 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-guided Learning for Object Detection Tackling Multiple Variations in Aerial Images
May 29, 2025Despite recent advancements in computer vision research, object detection in aerial images still suffers from several challenges. One primary challenge to be mitigated is the presence of multiple types of variation in aerial images, for example, illumination and viewpoint changes. These variations result in highly diverse image scenes and drastic alterations in object appearance, so that it becomes more complicated to localize objects from the whole image scene and recognize their categories. To address this problem, in this paper, we introduce a novel object detection framework in aerial images, named LANGuage-guided Object detection (LANGO). Upon the proposed language-guided learning, the proposed framework is designed to alleviate the impacts from both scene and instance-level variations. First, we are motivated by the way humans understand the semantics of scenes while perceiving environmental factors in the scenes (e.g., weather). Therefore, we design a visual semantic reasoner that comprehends visual semantics of image scenes by interpreting conditions where the given images were captured. Second, we devise a training objective, named relation learning loss, to deal with instance-level variations, such as viewpoint angle and scale changes. This training objective aims to learn relations in language representations of object categories, with the help of the robust characteristics against such variations. Through extensive experiments, we demonstrate the effectiveness of the proposed method, and our method obtains noticeable detection performance improvements.
TroL: Traversal of Layers for Large Language and Vision Models
Jun 18, 2024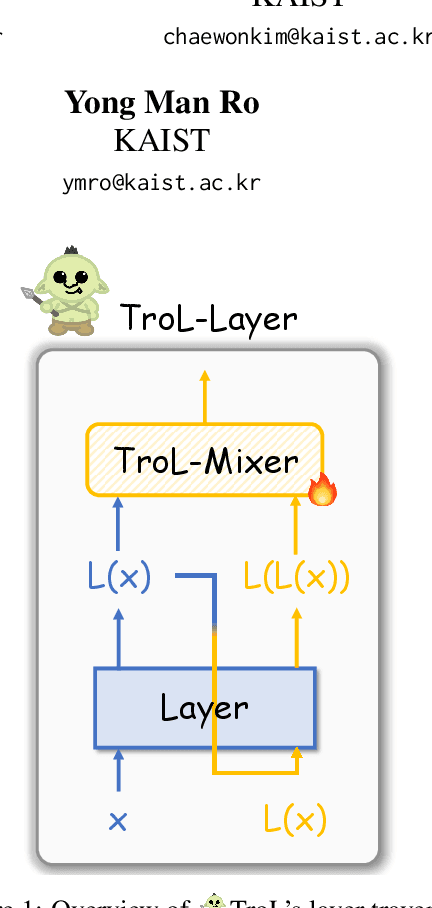
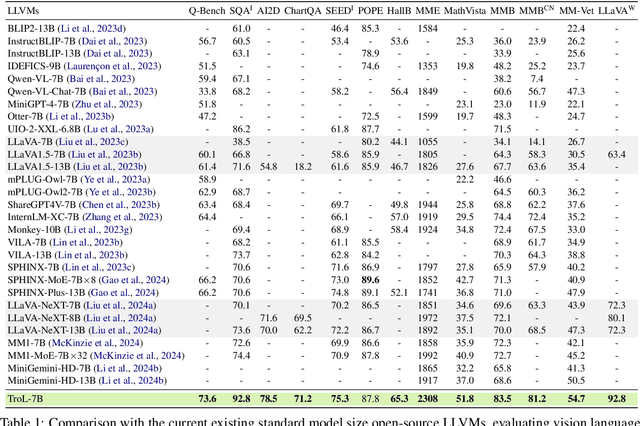
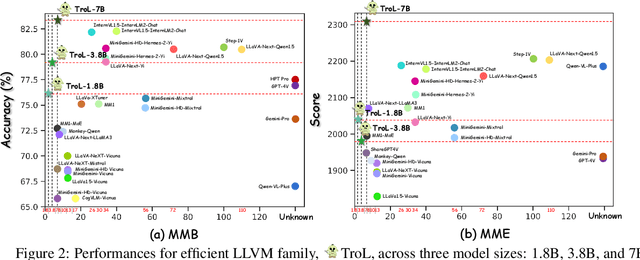
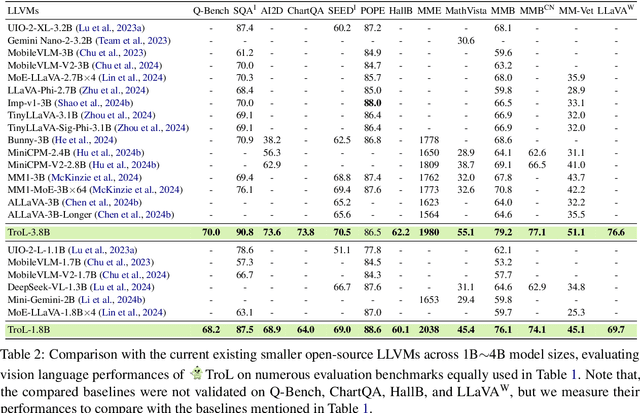
Large language and vision models (LLVMs) have been driven by the generalization power of large language models (LLMs) and the advent of visual instruction tuning. Along with scaling them up directly, these models enable LLVMs to showcase powerful vision language (VL) performances by covering diverse tasks via natural language instructions. However, existing open-source LLVMs that perform comparably to closed-source LLVMs such as GPT-4V are often considered too large (e.g., 26B, 34B, and 110B parameters), having a larger number of layers. These large models demand costly, high-end resources for both training and inference. To address this issue, we present a new efficient LLVM family with 1.8B, 3.8B, and 7B LLM model sizes, Traversal of Layers (TroL), which enables the reuse of layers in a token-wise manner. This layer traversing technique simulates the effect of looking back and retracing the answering stream while increasing the number of forward propagation layers without physically adding more layers. We demonstrate that TroL employs a simple layer traversing approach yet efficiently outperforms the open-source LLVMs with larger model sizes and rivals the performances of the closed-source LLVMs with substantial sizes.
Meteor: Mamba-based Traversal of Rationale for Large Language and Vision Models
May 27, 2024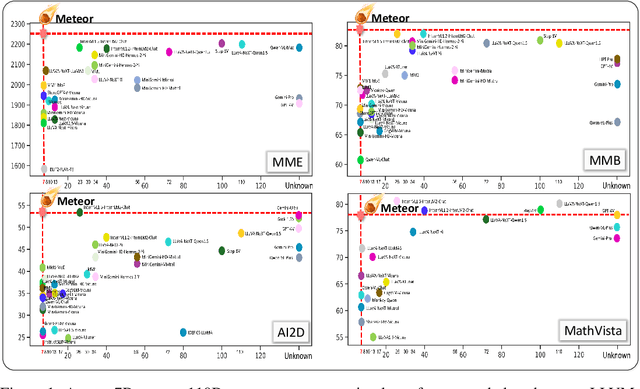
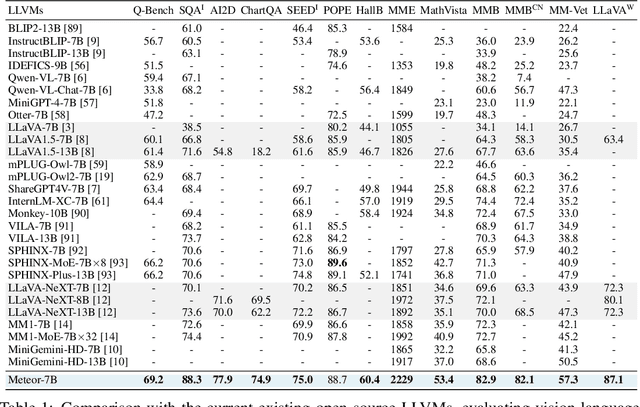
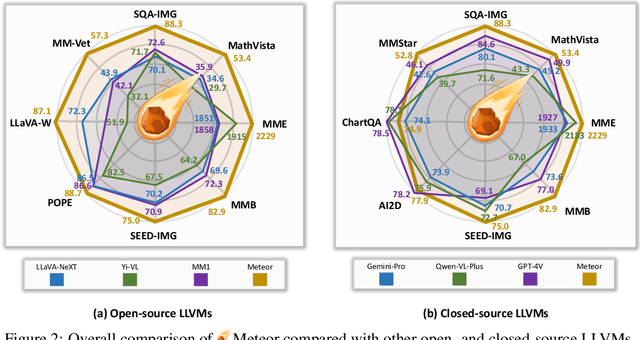

The rapid development of large language and vision models (LLVMs) has been driven by advances in visual instruction tuning. Recently, open-source LLVMs have curated high-quality visual instruction tuning datasets and utilized additional vision encoders or multiple computer vision models in order to narrow the performance gap with powerful closed-source LLVMs. These advancements are attributed to multifaceted information required for diverse capabilities, including fundamental image understanding, real-world knowledge about common-sense and non-object concepts (e.g., charts, diagrams, symbols, signs, and math problems), and step-by-step procedures for solving complex questions. Drawing from the multifaceted information, we present a new efficient LLVM, Mamba-based traversal of rationales (Meteor), which leverages multifaceted rationale to enhance understanding and answering capabilities. To embed lengthy rationales containing abundant information, we employ the Mamba architecture, capable of processing sequential data with linear time complexity. We introduce a new concept of traversal of rationale that facilitates efficient embedding of rationale. Subsequently, the backbone multimodal language model (MLM) is trained to generate answers with the aid of rationale. Through these steps, Meteor achieves significant improvements in vision language performances across multiple evaluation benchmarks requiring diverse capabilities, without scaling up the model size or employing additional vision encoders and computer vision models.
MoAI: Mixture of All Intelligence for Large Language and Vision Models
Mar 12, 2024



The rise of large language models (LLMs) and instruction tuning has led to the current trend of instruction-tuned large language and vision models (LLVMs). This trend involves either meticulously curating numerous instruction tuning datasets tailored to specific objectives or enlarging LLVMs to manage vast amounts of vision language (VL) data. However, current LLVMs have disregarded the detailed and comprehensive real-world scene understanding available from specialized computer vision (CV) models in visual perception tasks such as segmentation, detection, scene graph generation (SGG), and optical character recognition (OCR). Instead, the existing LLVMs rely mainly on the large capacity and emergent capabilities of their LLM backbones. Therefore, we present a new LLVM, Mixture of All Intelligence (MoAI), which leverages auxiliary visual information obtained from the outputs of external segmentation, detection, SGG, and OCR models. MoAI operates through two newly introduced modules: MoAI-Compressor and MoAI-Mixer. After verbalizing the outputs of the external CV models, the MoAI-Compressor aligns and condenses them to efficiently use relevant auxiliary visual information for VL tasks. MoAI-Mixer then blends three types of intelligence (1) visual features, (2) auxiliary features from the external CV models, and (3) language features by utilizing the concept of Mixture of Experts. Through this integration, MoAI significantly outperforms both open-source and closed-source LLVMs in numerous zero-shot VL tasks, particularly those related to real-world scene understanding such as object existence, positions, relations, and OCR without enlarging the model size or curating extra visual instruction tuning datasets.
CoLLaVO: Crayon Large Language and Vision mOdel
Feb 20, 2024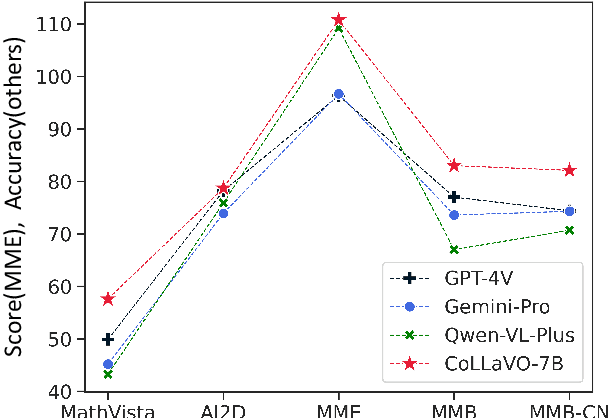
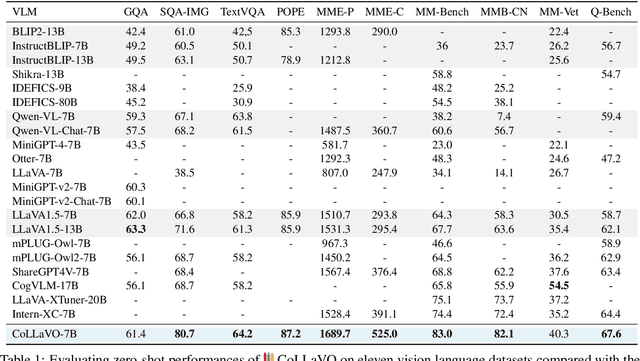

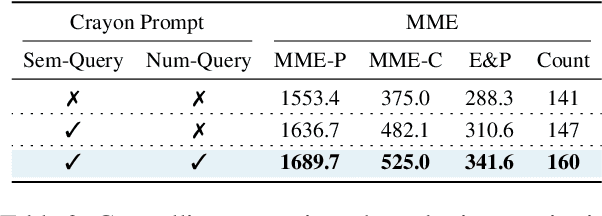
The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model. Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from `what objects are in the image?' or `which object corresponds to a specified bounding box?'. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on vision language (VL) tasks. This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel(CoLLaVO), which incorporates instruction tuning with Crayon Prompt as a new visual prompt tuning scheme based on panoptic color maps. Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in numerous VL benchmarks in a zero-shot setting.