 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling Makes Overtraining Compute-Optimal
Apr 01, 2026Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T^2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T^2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T^2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T^2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T^2$ scaling meaningful in modern deployments.
Diabetic Retinopathy Grading with CLIP-based Ranking-Aware Adaptation:A Comparative Study on Fundus Image
Mar 12, 2026Diabetic retinopathy (DR) is a leading cause of preventable blindness, and automated fundus image grading can play an important role in large-scale screening. In this work, we investigate three CLIP-based approaches for five-class DR severity grading: (1) a zero-shot baseline using prompt engineering, (2) a hybrid FCN-CLIP model augmented with CBAM attention, and (3) a ranking-aware prompting model that encodes the ordinal structure of DR progression. We train and evaluate on a combined dataset of APTOS 2019 and Messidor-2 (n=5,406), addressing class imbalance through resampling and class-specific optimal thresholding. Our experiments show that the ranking-aware model achieves the highest overall accuracy (93.42%, AUROC 0.9845) and strong recall on clinically critical severe cases, while the hybrid FCN-CLIP model (92.49%, AUROC 0.99) excels at detecting proliferative DR. Both substantially outperform the zero-shot baseline (55.17%, AUROC 0.75). We analyze the complementary strengths of each approach and discuss their practical implications for screening contexts.
TARDIS: Mitigating Temporal Misalignment via Representation Steering
Mar 25, 2025Language models often struggle with temporal misalignment, performance degradation caused by shifts in the temporal distribution of data. Continuously updating models to avoid degradation is expensive. Can models be adapted without updating model weights? We present TARDIS, an unsupervised representation editing method that addresses this challenge. TARDIS extracts steering vectors from unlabeled data and adjusts the model's representations to better align with the target time period's distribution. Our experiments reveal that TARDIS enhances downstream task performance without the need for fine-tuning, can mitigate temporal misalignment even when exact target time period data is unavailable, and remains efficient even when the temporal information of the target data points is unknown at inference time.
Partial-Multivariate Model for Forecasting
Aug 19, 2024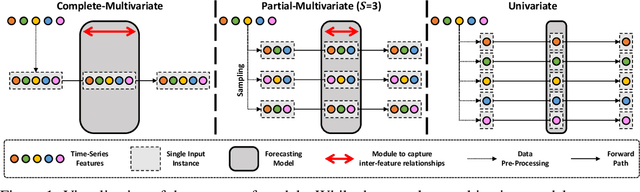
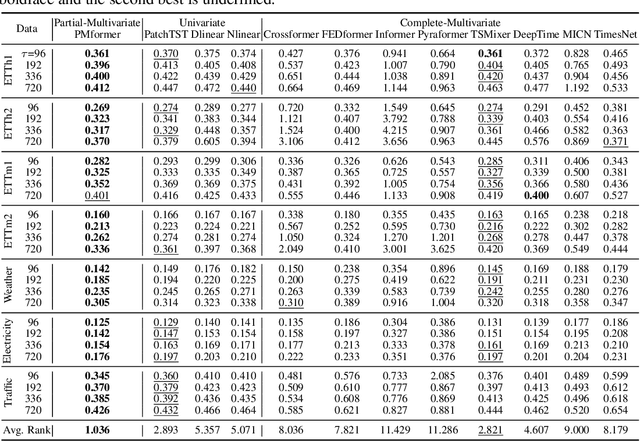

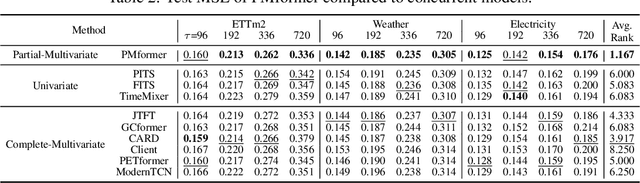
When solving forecasting problems including multiple time-series features, existing approaches often fall into two extreme categories, depending on whether to utilize inter-feature information: univariate and complete-multivariate models. Unlike univariate cases which ignore the information, complete-multivariate models compute relationships among a complete set of features. However, despite the potential advantage of leveraging the additional information, complete-multivariate models sometimes underperform univariate ones. Therefore, our research aims to explore a middle ground between these two by introducing what we term Partial-Multivariate models where a neural network captures only partial relationships, that is, dependencies within subsets of all features. To this end, we propose PMformer, a Transformer-based partial-multivariate model, with its training algorithm. We demonstrate that PMformer outperforms various univariate and complete-multivariate models, providing a theoretical rationale and empirical analysis for its superiority. Additionally, by proposing an inference technique for PMformer, the forecasting accuracy is further enhanced. Finally, we highlight other advantages of PMformer: efficiency and robustness under missing features.
Towards Robust and Cost-Efficient Knowledge Unlearning for Large Language Models
Aug 13, 2024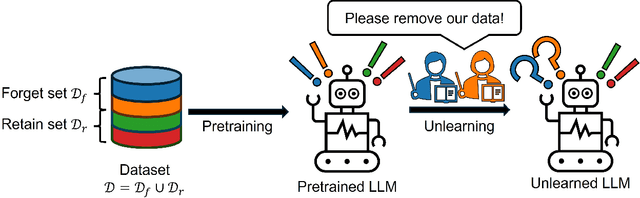
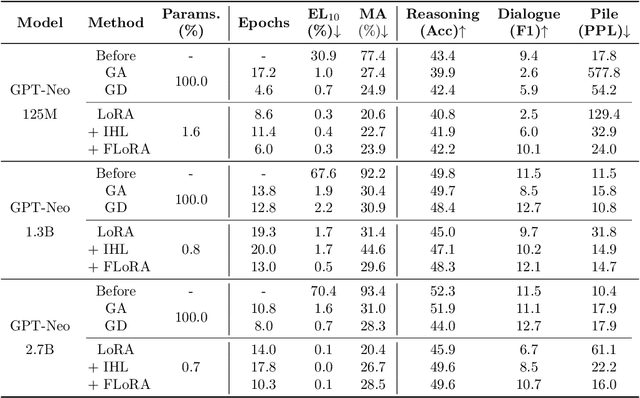
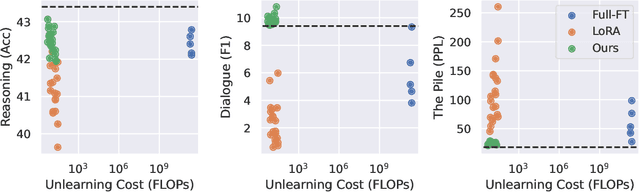
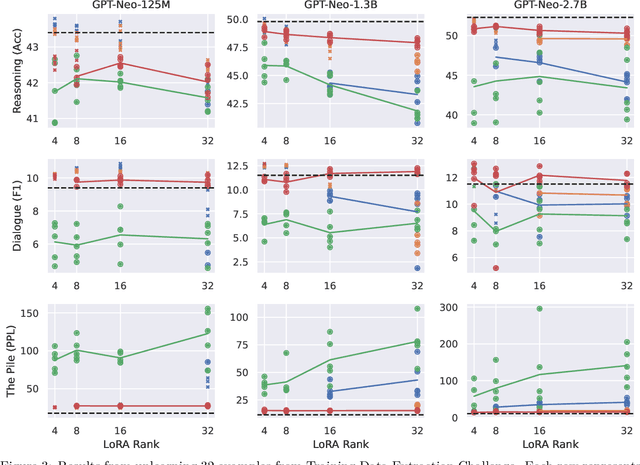
Large Language Models (LLMs) have demonstrated strong reasoning and memorization capabilities via pretraining on massive textual corpora. However, training LLMs on human-written text entails significant risk of privacy and copyright violations, which demands an efficient machine unlearning framework to remove knowledge of sensitive data without retraining the model from scratch. While Gradient Ascent (GA) is widely used for unlearning by reducing the likelihood of generating unwanted information, the unboundedness of increasing the cross-entropy loss causes not only unstable optimization, but also catastrophic forgetting of knowledge that needs to be retained. We also discover its joint application under low-rank adaptation results in significantly suboptimal computational cost vs. generative performance trade-offs. In light of this limitation, we propose two novel techniques for robust and cost-efficient unlearning on LLMs. We first design an Inverted Hinge loss that suppresses unwanted tokens by increasing the probability of the next most likely token, thereby retaining fluency and structure in language generation. We also propose to initialize low-rank adapter weights based on Fisher-weighted low-rank approximation, which induces faster unlearning and better knowledge retention by allowing model updates to be focused on parameters that are important in generating textual data we wish to remove.
Practical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Jul 29, 2024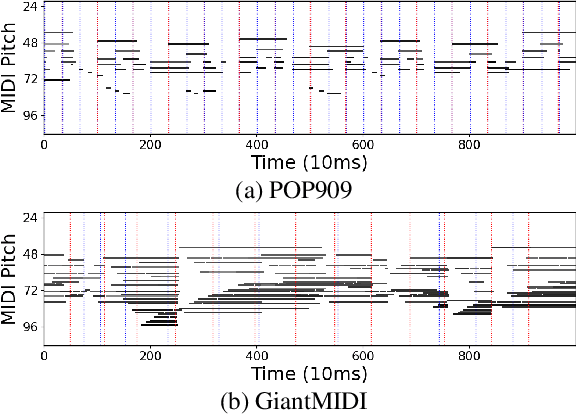
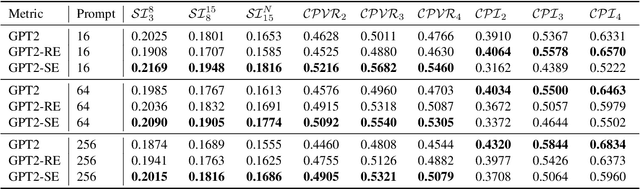
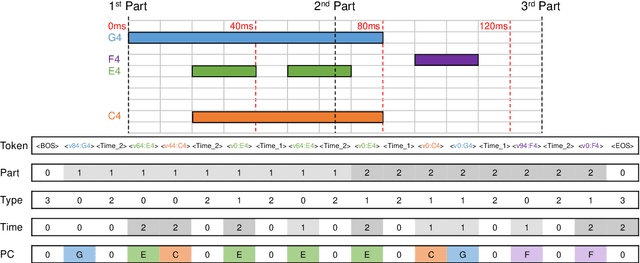

Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.
3D Denoisers are Good 2D Teachers: Molecular Pretraining via Denoising and Cross-Modal Distillation
Sep 08, 2023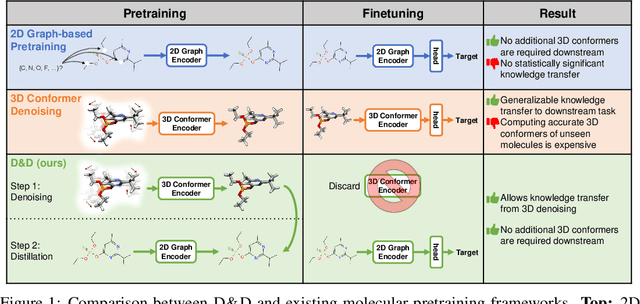
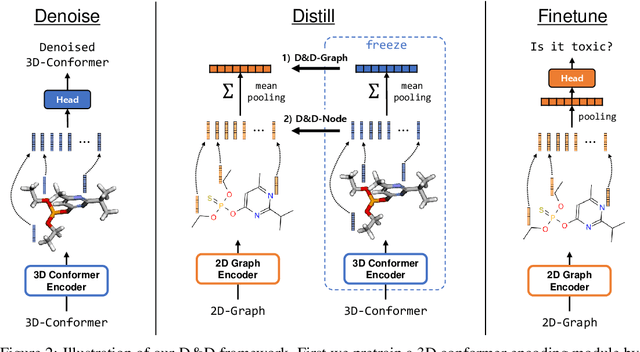
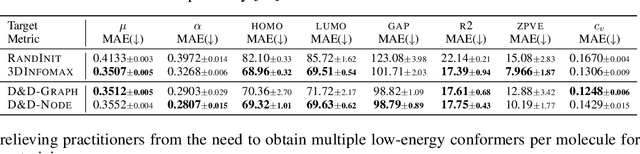
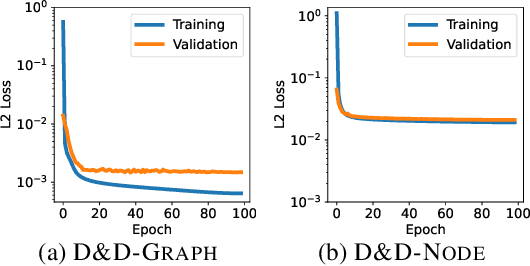
Pretraining molecular representations from large unlabeled data is essential for molecular property prediction due to the high cost of obtaining ground-truth labels. While there exist various 2D graph-based molecular pretraining approaches, these methods struggle to show statistically significant gains in predictive performance. Recent work have thus instead proposed 3D conformer-based pretraining under the task of denoising, which led to promising results. During downstream finetuning, however, models trained with 3D conformers require accurate atom-coordinates of previously unseen molecules, which are computationally expensive to acquire at scale. In light of this limitation, we propose D&D, a self-supervised molecular representation learning framework that pretrains a 2D graph encoder by distilling representations from a 3D denoiser. With denoising followed by cross-modal knowledge distillation, our approach enjoys use of knowledge obtained from denoising as well as painless application to downstream tasks with no access to accurate conformers. Experiments on real-world molecular property prediction datasets show that the graph encoder trained via D&D can infer 3D information based on the 2D graph and shows superior performance and label-efficiency against other baselines.
Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning
Sep 08, 2023Real-world graphs naturally exhibit hierarchical or cyclical structures that are unfit for the typical Euclidean space. While there exist graph neural networks that leverage hyperbolic or spherical spaces to learn representations that embed such structures more accurately, these methods are confined under the message-passing paradigm, making the models vulnerable against side-effects such as oversmoothing and oversquashing. More recent work have proposed global attention-based graph Transformers that can easily model long-range interactions, but their extensions towards non-Euclidean geometry are yet unexplored. To bridge this gap, we propose Fully Product-Stereographic Transformer, a generalization of Transformers towards operating entirely on the product of constant curvature spaces. When combined with tokenized graph Transformers, our model can learn the curvature appropriate for the input graph in an end-to-end fashion, without the need of additional tuning on different curvature initializations. We also provide a kernelized approach to non-Euclidean attention, which enables our model to run in time and memory cost linear to the number of nodes and edges while respecting the underlying geometry. Experiments on graph reconstruction and node classification demonstrate the benefits of generalizing Transformers to the non-Euclidean domain.
Learning to Unlearn: Instance-wise Unlearning for Pre-trained Classifiers
Jan 27, 2023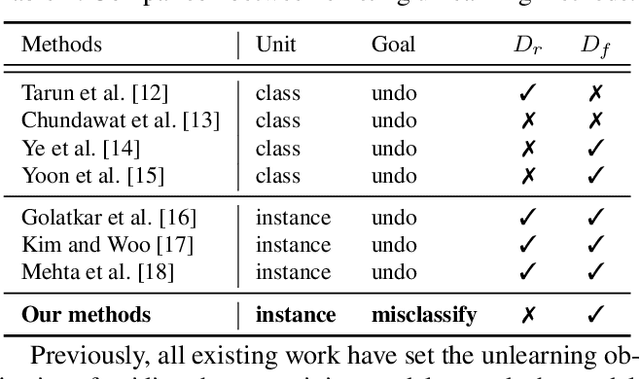
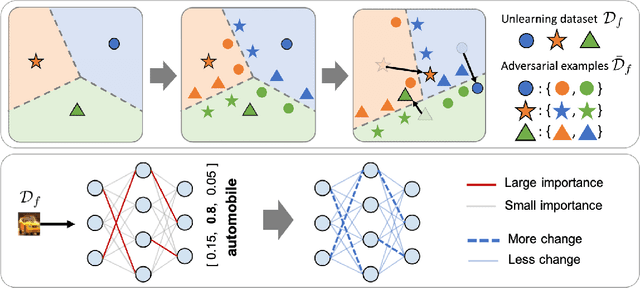
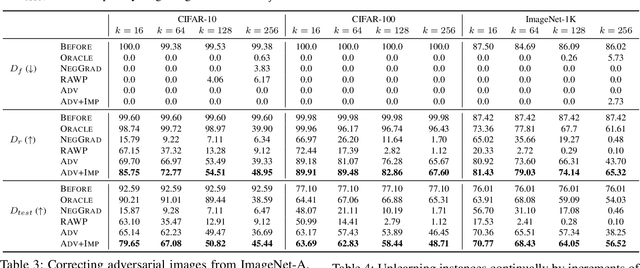
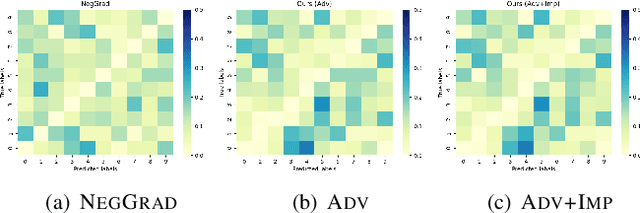
Since the recent advent of regulations for data protection (e.g., the General Data Protection Regulation), there has been increasing demand in deleting information learned from sensitive data in pre-trained models without retraining from scratch. The inherent vulnerability of neural networks towards adversarial attacks and unfairness also calls for a robust method to remove or correct information in an instance-wise fashion, while retaining the predictive performance across remaining data. To this end, we define instance-wise unlearning, of which the goal is to delete information on a set of instances from a pre-trained model, by either misclassifying each instance away from its original prediction or relabeling the instance to a different label. We also propose two methods that reduce forgetting on the remaining data: 1) utilizing adversarial examples to overcome forgetting at the representation-level and 2) leveraging weight importance metrics to pinpoint network parameters guilty of propagating unwanted information. Both methods only require the pre-trained model and data instances to forget, allowing painless application to real-life settings where the entire training set is unavailable. Through extensive experimentation on various image classification benchmarks, we show that our approach effectively preserves knowledge of remaining data while unlearning given instances in both single-task and continual unlearning scenarios.