 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD: Modality-Adaptive Decoding for Mitigating Cross-Modal Hallucinations in Multimodal Large Language Models
Jan 29, 2026Multimodal Large Language Models (MLLMs) suffer from cross-modal hallucinations, where one modality inappropriately influences generation about another, leading to fabricated output. This exposes a more fundamental deficiency in modality-interaction control. To address this, we propose Modality-Adaptive Decoding (MAD), a training-free method that adaptively weights modality-specific decoding branches based on task requirements. MAD leverages the model's inherent ability to self-assess modality relevance by querying which modalities are needed for each task. The extracted modality probabilities are then used to adaptively weight contrastive decoding branches, enabling the model to focus on relevant information while suppressing cross-modal interference. Extensive experiments on CMM and AVHBench demonstrate that MAD significantly reduces cross-modal hallucinations across multiple audio-visual language models (7.8\% and 2.0\% improvements for VideoLLaMA2-AV, 8.7\% and 4.7\% improvements for Qwen2.5-Omni). Our approach demonstrates that explicit modality awareness through self-assessment is crucial for robust multimodal reasoning, offering a principled extension to existing contrastive decoding methods. Our code is available at \href{https://github.com/top-yun/MAD}{https://github.com/top-yun/MAD}
Robust Egocentric Visual Attention Prediction Through Language-guided Scene Context-aware Learning
Jan 05, 2026As the demand for analyzing egocentric videos grows, egocentric visual attention prediction, anticipating where a camera wearer will attend, has garnered increasing attention. However, it remains challenging due to the inherent complexity and ambiguity of dynamic egocentric scenes. Motivated by evidence that scene contextual information plays a crucial role in modulating human attention, in this paper, we present a language-guided scene context-aware learning framework for robust egocentric visual attention prediction. We first design a context perceiver which is guided to summarize the egocentric video based on a language-based scene description, generating context-aware video representations. We then introduce two training objectives that: 1) encourage the framework to focus on the target point-of-interest regions and 2) suppress distractions from irrelevant regions which are less likely to attract first-person attention. Extensive experiments on Ego4D and Aria Everyday Activities (AEA) datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance and enhanced robustness across diverse, dynamic egocentric scenarios.
GCAgent: Long-Video Understanding via Schematic and Narrative Episodic Memory
Nov 15, 2025Long-video understanding remains a significant challenge for Multimodal Large Language Models (MLLMs) due to inherent token limitations and the complexity of capturing long-term temporal dependencies. Existing methods often fail to capture the global context and complex event relationships necessary for deep video reasoning. To address this, we introduce GCAgent, a novel Global-Context-Aware Agent framework that achieves comprehensive long-video understanding. Our core innovation is the Schematic and Narrative Episodic Memory. This memory structurally models events and their causal and temporal relations into a concise, organized context, fundamentally resolving the long-term dependency problem. Operating in a multi-stage Perception-Action-Reflection cycle, our GCAgent utilizes a Memory Manager to retrieve relevant episodic context for robust, context-aware inference. Extensive experiments confirm that GCAgent significantly enhances long-video understanding, achieving up to 23.5\% accuracy improvement on the Video-MME Long split over a strong MLLM baseline. Furthermore, our framework establishes state-of-the-art performance among comparable 7B-scale MLLMs, achieving 73.4\% accuracy on the Long split and the highest overall average (71.9\%) on the Video-MME benchmark, validating our agent-based reasoning paradigm and structured memory for cognitively-inspired long-video understanding.
Unified Reinforcement and Imitation Learning for Vision-Language Models
Oct 22, 2025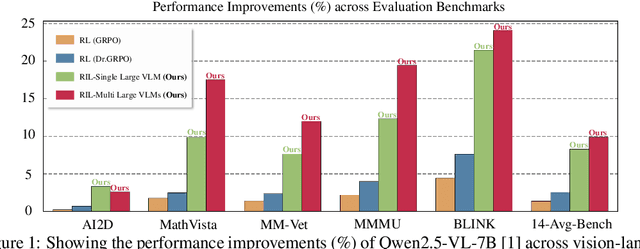



Vision-Language Models (VLMs) have achieved remarkable progress, yet their large scale often renders them impractical for resource-constrained environments. This paper introduces Unified Reinforcement and Imitation Learning (RIL), a novel and efficient training algorithm designed to create powerful, lightweight VLMs. RIL distinctively combines the strengths of reinforcement learning with adversarial imitation learning. This enables smaller student VLMs not only to mimic the sophisticated text generation of large teacher models but also to systematically improve their generative capabilities through reinforcement signals. Key to our imitation framework is an LLM-based discriminator that adeptly distinguishes between student and teacher outputs, complemented by guidance from multiple large teacher VLMs to ensure diverse learning. This unified learning strategy, leveraging both reinforcement and imitation, empowers student models to achieve significant performance gains, making them competitive with leading closed-source VLMs. Extensive experiments on diverse vision-language benchmarks demonstrate that RIL significantly narrows the performance gap with state-of-the-art open- and closed-source VLMs and, in several instances, surpasses them.
GenRecal: Generation after Recalibration from Large to Small Vision-Language Models
Jun 18, 2025Recent advancements in vision-language models (VLMs) have leveraged large language models (LLMs) to achieve performance on par with closed-source systems like GPT-4V. However, deploying these models in real-world scenarios, particularly on resource-constrained devices, remains challenging due to their substantial computational demands. This has spurred interest in distilling knowledge from large VLMs into smaller, more efficient counterparts. A key challenge arises here from the diversity of VLM architectures, which are built on different LLMs and employ varying token types-differing in vocabulary size, token splits, and token index ordering. To address this challenge of limitation to a specific VLM type, we present Generation after Recalibration (GenRecal), a novel, general-purpose distillation framework for VLMs. GenRecal incorporates a Recalibrator that aligns and adapts feature representations between heterogeneous VLMs, enabling effective knowledge transfer across different types of VLMs. Through extensive experiments on multiple challenging benchmarks, we demonstrate that GenRecal significantly improves baseline performances, eventually outperforming large-scale open- and closed-source VLMs.
Language-guided Learning for Object Detection Tackling Multiple Variations in Aerial Images
May 29, 2025Despite recent advancements in computer vision research, object detection in aerial images still suffers from several challenges. One primary challenge to be mitigated is the presence of multiple types of variation in aerial images, for example, illumination and viewpoint changes. These variations result in highly diverse image scenes and drastic alterations in object appearance, so that it becomes more complicated to localize objects from the whole image scene and recognize their categories. To address this problem, in this paper, we introduce a novel object detection framework in aerial images, named LANGuage-guided Object detection (LANGO). Upon the proposed language-guided learning, the proposed framework is designed to alleviate the impacts from both scene and instance-level variations. First, we are motivated by the way humans understand the semantics of scenes while perceiving environmental factors in the scenes (e.g., weather). Therefore, we design a visual semantic reasoner that comprehends visual semantics of image scenes by interpreting conditions where the given images were captured. Second, we devise a training objective, named relation learning loss, to deal with instance-level variations, such as viewpoint angle and scale changes. This training objective aims to learn relations in language representations of object categories, with the help of the robust characteristics against such variations. Through extensive experiments, we demonstrate the effectiveness of the proposed method, and our method obtains noticeable detection performance improvements.
DIP-R1: Deep Inspection and Perception with RL Looking Through and Understanding Complex Scenes
May 29, 2025Multimodal Large Language Models (MLLMs) have demonstrated significant visual understanding capabilities, yet their fine-grained visual perception in complex real-world scenarios, such as densely crowded public areas, remains limited. Inspired by the recent success of reinforcement learning (RL) in both LLMs and MLLMs, in this paper, we explore how RL can enhance visual perception ability of MLLMs. Then we develop a novel RL-based framework, Deep Inspection and Perception with RL (DIP-R1) designed to enhance the visual perception capabilities of MLLMs, by comprehending complex scenes and looking through visual instances closely. DIP-R1 guides MLLMs through detailed inspection of visual scene via three simply designed rule-based reward modelings. First, we adopt a standard reasoning reward encouraging the model to include three step-by-step processes: 1) reasoning for understanding visual scenes, 2) observing for looking through interested but ambiguous regions, and 3) decision-making for predicting answer. Second, a variance-guided looking reward is designed to examine uncertain regions for the second observing process. It explicitly enables the model to inspect ambiguous areas, improving its ability to mitigate perceptual uncertainties. Third, we model a weighted precision-recall accuracy reward enhancing accurate decision-making. We explore its effectiveness across diverse fine-grained object detection data consisting of challenging real-world environments, such as densely crowded scenes. Built upon existing MLLMs, DIP-R1 achieves consistent and significant improvement across various in-domain and out-of-domain scenarios. It also outperforms various existing baseline models and supervised fine-tuning methods. Our findings highlight the substantial potential of integrating RL into MLLMs for enhancing capabilities in complex real-world perception tasks.
MMS-LLaMA: Efficient LLM-based Audio-Visual Speech Recognition with Minimal Multimodal Speech Tokens
Mar 14, 2025



Audio-Visual Speech Recognition (AVSR) achieves robust speech recognition in noisy environments by combining auditory and visual information. However, recent Large Language Model (LLM) based AVSR systems incur high computational costs due to the high temporal resolution of audio-visual speech processed by LLMs. In this work, we introduce an efficient multimodal speech LLM framework that minimizes token length while preserving essential linguistic content. Our approach employs an early av-fusion module for streamlined feature integration, an audio-visual speech Q-Former that dynamically allocates tokens based on input duration, and a refined query allocation strategy with a speech rate predictor to adjust token allocation according to speaking speed of each audio sample. Extensive experiments on the LRS3 dataset show that our method achieves state-of-the-art performance with a WER of 0.74% while using only 3.5 tokens per second. Moreover, our approach not only reduces token usage by 86% compared to the previous multimodal speech LLM framework, but also improves computational efficiency by reducing FLOPs by 35.7%.
Zero-AVSR: Zero-Shot Audio-Visual Speech Recognition with LLMs by Learning Language-Agnostic Speech Representations
Mar 08, 2025We explore a novel zero-shot Audio-Visual Speech Recognition (AVSR) framework, dubbed Zero-AVSR, which enables speech recognition in target languages without requiring any audio-visual speech data in those languages. Specifically, we introduce the Audio-Visual Speech Romanizer (AV-Romanizer), which learns language-agnostic speech representations by predicting Roman text. Then, by leveraging the strong multilingual modeling capabilities of Large Language Models (LLMs), we propose converting the predicted Roman text into language-specific graphemes, forming the proposed Cascaded Zero-AVSR. Taking it a step further, we explore a unified Zero-AVSR approach by directly integrating the audio-visual speech representations encoded by the AV-Romanizer into the LLM. This is achieved through finetuning the adapter and the LLM using our proposed multi-task learning scheme. To capture the wide spectrum of phonetic and linguistic diversity, we also introduce a Multilingual Audio-Visual Romanized Corpus (MARC) consisting of 2,916 hours of audio-visual speech data across 82 languages, along with transcriptions in both language-specific graphemes and Roman text. Extensive analysis and experiments confirm that the proposed Zero-AVSR framework has the potential to expand language support beyond the languages seen during the training of the AV-Romanizer.
Are Vision-Language Models Truly Understanding Multi-vision Sensor?
Dec 30, 2024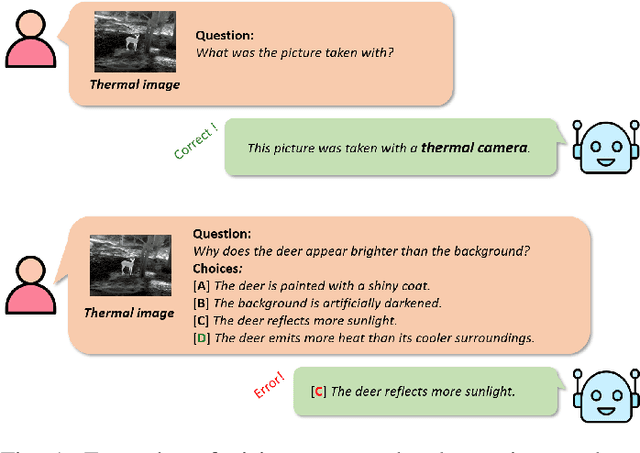
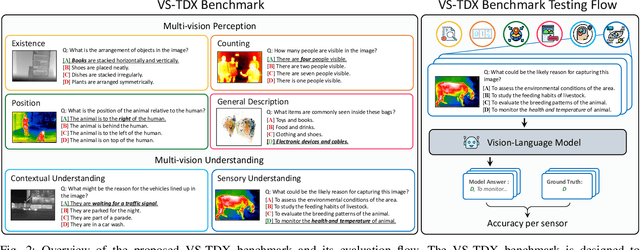
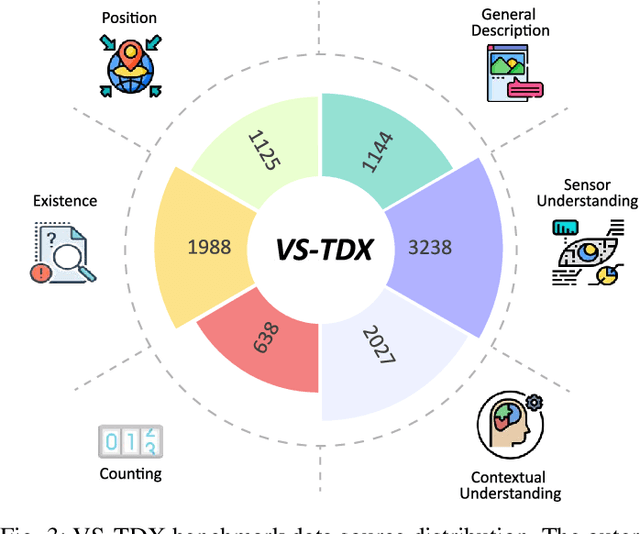

Large-scale Vision-Language Models (VLMs) have advanced by aligning vision inputs with text, significantly improving performance in computer vision tasks. Moreover, for VLMs to be effectively utilized in real-world applications, an understanding of diverse multi-vision sensor data, such as thermal, depth, and X-ray information, is essential. However, we find that current VLMs process multi-vision sensor images without deep understanding of sensor information, disregarding each sensor's unique physical properties. This limitation restricts their capacity to interpret and respond to complex questions requiring multi-vision sensor reasoning. To address this, we propose a novel Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark, assessing VLMs on their capacity for sensor-specific reasoning. Moreover, we introduce Diverse Negative Attributes (DNA) optimization to enable VLMs to perform deep reasoning on multi-vision sensor tasks, helping to bridge the core information gap between images and sensor data. Extensive experimental results validate that the proposed DNA method can significantly improve the multi-vision sensor reasoning for VLMs.