 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulinaryCut-VLAP: A Vision-Language-Action-Physics Framework for Food Cutting via a Force-Aware Material Point Method
Jan 10, 2026Food cutting is a highly practical yet underexplored application at the intersection of vision and robotic manipulation. The task remains challenging because interactions between the knife and deformable materials are highly nonlinear and often entail large deformations, frequent contact, and topological change, which in turn hinder stable and safe large-scale data collection. To address these challenges, we propose a unified framework that couples a vision-language-action (VLA) dataset with a physically realistic cutting simulator built on the material point method (MPM). Our simulator adopts MLS-MPM as its computational core, reducing numerical dissipation and energy drift while preserving rotational and shear responses even under topology-changing cuts. During cutting, forces and stress distributions are estimated from impulse exchanges between particles and the grid, enabling stable tracking of transient contact forces and energy transfer. We also provide a benchmark dataset that integrates diverse cutting trajectories, multi-view visual observations, and fine-grained language instructions, together with force--torque and tool--pose labels to provide physically consistent training signals. These components realize a learning--evaluation loop that respects the core physics of cutting and establishes a safe, reproducible, and scalable foundation for advancing VLA models in deformable object manipulation.
Budgeted Online Continual Learning by Adaptive Layer Freezing and Frequency-based Sampling
Oct 19, 2024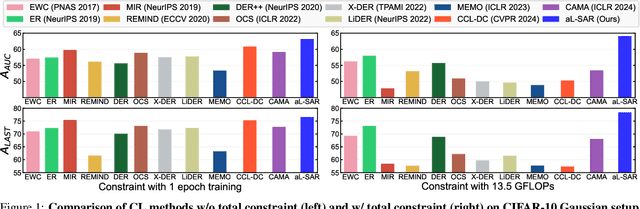
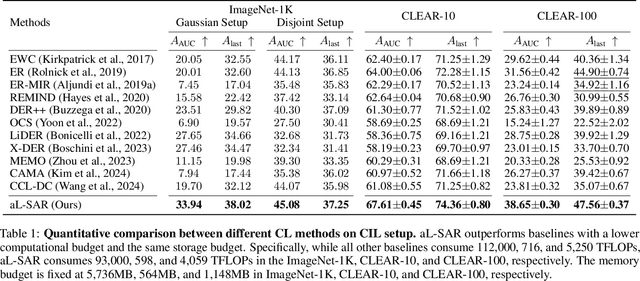
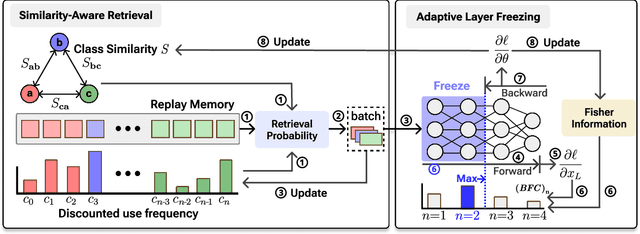
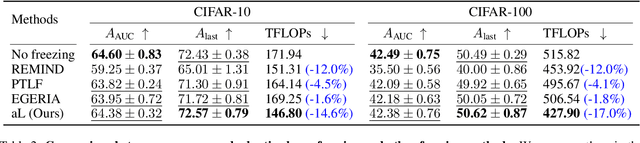
The majority of online continual learning (CL) advocates single-epoch training and imposes restrictions on the size of replay memory. However, single-epoch training would incur a different amount of computations per CL algorithm, and the additional storage cost to store logit or model in addition to replay memory is largely ignored in calculating the storage budget. Arguing different computational and storage budgets hinder fair comparison among CL algorithms in practice, we propose to use floating point operations (FLOPs) and total memory size in Byte as a metric for computational and memory budgets, respectively, to compare and develop CL algorithms in the same 'total resource budget.' To improve a CL method in a limited total budget, we propose adaptive layer freezing that does not update the layers for less informative batches to reduce computational costs with a negligible loss of accuracy. In addition, we propose a memory retrieval method that allows the model to learn the same amount of knowledge as using random retrieval in fewer iterations. Empirical validations on the CIFAR-10/100, CLEAR-10/100, and ImageNet-1K datasets demonstrate that the proposed approach outperforms the state-of-the-art methods within the same total budget
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.
Online Continual Learning on a Contaminated Data Stream with Blurry Task Boundaries
Mar 30, 2022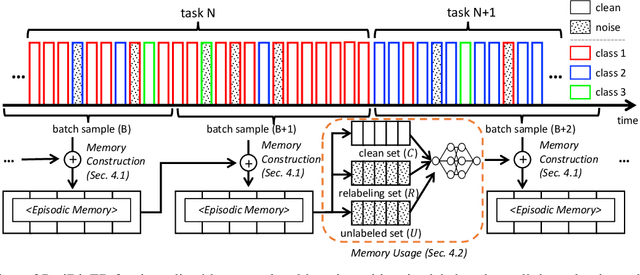
Learning under a continuously changing data distribution with incorrect labels is a desirable real-world problem yet challenging. A large body of continual learning (CL) methods, however, assumes data streams with clean labels, and online learning scenarios under noisy data streams are yet underexplored. We consider a more practical CL task setup of an online learning from blurry data stream with corrupted labels, where existing CL methods struggle. To address the task, we first argue the importance of both diversity and purity of examples in the episodic memory of continual learning models. To balance diversity and purity in the episodic memory, we propose a novel strategy to manage and use the memory by a unified approach of label noise aware diverse sampling and robust learning with semi-supervised learning. Our empirical validations on four real-world or synthetic noise datasets (CIFAR10 and 100, mini-WebVision, and Food-101N) exhibit that our method significantly outperforms prior arts in this realistic and challenging continual learning scenario. Code and data splits are available in https://github.com/clovaai/puridiver.
Online Continual Learning on Class Incremental Blurry Task Configuration with Anytime Inference
Oct 19, 2021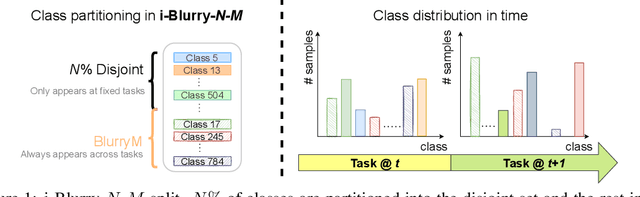
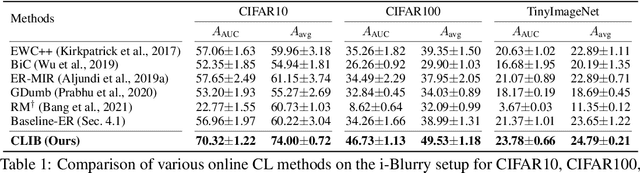
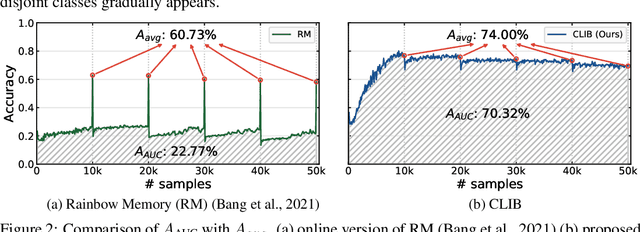

Despite rapid advances in continual learning, a large body of research is devoted to improving performance in the existing setups. While a handful of work do propose new continual learning setups, they still lack practicality in certain aspects. For better practicality, we first propose a novel continual learning setup that is online, task-free, class-incremental, of blurry task boundaries and subject to inference queries at any moment. We additionally propose a new metric to better measure the performance of the continual learning methods subject to inference queries at any moment. To address the challenging setup and evaluation protocol, we propose an effective method that employs a new memory management scheme and novel learning techniques. Our empirical validation demonstrates that the proposed method outperforms prior arts by large margins.