 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
Mar 17, 2026Large language models (LLMs) increasingly store user preferences in persistent memory to support personalization across interactions. However, in third-party communication settings governed by social and institutional norms, some user preferences may be inappropriate to apply. We introduce BenchPreS, which evaluates whether memory-based user preferences are appropriately applied or suppressed across communication contexts. Using two complementary metrics, Misapplication Rate (MR) and Appropriate Application Rate (AAR), we find even frontier LLMs struggle to apply preferences in a context-sensitive manner. Models with stronger preference adherence exhibit higher rates of over-application, and neither reasoning capability nor prompt-based defenses fully resolve this issue. These results suggest current LLMs treat personalized preferences as globally enforceable rules rather than as context-dependent normative signals.
Rethinking Benign Relearning: Syntax as the Hidden Driver of Unlearning Failures
Feb 03, 2026Machine unlearning aims to remove specific content from trained models while preserving overall performance. However, the phenomenon of benign relearning, in which forgotten information reemerges even from benign fine-tuning data, reveals that existing unlearning methods remain fundamentally fragile. A common explanation attributes this effect to topical relevance, but we find this account insufficient. Through systematic analysis, we demonstrate that syntactic similarity, rather than topicality, is the primary driver: across benchmarks, syntactically similar data consistently trigger recovery even without topical overlap, due to their alignment in representations and gradients with the forgotten content. Motivated by this insight, we introduce syntactic diversification, which paraphrases the original forget queries into heterogeneous structures prior to unlearning. This approach effectively suppresses benign relearning, accelerates forgetting, and substantially alleviates the trade-off between unlearning efficacy and model utility.
R-TOFU: Unlearning in Large Reasoning Models
May 21, 2025Large Reasoning Models (LRMs) embed private or copyrighted information not only in their final answers but also throughout multi-step chain-of-thought (CoT) traces, making reliable unlearning far more demanding than in standard LLMs. We introduce Reasoning-TOFU (R-TOFU), the first benchmark tailored to this setting. R-TOFU augments existing unlearning tasks with realistic CoT annotations and provides step-wise metrics that expose residual knowledge invisible to answer-level checks. Using R-TOFU, we carry out a comprehensive comparison of gradient-based and preference-optimization baselines and show that conventional answer-only objectives leave substantial forget traces in reasoning. We further propose Reasoned IDK, a preference-optimization variant that preserves coherent yet inconclusive reasoning, achieving a stronger balance between forgetting efficacy and model utility than earlier refusal styles. Finally, we identify a failure mode: decoding variants such as ZeroThink and LessThink can still reveal forgotten content despite seemingly successful unlearning, emphasizing the need to evaluate models under diverse decoding settings. Together, the benchmark, analysis, and new baseline establish a systematic foundation for studying and improving unlearning in LRMs while preserving their reasoning capabilities.
DUSK: Do Not Unlearn Shared Knowledge
May 21, 2025Large language models (LLMs) are increasingly deployed in real-world applications, raising concerns about the unauthorized use of copyrighted or sensitive data. Machine unlearning aims to remove such 'forget' data while preserving utility and information from the 'retain' set. However, existing evaluations typically assume that forget and retain sets are fully disjoint, overlooking realistic scenarios where they share overlapping content. For instance, a news article may need to be unlearned, even though the same event, such as an earthquake in Japan, is also described factually on Wikipedia. Effective unlearning should remove the specific phrasing of the news article while preserving publicly supported facts. In this paper, we introduce DUSK, a benchmark designed to evaluate unlearning methods under realistic data overlap. DUSK constructs document sets that describe the same factual content in different styles, with some shared information appearing across all sets and other content remaining unique to each. When one set is designated for unlearning, an ideal method should remove its unique content while preserving shared facts. We define seven evaluation metrics to assess whether unlearning methods can achieve this selective removal. Our evaluation of nine recent unlearning methods reveals a key limitation: while most can remove surface-level text, they often fail to erase deeper, context-specific knowledge without damaging shared content. We release DUSK as a public benchmark to support the development of more precise and reliable unlearning techniques for real-world applications.
SEPS: A Separability Measure for Robust Unlearning in LLMs
May 20, 2025Machine unlearning aims to selectively remove targeted knowledge from Large Language Models (LLMs), ensuring they forget specified content while retaining essential information. Existing unlearning metrics assess whether a model correctly answers retain queries and rejects forget queries, but they fail to capture real-world scenarios where forget queries rarely appear in isolation. In fact, forget and retain queries often coexist within the same prompt, making mixed-query evaluation crucial. We introduce SEPS, an evaluation framework that explicitly measures a model's ability to both forget and retain information within a single prompt. Through extensive experiments across three benchmarks, we identify two key failure modes in existing unlearning methods: (1) untargeted unlearning indiscriminately erases both forget and retain content once a forget query appears, and (2) targeted unlearning overfits to single-query scenarios, leading to catastrophic failures when handling multiple queries. To address these issues, we propose Mixed Prompt (MP) unlearning, a strategy that integrates both forget and retain queries into a unified training objective. Our approach significantly improves unlearning effectiveness, demonstrating robustness even in complex settings with up to eight mixed forget and retain queries in a single prompt.
SAFEPATH: Preventing Harmful Reasoning in Chain-of-Thought via Early Alignment
May 20, 2025Large Reasoning Models (LRMs) have become powerful tools for complex problem solving, but their structured reasoning pathways can lead to unsafe outputs when exposed to harmful prompts. Existing safety alignment methods reduce harmful outputs but can degrade reasoning depth, leading to significant trade-offs in complex, multi-step tasks, and remain vulnerable to sophisticated jailbreak attacks. To address this, we introduce SAFEPATH, a lightweight alignment method that fine-tunes LRMs to emit a short, 8-token Safety Primer at the start of their reasoning, in response to harmful prompts, while leaving the rest of the reasoning process unsupervised. Empirical results across multiple benchmarks indicate that SAFEPATH effectively reduces harmful outputs while maintaining reasoning performance. Specifically, SAFEPATH reduces harmful responses by up to 90.0% and blocks 83.3% of jailbreak attempts in the DeepSeek-R1-Distill-Llama-8B model, while requiring 295.9x less compute than Direct Refusal and 314.1x less than SafeChain. We further introduce a zero-shot variant that requires no fine-tuning. In addition, we provide a comprehensive analysis of how existing methods in LLMs generalize, or fail, when applied to reasoning-centric models, revealing critical gaps and new directions for safer AI.
Representation Bending for Large Language Model Safety
Apr 02, 2025Large Language Models (LLMs) have emerged as powerful tools, but their inherent safety risks - ranging from harmful content generation to broader societal harms - pose significant challenges. These risks can be amplified by the recent adversarial attacks, fine-tuning vulnerabilities, and the increasing deployment of LLMs in high-stakes environments. Existing safety-enhancing techniques, such as fine-tuning with human feedback or adversarial training, are still vulnerable as they address specific threats and often fail to generalize across unseen attacks, or require manual system-level defenses. This paper introduces RepBend, a novel approach that fundamentally disrupts the representations underlying harmful behaviors in LLMs, offering a scalable solution to enhance (potentially inherent) safety. RepBend brings the idea of activation steering - simple vector arithmetic for steering model's behavior during inference - to loss-based fine-tuning. Through extensive evaluation, RepBend achieves state-of-the-art performance, outperforming prior methods such as Circuit Breaker, RMU, and NPO, with up to 95% reduction in attack success rates across diverse jailbreak benchmarks, all with negligible reduction in model usability and general capabilities.
Adversarial Sample-Based Approach for Tighter Privacy Auditing in Final Model-Only Scenarios
Dec 02, 2024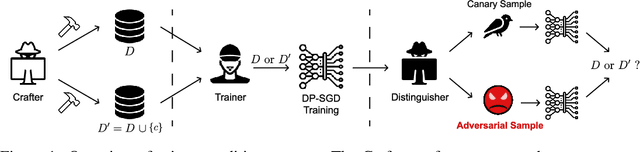

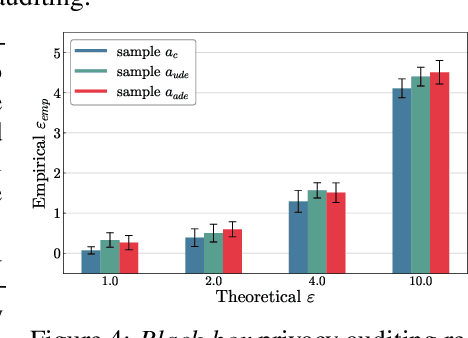
Auditing Differentially Private Stochastic Gradient Descent (DP-SGD) in the final model setting is challenging and often results in empirical lower bounds that are significantly looser than theoretical privacy guarantees. We introduce a novel auditing method that achieves tighter empirical lower bounds without additional assumptions by crafting worst-case adversarial samples through loss-based input-space auditing. Our approach surpasses traditional canary-based heuristics and is effective in both white-box and black-box scenarios. Specifically, with a theoretical privacy budget of $\varepsilon = 10.0$, our method achieves empirical lower bounds of $6.68$ in white-box settings and $4.51$ in black-box settings, compared to the baseline of $4.11$ for MNIST. Moreover, we demonstrate that significant privacy auditing results can be achieved using in-distribution (ID) samples as canaries, obtaining an empirical lower bound of $4.33$ where traditional methods produce near-zero leakage detection. Our work offers a practical framework for reliable and accurate privacy auditing in differentially private machine learning.
Large Language Models Still Exhibit Bias in Long Text
Oct 23, 2024


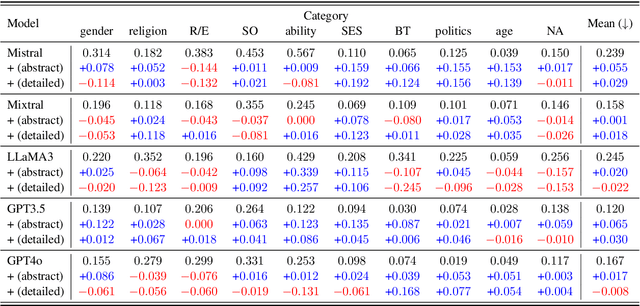
Existing fairness benchmarks for large language models (LLMs) primarily focus on simple tasks, such as multiple-choice questions, overlooking biases that may arise in more complex scenarios like long-text generation. To address this gap, we introduce the Long Text Fairness Test (LTF-TEST), a framework that evaluates biases in LLMs through essay-style prompts. LTF-TEST covers 14 topics and 10 demographic axes, including gender and race, resulting in 11,948 samples. By assessing both model responses and the reasoning behind them, LTF-TEST uncovers subtle biases that are difficult to detect in simple responses. In our evaluation of five recent LLMs, including GPT-4o and LLaMa3, we identify two key patterns of bias. First, these models frequently favor certain demographic groups in their responses. Second, they show excessive sensitivity toward traditionally disadvantaged groups, often providing overly protective responses while neglecting others. To mitigate these biases, we propose FT-REGARD, a finetuning approach that pairs biased prompts with neutral responses. FT-REGARD reduces gender bias by 34.6% and improves performance by 1.4 percentage points on the BBQ benchmark, offering a promising approach to addressing biases in long-text generation tasks.
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments
Jul 26, 2024

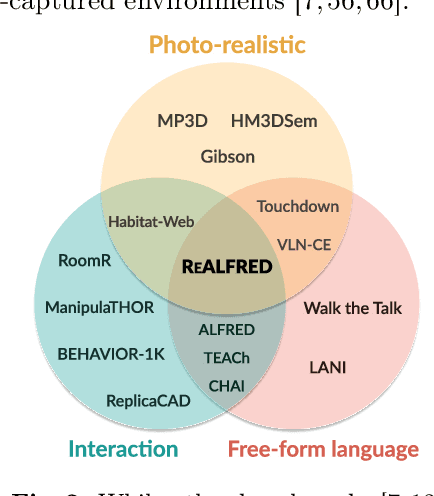

Simulated virtual environments have been widely used to learn robotic agents that perform daily household tasks. These environments encourage research progress by far, but often provide limited object interactability, visual appearance different from real-world environments, or relatively smaller environment sizes. This prevents the learned models in the virtual scenes from being readily deployable. To bridge the gap between these learning environments and deploying (i.e., real) environments, we propose the ReALFRED benchmark that employs real-world scenes, objects, and room layouts to learn agents to complete household tasks by understanding free-form language instructions and interacting with objects in large, multi-room and 3D-captured scenes. Specifically, we extend the ALFRED benchmark with updates for larger environmental spaces with smaller visual domain gaps. With ReALFRED, we analyze previously crafted methods for the ALFRED benchmark and observe that they consistently yield lower performance in all metrics, encouraging the community to develop methods in more realistic environments. Our code and data are publicly available.