 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency-Aware Parallel Decoding via Attention for Diffusion LLMs
Mar 13, 2026Parallel decoding for diffusion LLMs (dLLMs) is difficult because each denoising step provides only token-wise marginal distributions, while unmasking multiple tokens simultaneously requires accounting for inter-token dependencies. We propose Dependency-Aware Parallel Decoding (DAPD), a simple, training-free decoding method that uses self-attention to induce a conditional dependency graph over masked tokens. At each iteration, edges in this graph capture strong token interactions, while non-edges indicate weak dependence. Parallel decoding is then reduced to selecting an independent set on the graph and unmasking the selected tokens in parallel. This avoids co-updating strongly coupled tokens without auxiliary models or retraining. Experiments on LLaDA and Dream show that DAPD improves the accuracy-steps trade-off over existing methods and enables more globally distributed parallel updates that better exploit the any-order generation capability of dLLMs.
Preserve-Then-Quantize: Balancing Rank Budgets for Quantization Error Reconstruction in LLMs
Feb 02, 2026Quantization Error Reconstruction (QER) reduces accuracy loss in Post-Training Quantization (PTQ) by approximating weights as $\mathbf{W} \approx \mathbf{Q} + \mathbf{L}\mathbf{R}$, using a rank-$r$ correction to reconstruct quantization error. Prior methods devote the full rank budget to error reconstruction, which is suboptimal when $\mathbf{W}$ has intrinsic low-rank structure and quantization corrupts dominant directions. We propose Structured Residual Reconstruction (SRR), a rank-allocation framework that preserves the top-$k$ singular subspace of the activation-scaled weight before quantization, quantizes only the residual, and uses the remaining rank $r-k$ for error reconstruction. We derive a theory-guided criterion for selecting $k$ by balancing quantization-exposed energy and unrecoverable error under rank constraints. We further show that resulting $\mathbf{Q} + \mathbf{L}\mathbf{R}$ parameterization naturally supports Quantized Parameter-Efficient Fine-Tuning (QPEFT), and stabilizes fine-tuning via gradient scaling along preserved directions. Experiments demonstrate consistent perplexity reductions across diverse models and quantization settings in PTQ, along with a 5.9 percentage-point average gain on GLUE under 2-bit QPEFT.
Understanding Memorization in Generative Models via Sharpness in Probability Landscapes
Dec 05, 2024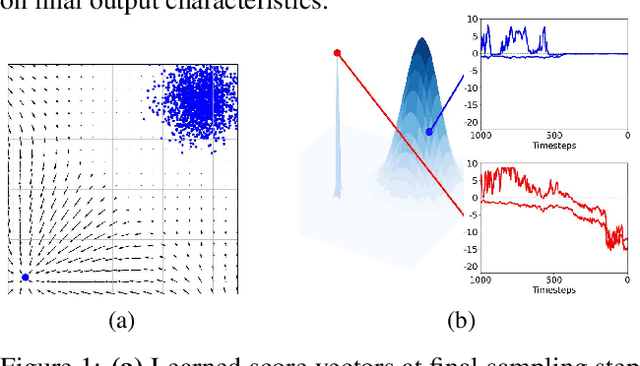
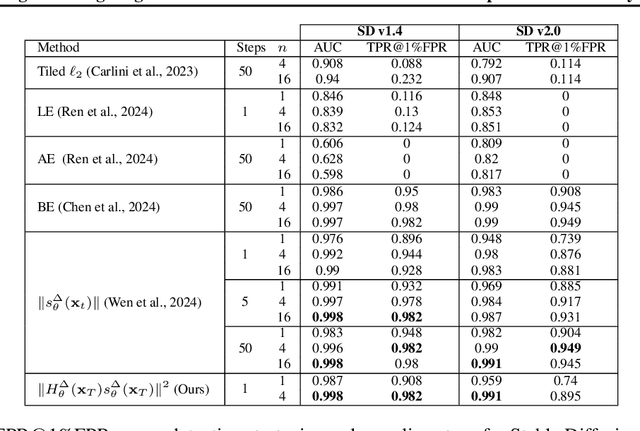
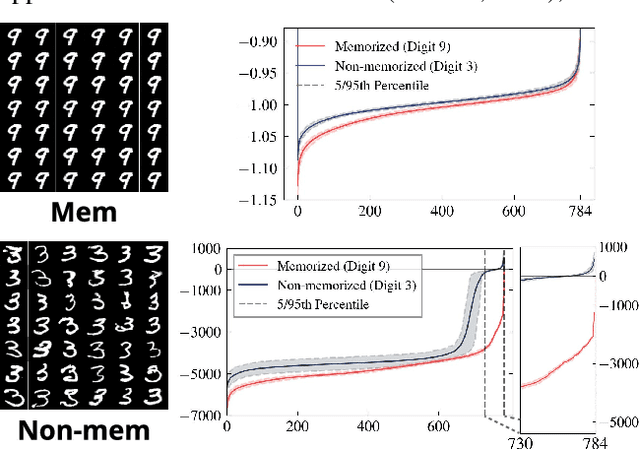
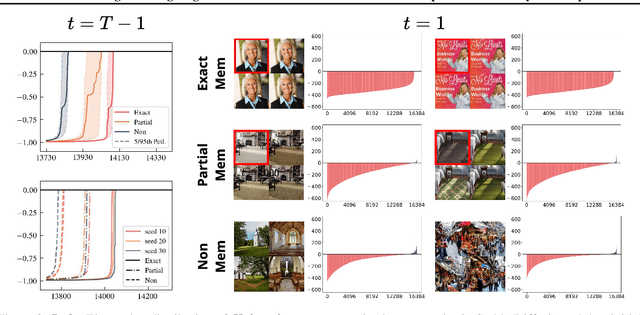
In this paper, we introduce a geometric framework to analyze memorization in diffusion models using the eigenvalues of the Hessian of the log probability density. We propose that memorization arises from isolated points in the learned probability distribution, characterized by sharpness in the probability landscape, as indicated by large negative eigenvalues of the Hessian. Through experiments on various datasets, we demonstrate that these eigenvalues effectively detect and quantify memorization. Our approach provides a clear understanding of memorization in diffusion models and lays the groundwork for developing strategies to ensure secure and reliable generative models
Large Language Models Still Exhibit Bias in Long Text
Oct 23, 2024


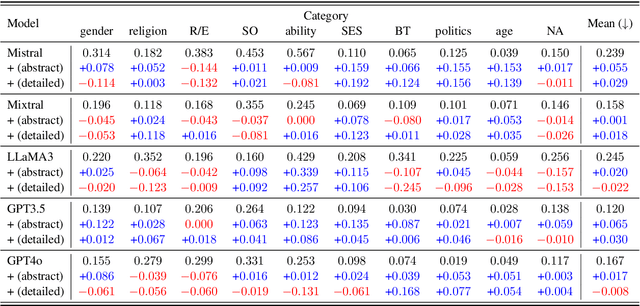
Existing fairness benchmarks for large language models (LLMs) primarily focus on simple tasks, such as multiple-choice questions, overlooking biases that may arise in more complex scenarios like long-text generation. To address this gap, we introduce the Long Text Fairness Test (LTF-TEST), a framework that evaluates biases in LLMs through essay-style prompts. LTF-TEST covers 14 topics and 10 demographic axes, including gender and race, resulting in 11,948 samples. By assessing both model responses and the reasoning behind them, LTF-TEST uncovers subtle biases that are difficult to detect in simple responses. In our evaluation of five recent LLMs, including GPT-4o and LLaMa3, we identify two key patterns of bias. First, these models frequently favor certain demographic groups in their responses. Second, they show excessive sensitivity toward traditionally disadvantaged groups, often providing overly protective responses while neglecting others. To mitigate these biases, we propose FT-REGARD, a finetuning approach that pairs biased prompts with neutral responses. FT-REGARD reduces gender bias by 34.6% and improves performance by 1.4 percentage points on the BBQ benchmark, offering a promising approach to addressing biases in long-text generation tasks.
An Information Theoretic Metric for Evaluating Unlearning Models
May 28, 2024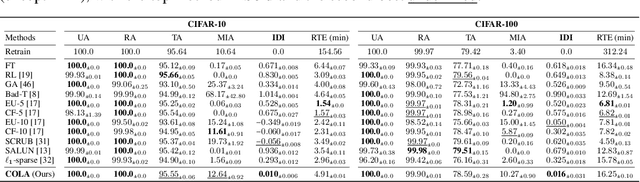
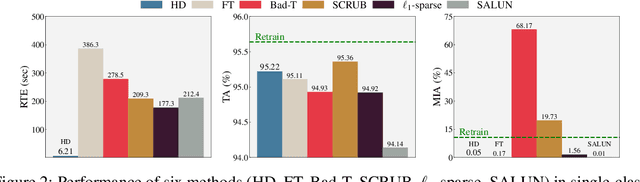
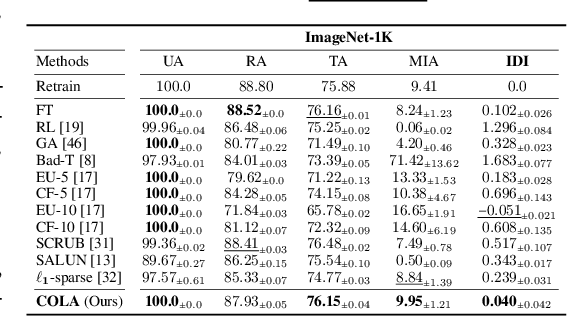
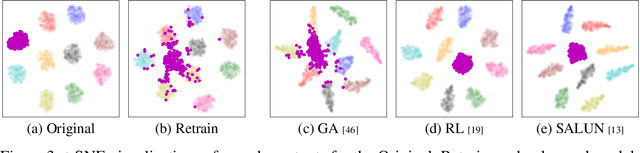
Machine unlearning (MU) addresses privacy concerns by removing information of `forgetting data' samples from trained models. Typically, evaluating MU methods involves comparing unlearned models to those retrained from scratch without forgetting data, using metrics such as membership inference attacks (MIA) and accuracy measurements. These evaluations implicitly assume that if the output logits of the unlearned and retrained models are similar, the unlearned model has successfully forgotten the data. Here, we challenge if this assumption is valid. In particular, we conduct a simple experiment of training only the last layer of a given original model using a novel masked-distillation technique while keeping the rest fixed. Surprisingly, simply altering the last layer yields favorable outcomes in the existing evaluation metrics, while the model does not successfully unlearn the samples or classes. For better evaluating the MU methods, we propose a metric that quantifies the residual information about forgetting data samples in intermediate features using mutual information, called information difference index or IDI for short. The IDI provides a comprehensive evaluation of MU methods by efficiently analyzing the internal structure of DNNs. Our metric is scalable to large datasets and adaptable to various model architectures. Additionally, we present COLapse-and-Align (COLA), a simple contrastive-based method that effectively unlearns intermediate features.