 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Optical-aware Semantic Control for Aleatoric Refinement in Sar-to-Optical Translation
Jan 11, 2026Synthetic Aperture Radar (SAR) provides robust all-weather imaging capabilities; however, translating SAR observations into photo-realistic optical images remains a fundamentally ill-posed problem. Current approaches are often hindered by the inherent speckle noise and geometric distortions of SAR data, which frequently result in semantic misinterpretation, ambiguous texture synthesis, and structural hallucinations. To address these limitations, a novel SAR-to-Optical (S2O) translation framework is proposed, integrating three core technical contributions: (i) Cross-Modal Semantic Alignment, which establishes an Optical-Aware SAR Encoder by distilling robust semantic priors from an Optical Teacher into a SAR Student (ii) Semantically-Grounded Generative Guidance, realized by a Semantically-Grounded ControlNet that integrates class-aware text prompts for global context with hierarchical visual prompts for local spatial guidance; and (iii) an Uncertainty-Aware Objective, which explicitly models aleatoric uncertainty to dynamically modulate the reconstruction focus, effectively mitigating artifacts caused by speckle-induced ambiguity. Extensive experiments demonstrate that the proposed method achieves superior perceptual quality and semantic consistency compared to state-of-the-art approaches.
Representation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
Revisiting Misalignment in Multispectral Pedestrian Detection: A Language-Driven Approach for Cross-modal Alignment Fusion
Nov 27, 2024



Multispectral pedestrian detection is a crucial component in various critical applications. However, a significant challenge arises due to the misalignment between these modalities, particularly under real-world conditions where data often appear heavily misaligned. Conventional methods developed on well-aligned or minimally misaligned datasets fail to address these discrepancies adequately. This paper introduces a new framework for multispectral pedestrian detection designed specifically to handle heavily misaligned datasets without the need for costly and complex traditional pre-processing calibration. By leveraging Large-scale Vision-Language Models (LVLM) for cross-modal semantic alignment, our approach seeks to enhance detection accuracy by aligning semantic information across the RGB and thermal domains. This method not only simplifies the operational requirements but also extends the practical usability of multispectral detection technologies in practical applications.
An Information Theoretic Metric for Evaluating Unlearning Models
May 28, 2024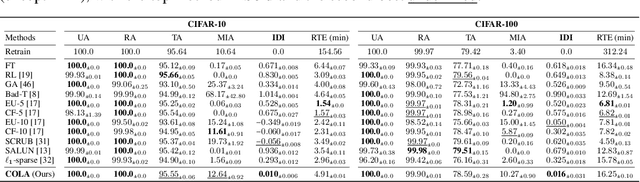
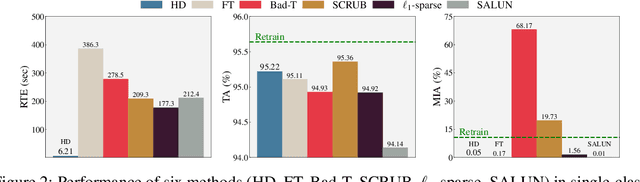
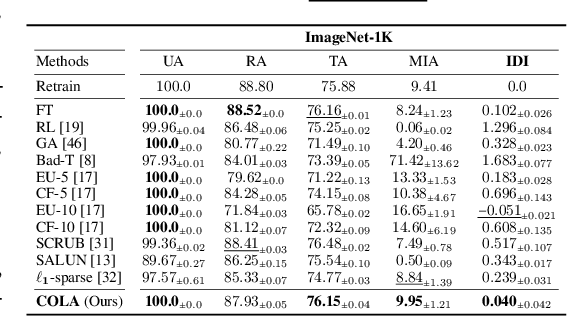
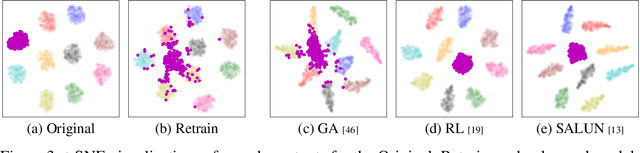
Machine unlearning (MU) addresses privacy concerns by removing information of `forgetting data' samples from trained models. Typically, evaluating MU methods involves comparing unlearned models to those retrained from scratch without forgetting data, using metrics such as membership inference attacks (MIA) and accuracy measurements. These evaluations implicitly assume that if the output logits of the unlearned and retrained models are similar, the unlearned model has successfully forgotten the data. Here, we challenge if this assumption is valid. In particular, we conduct a simple experiment of training only the last layer of a given original model using a novel masked-distillation technique while keeping the rest fixed. Surprisingly, simply altering the last layer yields favorable outcomes in the existing evaluation metrics, while the model does not successfully unlearn the samples or classes. For better evaluating the MU methods, we propose a metric that quantifies the residual information about forgetting data samples in intermediate features using mutual information, called information difference index or IDI for short. The IDI provides a comprehensive evaluation of MU methods by efficiently analyzing the internal structure of DNNs. Our metric is scalable to large datasets and adaptable to various model architectures. Additionally, we present COLapse-and-Align (COLA), a simple contrastive-based method that effectively unlearns intermediate features.
MSCoTDet: Language-driven Multi-modal Fusion for Improved Multispectral Pedestrian Detection
Mar 22, 2024
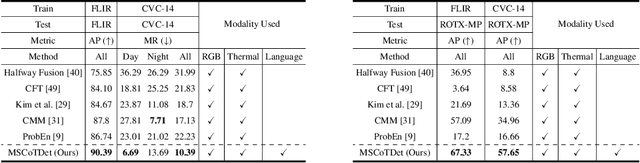

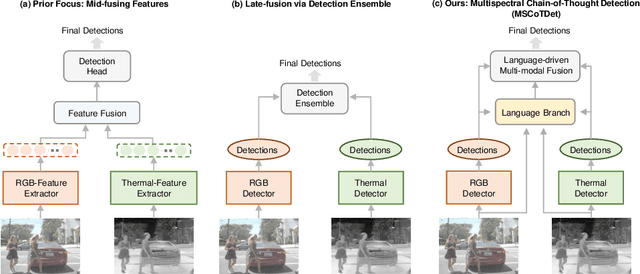
Multispectral pedestrian detection is attractive for around-the-clock applications due to the complementary information between RGB and thermal modalities. However, current models often fail to detect pedestrians in obvious cases, especially due to the modality bias learned from statistically biased datasets. From these problems, we anticipate that maybe understanding the complementary information itself is difficult to achieve from vision-only models. Accordingly, we propose a novel Multispectral Chain-of-Thought Detection (MSCoTDet) framework, which incorporates Large Language Models (LLMs) to understand the complementary information at the semantic level and further enhance the fusion process. Specifically, we generate text descriptions of the pedestrian in each RGB and thermal modality and design a Multispectral Chain-of-Thought (MSCoT) prompting, which models a step-by-step process to facilitate cross-modal reasoning at the semantic level and perform accurate detection. Moreover, we design a Language-driven Multi-modal Fusion (LMF) strategy that enables fusing vision-driven and language-driven detections. Extensive experiments validate that MSCoTDet improves multispectral pedestrian detection.
Causal Mode Multiplexer: A Novel Framework for Unbiased Multispectral Pedestrian Detection
Mar 02, 2024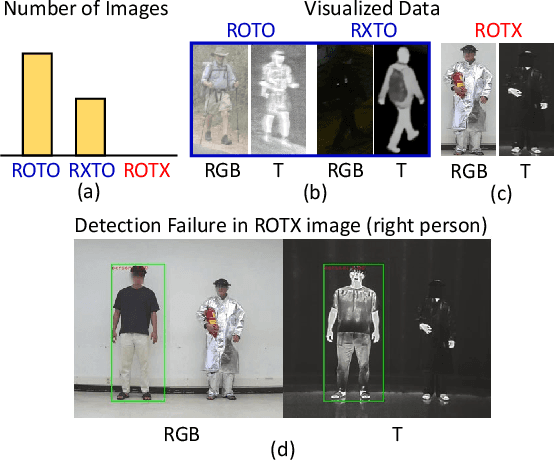
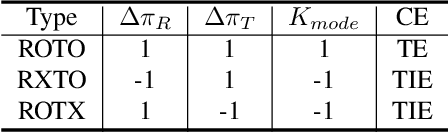
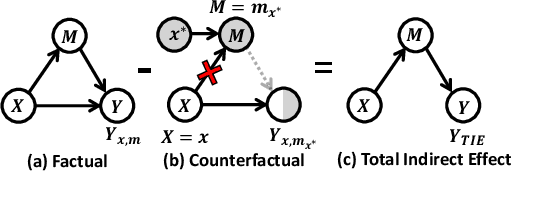
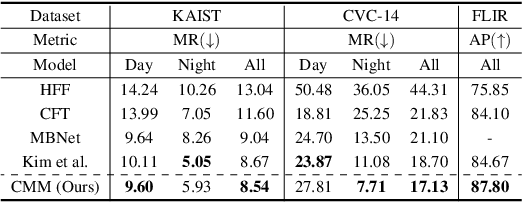
RGBT multispectral pedestrian detection has emerged as a promising solution for safety-critical applications that require day/night operations. However, the modality bias problem remains unsolved as multispectral pedestrian detectors learn the statistical bias in datasets. Specifically, datasets in multispectral pedestrian detection mainly distribute between ROTO (day) and RXTO (night) data; the majority of the pedestrian labels statistically co-occur with their thermal features. As a result, multispectral pedestrian detectors show poor generalization ability on examples beyond this statistical correlation, such as ROTX data. To address this problem, we propose a novel Causal Mode Multiplexer (CMM) framework that effectively learns the causalities between multispectral inputs and predictions. Moreover, we construct a new dataset (ROTX-MP) to evaluate modality bias in multispectral pedestrian detection. ROTX-MP mainly includes ROTX examples not presented in previous datasets. Extensive experiments demonstrate that our proposed CMM framework generalizes well on existing datasets (KAIST, CVC-14, FLIR) and the new ROTX-MP. We will release our new dataset to the public for future research.