 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Grounding with MLLMs against Occlusion and Small Objects via Language-guided Semantic Cues
Apr 27, 2026While Multimodal Large Language Models (MLLMs) have enhanced grounding capabilities in general scenes, their robustness in crowded scenes remains underexplored. Crowded scenes entail visual challenges (i.e., occlusion and small objects), which impair object semantics and degrade grounding performance. In contrast, language expressions are immune to such degradation and preserve object semantics. In light of these observations, we propose a novel method that overcomes such constraints by leveraging Language-Guided Semantic Cues (LGSCs). Specifically, our approach introduces a Semantic Cue Extractor (SCE) to derive semantic cues of objects from the visual pipeline of an MLLM. We then guide these cues using corresponding text embeddings to produce LGSCs as linguistic semantic priors. Subsequently, they are reintegrated into the original visual pipeline to refine object semantics. Extensive experiments and analyses demonstrate that incorporating LGSCs into an MLLM effectively improves grounding accuracy in crowded scenes.
Video-Oasis: Rethinking Evaluation of Video Understanding
Mar 31, 2026The inherent complexity of video understanding makes it difficult to attribute whether performance gains stem from visual perception, linguistic reasoning, or knowledge priors. While many benchmarks have emerged to assess high-level reasoning, the essential criteria that constitute video understanding remain largely overlooked. Instead of introducing yet another benchmark, we take a step back to re-examine the current landscape of video understanding. In this work, we provide Video-Oasis, a sustainable diagnostic suite designed to systematically evaluate existing evaluations and distill spatio-temporal challenges for video understanding. Our analysis reveals two critical findings: (1) 54% of existing benchmark samples are solvable without visual input or temporal context, and (2) on the remaining samples, state-of-the-art models exhibit performance barely exceeding random guessing. To bridge this gap, we investigate which algorithmic design choices contribute to robust video understanding, providing practical guidelines for future research. We hope our work serves as a standard guideline for benchmark construction and the rigorous evaluation of architecture development. Code is available at https://github.com/sejong-rcv/Video-Oasis.
Robust Egocentric Visual Attention Prediction Through Language-guided Scene Context-aware Learning
Jan 05, 2026As the demand for analyzing egocentric videos grows, egocentric visual attention prediction, anticipating where a camera wearer will attend, has garnered increasing attention. However, it remains challenging due to the inherent complexity and ambiguity of dynamic egocentric scenes. Motivated by evidence that scene contextual information plays a crucial role in modulating human attention, in this paper, we present a language-guided scene context-aware learning framework for robust egocentric visual attention prediction. We first design a context perceiver which is guided to summarize the egocentric video based on a language-based scene description, generating context-aware video representations. We then introduce two training objectives that: 1) encourage the framework to focus on the target point-of-interest regions and 2) suppress distractions from irrelevant regions which are less likely to attract first-person attention. Extensive experiments on Ego4D and Aria Everyday Activities (AEA) datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance and enhanced robustness across diverse, dynamic egocentric scenarios.
GCAgent: Long-Video Understanding via Schematic and Narrative Episodic Memory
Nov 15, 2025Long-video understanding remains a significant challenge for Multimodal Large Language Models (MLLMs) due to inherent token limitations and the complexity of capturing long-term temporal dependencies. Existing methods often fail to capture the global context and complex event relationships necessary for deep video reasoning. To address this, we introduce GCAgent, a novel Global-Context-Aware Agent framework that achieves comprehensive long-video understanding. Our core innovation is the Schematic and Narrative Episodic Memory. This memory structurally models events and their causal and temporal relations into a concise, organized context, fundamentally resolving the long-term dependency problem. Operating in a multi-stage Perception-Action-Reflection cycle, our GCAgent utilizes a Memory Manager to retrieve relevant episodic context for robust, context-aware inference. Extensive experiments confirm that GCAgent significantly enhances long-video understanding, achieving up to 23.5\% accuracy improvement on the Video-MME Long split over a strong MLLM baseline. Furthermore, our framework establishes state-of-the-art performance among comparable 7B-scale MLLMs, achieving 73.4\% accuracy on the Long split and the highest overall average (71.9\%) on the Video-MME benchmark, validating our agent-based reasoning paradigm and structured memory for cognitively-inspired long-video understanding.
Language-guided Learning for Object Detection Tackling Multiple Variations in Aerial Images
May 29, 2025Despite recent advancements in computer vision research, object detection in aerial images still suffers from several challenges. One primary challenge to be mitigated is the presence of multiple types of variation in aerial images, for example, illumination and viewpoint changes. These variations result in highly diverse image scenes and drastic alterations in object appearance, so that it becomes more complicated to localize objects from the whole image scene and recognize their categories. To address this problem, in this paper, we introduce a novel object detection framework in aerial images, named LANGuage-guided Object detection (LANGO). Upon the proposed language-guided learning, the proposed framework is designed to alleviate the impacts from both scene and instance-level variations. First, we are motivated by the way humans understand the semantics of scenes while perceiving environmental factors in the scenes (e.g., weather). Therefore, we design a visual semantic reasoner that comprehends visual semantics of image scenes by interpreting conditions where the given images were captured. Second, we devise a training objective, named relation learning loss, to deal with instance-level variations, such as viewpoint angle and scale changes. This training objective aims to learn relations in language representations of object categories, with the help of the robust characteristics against such variations. Through extensive experiments, we demonstrate the effectiveness of the proposed method, and our method obtains noticeable detection performance improvements.
DIP-R1: Deep Inspection and Perception with RL Looking Through and Understanding Complex Scenes
May 29, 2025Multimodal Large Language Models (MLLMs) have demonstrated significant visual understanding capabilities, yet their fine-grained visual perception in complex real-world scenarios, such as densely crowded public areas, remains limited. Inspired by the recent success of reinforcement learning (RL) in both LLMs and MLLMs, in this paper, we explore how RL can enhance visual perception ability of MLLMs. Then we develop a novel RL-based framework, Deep Inspection and Perception with RL (DIP-R1) designed to enhance the visual perception capabilities of MLLMs, by comprehending complex scenes and looking through visual instances closely. DIP-R1 guides MLLMs through detailed inspection of visual scene via three simply designed rule-based reward modelings. First, we adopt a standard reasoning reward encouraging the model to include three step-by-step processes: 1) reasoning for understanding visual scenes, 2) observing for looking through interested but ambiguous regions, and 3) decision-making for predicting answer. Second, a variance-guided looking reward is designed to examine uncertain regions for the second observing process. It explicitly enables the model to inspect ambiguous areas, improving its ability to mitigate perceptual uncertainties. Third, we model a weighted precision-recall accuracy reward enhancing accurate decision-making. We explore its effectiveness across diverse fine-grained object detection data consisting of challenging real-world environments, such as densely crowded scenes. Built upon existing MLLMs, DIP-R1 achieves consistent and significant improvement across various in-domain and out-of-domain scenarios. It also outperforms various existing baseline models and supervised fine-tuning methods. Our findings highlight the substantial potential of integrating RL into MLLMs for enhancing capabilities in complex real-world perception tasks.
Judgment of Thoughts: Courtroom of the Binary Logical Reasoning in Large Language Models
Sep 25, 2024



This paper proposes a novel prompt engineering technique called Judgment of Thought (JoT) that is specifically tailored for binary logical reasoning tasks. JoT employs three roles$\unicode{x2014}$lawyer, prosecutor, and judge$\unicode{x2014}$to facilitate more reliable and accurate reasoning by the model. In this framework, the judge utilizes a high$\unicode{x2010}$level model, while the lawyer and prosecutor utilize low$\unicode{x2010}$level models. This structure helps the judge better understand the responses from both the lawyer and prosecutor, enabling a more accurate judgment. Experimental results on large language model (LLM) benchmark datasets, such as BigBenchHard and Winogrande, demonstrate that JoT outperforms existing methods, including Chain of Thought (CoT) and Self$\unicode{x2010}$Consistency (SC), in binary logical reasoning tasks. Additionally, in real$\unicode{x2010}$world tasks, such as Fake News Detection and SMS Spam Detection, JoT shows comparable or improved performance compared to existing techniques. JoT significantly enhances the accuracy and reliability of models in binary reasoning tasks and show potential for practical applicability across various domains. Future research should aim to further broaden the applicability of JoT and optimize its implementation for real$\unicode{x2010}$world problem$\unicode{x2010}$solving.
Robust Pedestrian Detection via Constructing Versatile Pedestrian Knowledge Bank
Apr 30, 2024

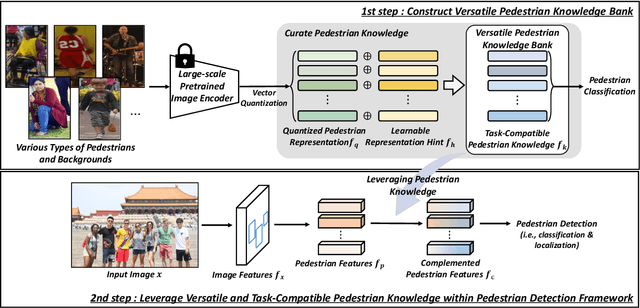

Pedestrian detection is a crucial field of computer vision research which can be adopted in various real-world applications (e.g., self-driving systems). However, despite noticeable evolution of pedestrian detection, pedestrian representations learned within a detection framework are usually limited to particular scene data in which they were trained. Therefore, in this paper, we propose a novel approach to construct versatile pedestrian knowledge bank containing representative pedestrian knowledge which can be applicable to various detection frameworks and adopted in diverse scenes. We extract generalized pedestrian knowledge from a large-scale pretrained model, and we curate them by quantizing most representative features and guiding them to be distinguishable from background scenes. Finally, we construct versatile pedestrian knowledge bank which is composed of such representations, and then we leverage it to complement and enhance pedestrian features within a pedestrian detection framework. Through comprehensive experiments, we validate the effectiveness of our method, demonstrating its versatility and outperforming state-of-the-art detection performances.
Incorporating Language-Driven Appearance Knowledge Units with Visual Cues in Pedestrian Detection
Nov 02, 2023Large language models (LLMs) have shown their capability in understanding contextual and semantic information regarding appearance knowledge of instances. In this paper, we introduce a novel approach to utilize the strength of an LLM in understanding contextual appearance variations and to leverage its knowledge into a vision model (here, pedestrian detection). While pedestrian detection is considered one of crucial tasks directly related with our safety (e.g., intelligent driving system), it is challenging because of varying appearances and poses in diverse scenes. Therefore, we propose to formulate language-driven appearance knowledge units and incorporate them with visual cues in pedestrian detection. To this end, we establish description corpus which includes numerous narratives describing various appearances of pedestrians and others. By feeding them through an LLM, we extract appearance knowledge sets that contain the representations of appearance variations. After that, we perform a task-prompting process to obtain appearance knowledge units which are representative appearance knowledge guided to be relevant to a downstream pedestrian detection task. Finally, we provide plentiful appearance information by integrating the language-driven knowledge units with visual cues. Through comprehensive experiments with various pedestrian detectors, we verify the effectiveness of our method showing noticeable performance gains and achieving state-of-the-art detection performance.