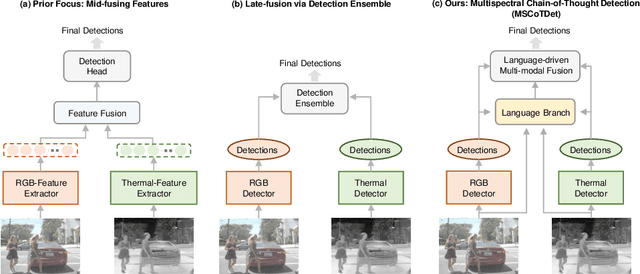
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in obvious cases, especially due to the modality bias learned from statistically biased datasets. From these problems, we anticipate that maybe understanding the complementary information itself is difficult to achieve from vision-only models. Accordingly, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework, which incorporates Large Language Models (LLMs) to understand the complementary information at the semantic level and further enhance the fusion process. Specifically, we generate text descriptions of the pedestrian in each RGB and thermal modality and design a Multispectral Chain-of-Thought (MSCoT) prompting, which models a step-by-step process to facilitate cross-modal reasoning at the semantic level and perform accurate detection. Moreover, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing vision-driven and language-driven detections. Extensive experiments validate that MSCoTDet improves multispectral pedestrian detection.
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Mar 02, 2024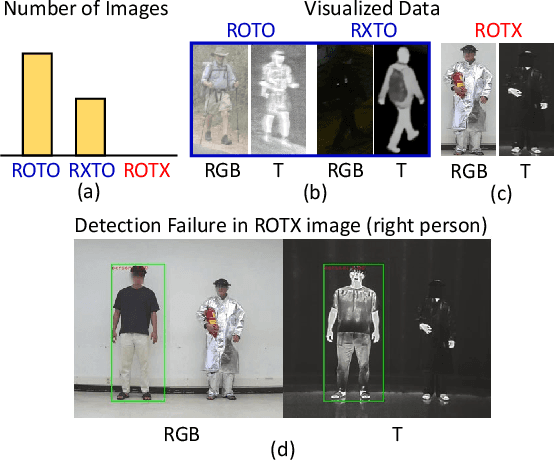
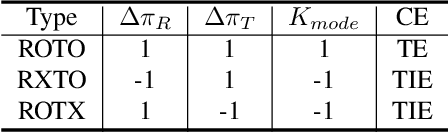
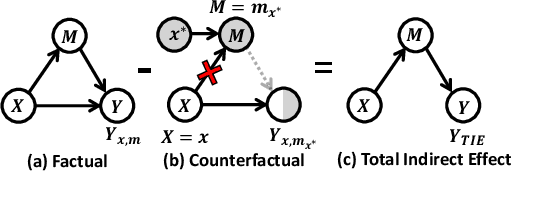
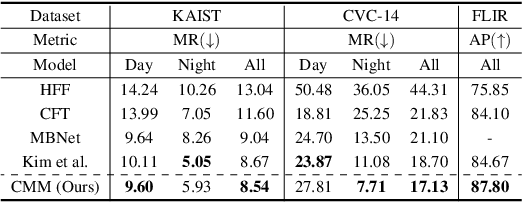
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.
Advancing Adversarial Training by Injecting Booster Signal
Jun 27, 2023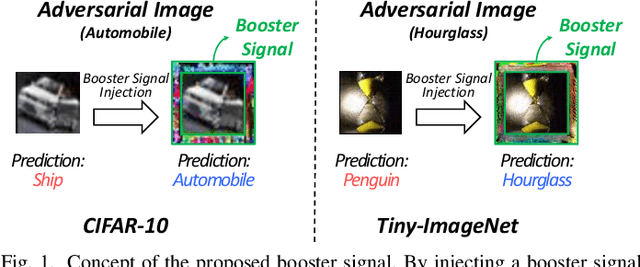
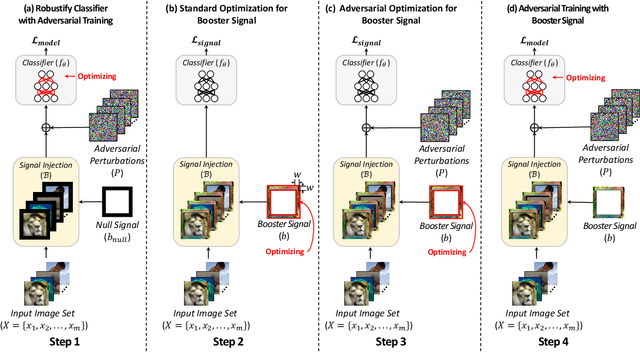
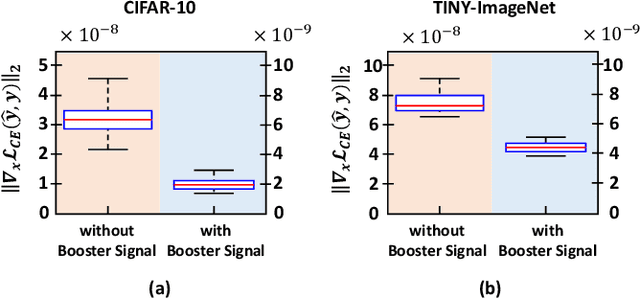
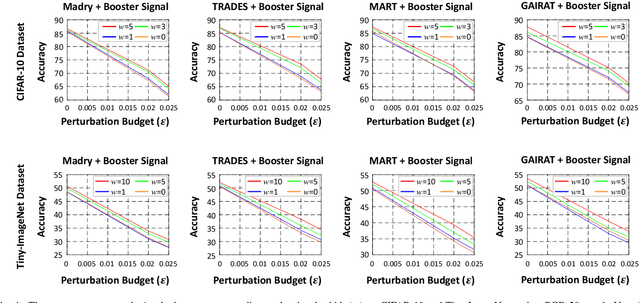
Recent works have demonstrated that deep neural networks (DNNs) are highly vulnerable to adversarial attacks. To defend against adversarial attacks, many defense strategies have been proposed, among which adversarial training has been demonstrated to be the most effective strategy. However, it has been known that adversarial training sometimes hurts natural accuracy. Then, many works focus on optimizing model parameters to handle the problem. Different from the previous approaches, in this paper, we propose a new approach to improve the adversarial robustness by using an external signal rather than model parameters. In the proposed method, a well-optimized universal external signal called a booster signal is injected into the outside of the image which does not overlap with the original content. Then, it boosts both adversarial robustness and natural accuracy. The booster signal is optimized in parallel to model parameters step by step collaboratively. Experimental results show that the booster signal can improve both the natural and robust accuracies over the recent state-of-the-art adversarial training methods. Also, optimizing the booster signal is general and flexible enough to be adopted on any existing adversarial training methods.
Defending Against Person Hiding Adversarial Patch Attack with a Universal White Frame
Apr 27, 2022

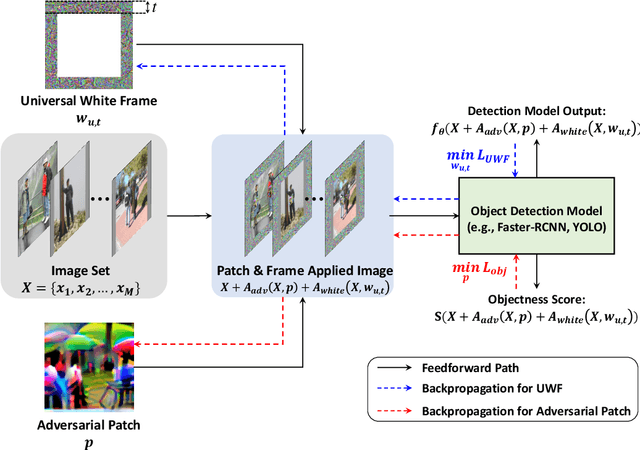
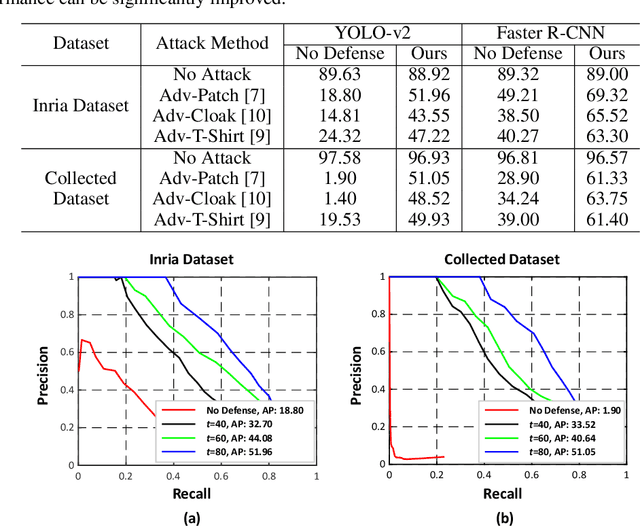
Object detection has attracted great attention in the computer vision area and has emerged as an indispensable component in many vision systems. In the era of deep learning, many high-performance object detection networks have been proposed. Although these detection networks show high performance, they are vulnerable to adversarial patch attacks. Changing the pixels in a restricted region can easily fool the detection network in the physical world. In particular, person-hiding attacks are emerging as a serious problem in many safety-critical applications such as autonomous driving and surveillance systems. Although it is necessary to defend against an adversarial patch attack, very few efforts have been dedicated to defending against person-hiding attacks. To tackle the problem, in this paper, we propose a novel defense strategy that mitigates a person-hiding attack by optimizing defense patterns, while previous methods optimize the model. In the proposed method, a frame-shaped pattern called a 'universal white frame' (UWF) is optimized and placed on the outside of the image. To defend against adversarial patch attacks, UWF should have three properties (i) suppressing the effect of the adversarial patch, (ii) maintaining its original prediction, and (iii) applicable regardless of images. To satisfy the aforementioned properties, we propose a novel pattern optimization algorithm that can defend against the adversarial patch. Through comprehensive experiments, we demonstrate that the proposed method effectively defends against the adversarial patch attack.
Investigating Vulnerability to Adversarial Examples on Multimodal Data Fusion in Deep Learning
May 22, 2020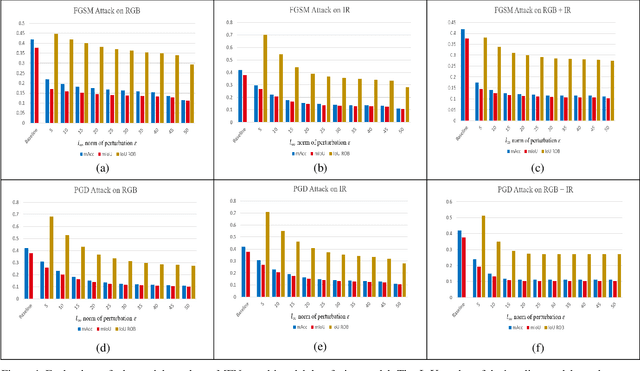
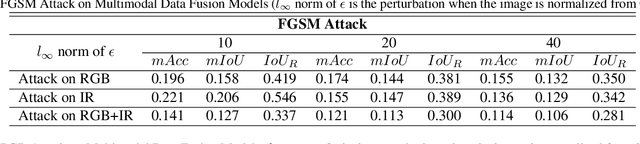

The success of multimodal data fusion in deep learning appears to be attributed to the use of complementary in-formation between multiple input data. Compared to their predictive performance, relatively less attention has been devoted to the robustness of multimodal fusion models. In this paper, we investigated whether the current multimodal fusion model utilizes the complementary intelligence to defend against adversarial attacks. We applied gradient based white-box attacks such as FGSM and PGD on MFNet, which is a major multispectral (RGB, Thermal) fusion deep learning model for semantic segmentation. We verified that the multimodal fusion model optimized for better prediction is still vulnerable to adversarial attack, even if only one of the sensors is attacked. Thus, it is hard to say that existing multimodal data fusion models are fully utilizing complementary relationships between multiple modalities in terms of adversarial robustness. We believe that our observations open a new horizon for adversarial attack research on multimodal data fusion.