 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD: Modality-Adaptive Decoding for Mitigating Cross-Modal Hallucinations in Multimodal Large Language Models
Jan 29, 2026Multimodal Large Language Models (MLLMs) suffer from cross-modal hallucinations, where one modality inappropriately influences generation about another, leading to fabricated output. This exposes a more fundamental deficiency in modality-interaction control. To address this, we propose Modality-Adaptive Decoding (MAD), a training-free method that adaptively weights modality-specific decoding branches based on task requirements. MAD leverages the model's inherent ability to self-assess modality relevance by querying which modalities are needed for each task. The extracted modality probabilities are then used to adaptively weight contrastive decoding branches, enabling the model to focus on relevant information while suppressing cross-modal interference. Extensive experiments on CMM and AVHBench demonstrate that MAD significantly reduces cross-modal hallucinations across multiple audio-visual language models (7.8\% and 2.0\% improvements for VideoLLaMA2-AV, 8.7\% and 4.7\% improvements for Qwen2.5-Omni). Our approach demonstrates that explicit modality awareness through self-assessment is crucial for robust multimodal reasoning, offering a principled extension to existing contrastive decoding methods. Our code is available at \href{https://github.com/top-yun/MAD}{https://github.com/top-yun/MAD}
GCAgent: Long-Video Understanding via Schematic and Narrative Episodic Memory
Nov 15, 2025Long-video understanding remains a significant challenge for Multimodal Large Language Models (MLLMs) due to inherent token limitations and the complexity of capturing long-term temporal dependencies. Existing methods often fail to capture the global context and complex event relationships necessary for deep video reasoning. To address this, we introduce GCAgent, a novel Global-Context-Aware Agent framework that achieves comprehensive long-video understanding. Our core innovation is the Schematic and Narrative Episodic Memory. This memory structurally models events and their causal and temporal relations into a concise, organized context, fundamentally resolving the long-term dependency problem. Operating in a multi-stage Perception-Action-Reflection cycle, our GCAgent utilizes a Memory Manager to retrieve relevant episodic context for robust, context-aware inference. Extensive experiments confirm that GCAgent significantly enhances long-video understanding, achieving up to 23.5\% accuracy improvement on the Video-MME Long split over a strong MLLM baseline. Furthermore, our framework establishes state-of-the-art performance among comparable 7B-scale MLLMs, achieving 73.4\% accuracy on the Long split and the highest overall average (71.9\%) on the Video-MME benchmark, validating our agent-based reasoning paradigm and structured memory for cognitively-inspired long-video understanding.
Are Vision-Language Models Truly Understanding Multi-vision Sensor?
Dec 30, 2024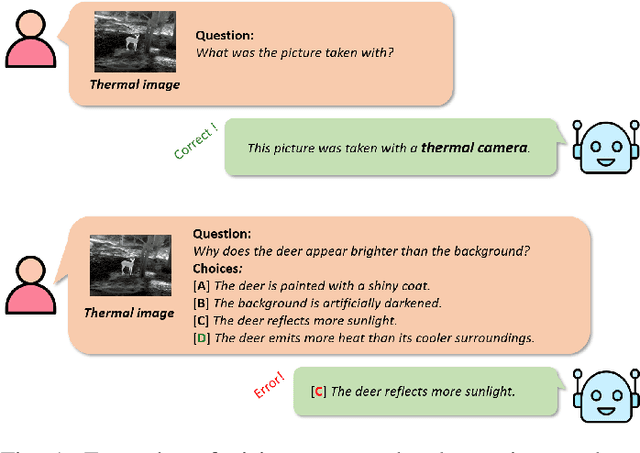

Large-scale Vision-Language Models (VLMs) have advanced by aligning vision inputs with text, significantly improving performance in computer vision tasks. Moreover, for VLMs to be effectively utilized in real-world applications, an understanding of diverse multi-vision sensor data, such as thermal, depth, and X-ray information, is essential. However, we find that current VLMs process multi-vision sensor images without deep understanding of sensor information, disregarding each sensor's unique physical properties. This limitation restricts their capacity to interpret and respond to complex questions requiring multi-vision sensor reasoning. To address this, we propose a novel Multi-vision Sensor Perception and Reasoning (MS-PR) benchmark, assessing VLMs on their capacity for sensor-specific reasoning. Moreover, we introduce Diverse Negative Attributes (DNA) optimization to enable VLMs to perform deep reasoning on multi-vision sensor tasks, helping to bridge the core information gap between images and sensor data. Extensive experimental results validate that the proposed DNA method can significantly improve the multi-vision sensor reasoning for VLMs.
Revisiting Misalignment in Multispectral Pedestrian Detection: A Language-Driven Approach for Cross-modal Alignment Fusion
Nov 27, 2024



Multispectral pedestrian detection is a crucial component in various critical applications. However, a significant challenge arises due to the misalignment between these modalities, particularly under real-world conditions where data often appear heavily misaligned. Conventional methods developed on well-aligned or minimally misaligned datasets fail to address these discrepancies adequately. This paper introduces a new framework for multispectral pedestrian detection designed specifically to handle heavily misaligned datasets without the need for costly and complex traditional pre-processing calibration. By leveraging Large-scale Vision-Language Models (LVLM) for cross-modal semantic alignment, our approach seeks to enhance detection accuracy by aligning semantic information across the RGB and thermal domains. This method not only simplifies the operational requirements but also extends the practical usability of multispectral detection technologies in practical applications.
SPARK: Multi-Vision Sensor Perception and Reasoning Benchmark for Large-scale Vision-Language Models
Aug 23, 2024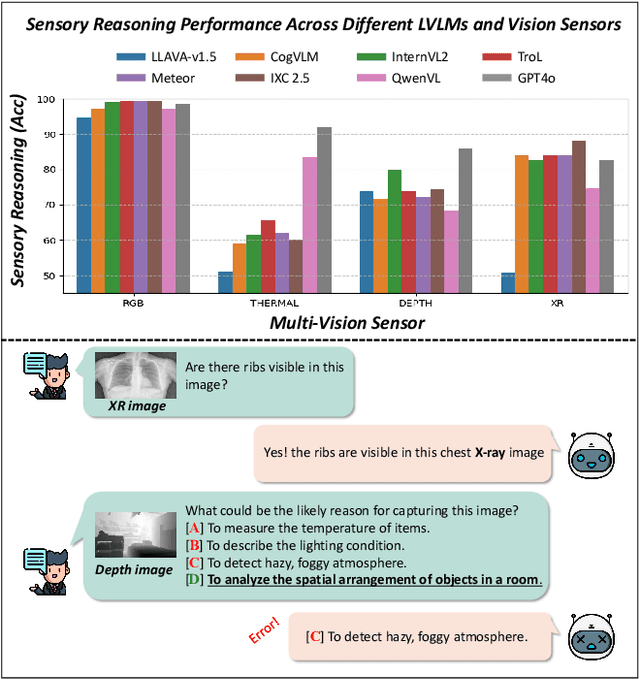
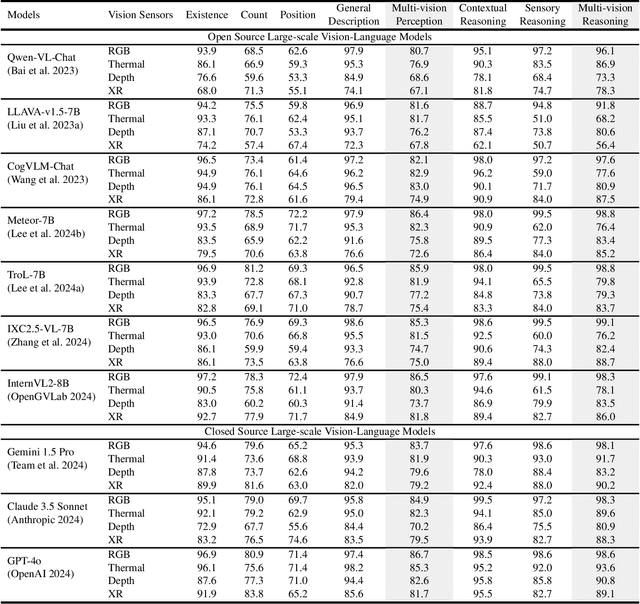
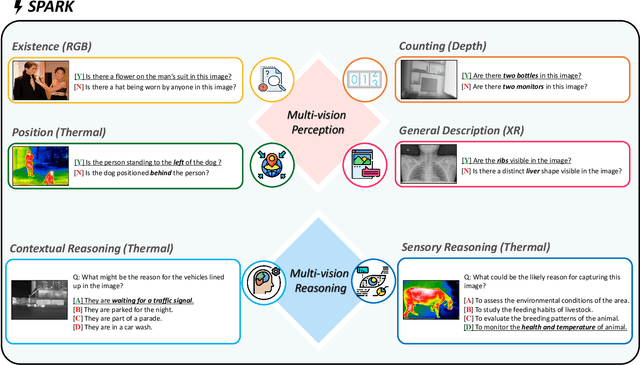
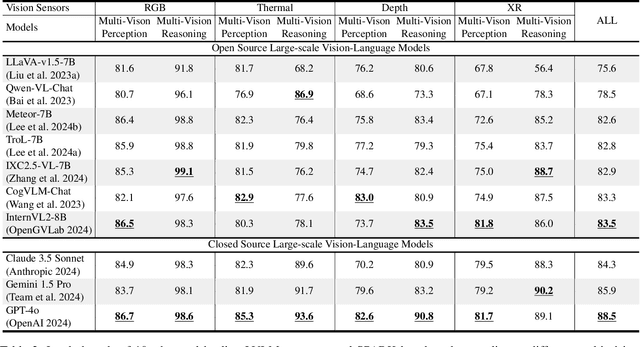
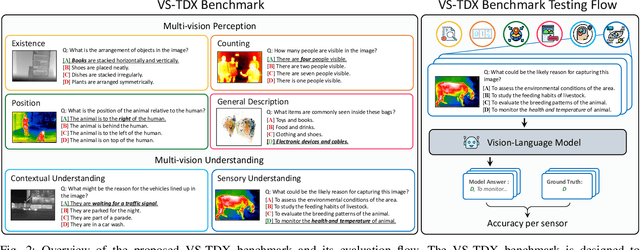
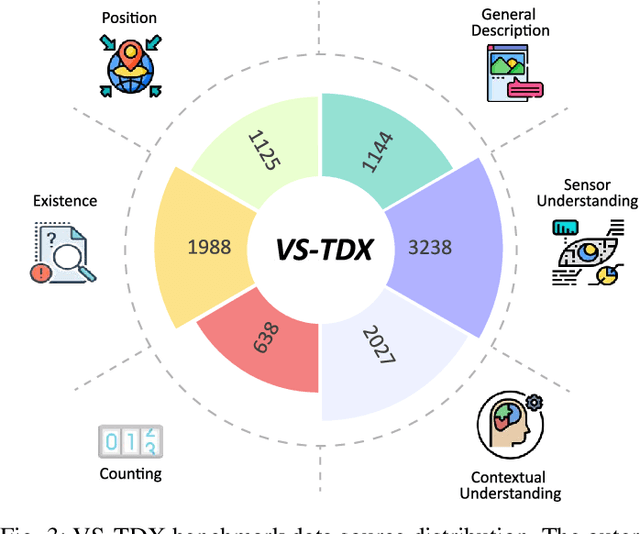
Large-scale Vision-Language Models (LVLMs) have significantly advanced with text-aligned vision inputs. They have made remarkable progress in computer vision tasks by aligning text modality with vision inputs. There are also endeavors to incorporate multi-vision sensors beyond RGB, including thermal, depth, and medical X-ray images. However, we observe that current LVLMs view images taken from multi-vision sensors as if they were in the same RGB domain without considering the physical characteristics of multi-vision sensors. They fail to convey the fundamental multi-vision sensor information from the dataset and the corresponding contextual knowledge properly. Consequently, alignment between the information from the actual physical environment and the text is not achieved correctly, making it difficult to answer complex sensor-related questions that consider the physical environment. In this paper, we aim to establish a multi-vision Sensor Perception And Reasoning benchmarK called SPARK that can reduce the fundamental multi-vision sensor information gap between images and multi-vision sensors. We generated 6,248 vision-language test samples to investigate multi-vision sensory perception and multi-vision sensory reasoning on physical sensor knowledge proficiency across different formats, covering different types of sensor-related questions. We utilized these samples to assess ten leading LVLMs. The results showed that most models displayed deficiencies in multi-vision sensory reasoning to varying extents. Codes and data are available at https://github.com/top-yun/SPARK
TroL: Traversal of Layers for Large Language and Vision Models
Jun 18, 2024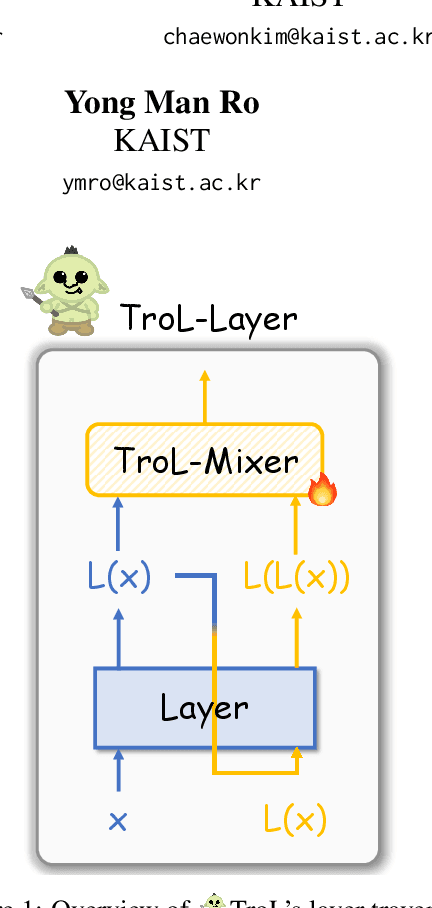
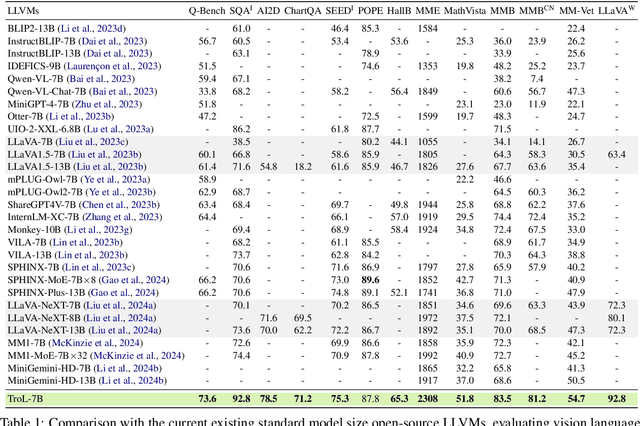
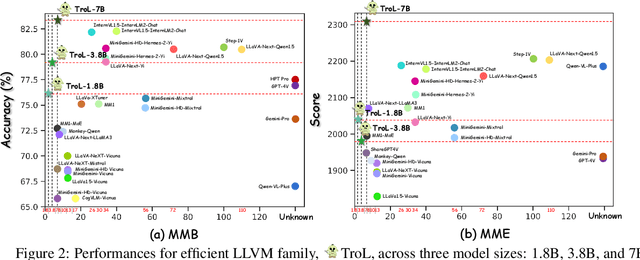
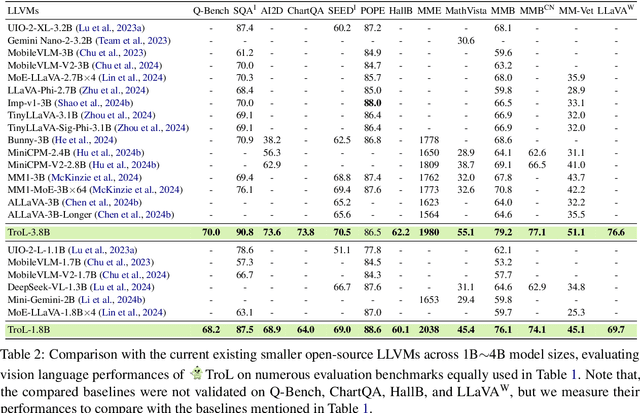
Large language and vision models (LLVMs) have been driven by the generalization power of large language models (LLMs) and the advent of visual instruction tuning. Along with scaling them up directly, these models enable LLVMs to showcase powerful vision language (VL) performances by covering diverse tasks via natural language instructions. However, existing open-source LLVMs that perform comparably to closed-source LLVMs such as GPT-4V are often considered too large (e.g., 26B, 34B, and 110B parameters), having a larger number of layers. These large models demand costly, high-end resources for both training and inference. To address this issue, we present a new efficient LLVM family with 1.8B, 3.8B, and 7B LLM model sizes, Traversal of Layers (TroL), which enables the reuse of layers in a token-wise manner. This layer traversing technique simulates the effect of looking back and retracing the answering stream while increasing the number of forward propagation layers without physically adding more layers. We demonstrate that TroL employs a simple layer traversing approach yet efficiently outperforms the open-source LLVMs with larger model sizes and rivals the performances of the closed-source LLVMs with substantial sizes.
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Mar 22, 2024
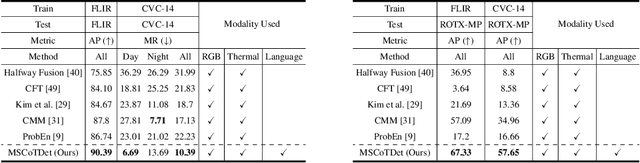

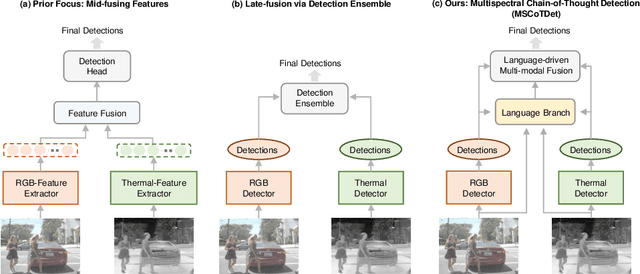
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in obvious cases, especially due to the modality bias learned from statistically biased datasets. From these problems, we anticipate that maybe understanding the complementary information itself is difficult to achieve from vision-only models. Accordingly, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework, which incorporates Large Language Models (LLMs) to understand the complementary information at the semantic level and further enhance the fusion process. Specifically, we generate text descriptions of the pedestrian in each RGB and thermal modality and design a Multispectral Chain-of-Thought (MSCoT) prompting, which models a step-by-step process to facilitate cross-modal reasoning at the semantic level and perform accurate detection. Moreover, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing vision-driven and language-driven detections. Extensive experiments validate that MSCoTDet improves multispectral pedestrian detection.