 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Apr 17, 2024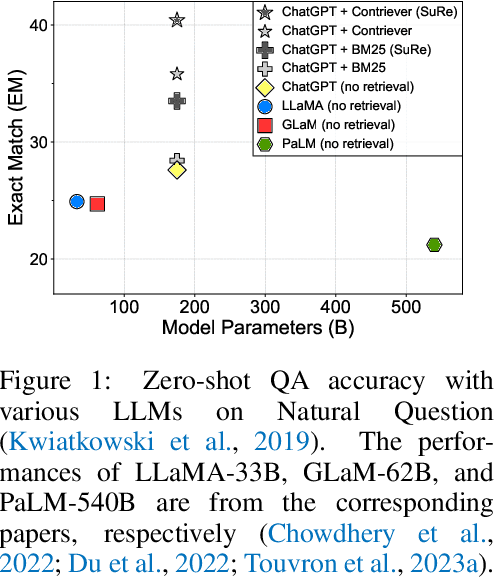
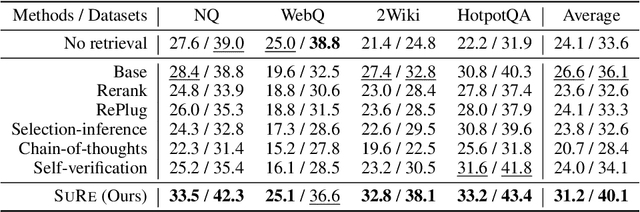

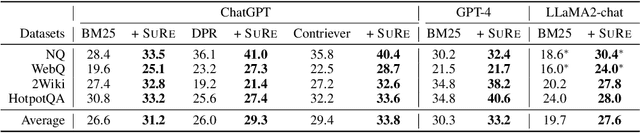
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Apr 16, 2024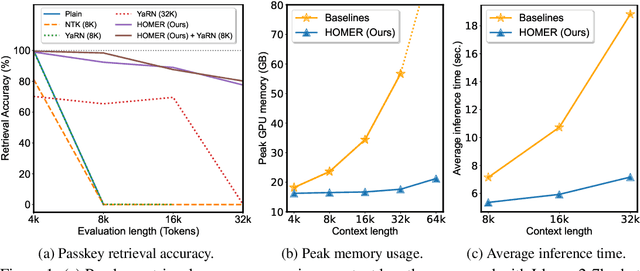
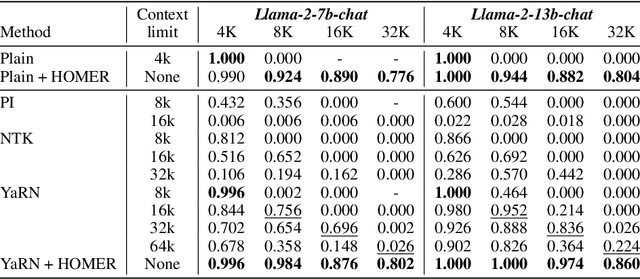
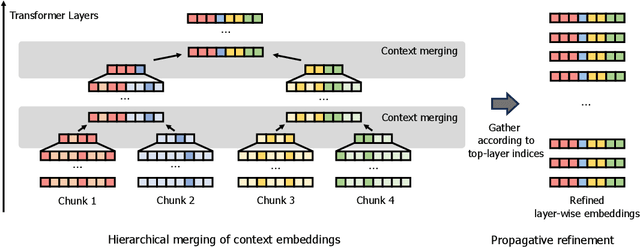
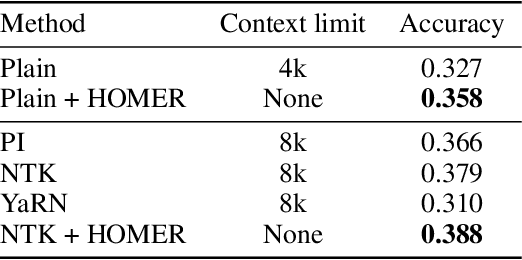
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Switching Temporary Teachers for Semi-Supervised Semantic Segmentation
Oct 28, 2023
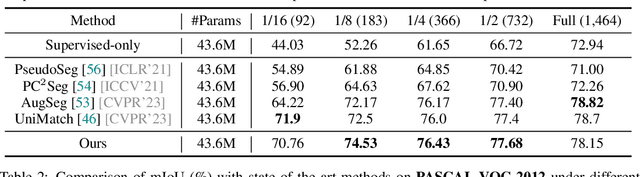


The teacher-student framework, prevalent in semi-supervised semantic segmentation, mainly employs the exponential moving average (EMA) to update a single teacher's weights based on the student's. However, EMA updates raise a problem in that the weights of the teacher and student are getting coupled, causing a potential performance bottleneck. Furthermore, this problem may become more severe when training with more complicated labels such as segmentation masks but with few annotated data. This paper introduces Dual Teacher, a simple yet effective approach that employs dual temporary teachers aiming to alleviate the coupling problem for the student. The temporary teachers work in shifts and are progressively improved, so consistently prevent the teacher and student from becoming excessively close. Specifically, the temporary teachers periodically take turns generating pseudo-labels to train a student model and maintain the distinct characteristics of the student model for each epoch. Consequently, Dual Teacher achieves competitive performance on the PASCAL VOC, Cityscapes, and ADE20K benchmarks with remarkably shorter training times than state-of-the-art methods. Moreover, we demonstrate that our approach is model-agnostic and compatible with both CNN- and Transformer-based models. Code is available at \url{https://github.com/naver-ai/dual-teacher}.
Dense Text-to-Image Generation with Attention Modulation
Aug 24, 2023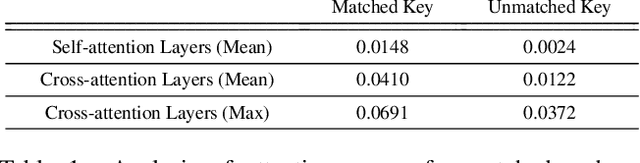



Existing text-to-image diffusion models struggle to synthesize realistic images given dense captions, where each text prompt provides a detailed description for a specific image region. To address this, we propose DenseDiffusion, a training-free method that adapts a pre-trained text-to-image model to handle such dense captions while offering control over the scene layout. We first analyze the relationship between generated images' layouts and the pre-trained model's intermediate attention maps. Next, we develop an attention modulation method that guides objects to appear in specific regions according to layout guidance. Without requiring additional fine-tuning or datasets, we improve image generation performance given dense captions regarding both automatic and human evaluation scores. In addition, we achieve similar-quality visual results with models specifically trained with layout conditions.
KoSBi: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Application
May 30, 2023



Large language models (LLMs) learn not only natural text generation abilities but also social biases against different demographic groups from real-world data. This poses a critical risk when deploying LLM-based applications. Existing research and resources are not readily applicable in South Korea due to the differences in language and culture, both of which significantly affect the biases and targeted demographic groups. This limitation requires localized social bias datasets to ensure the safe and effective deployment of LLMs. To this end, we present KO SB I, a new social bias dataset of 34k pairs of contexts and sentences in Korean covering 72 demographic groups in 15 categories. We find that through filtering-based moderation, social biases in generated content can be reduced by 16.47%p on average for HyperCLOVA (30B and 82B), and GPT-3.
SQuARe: A Large-Scale Dataset of Sensitive Questions and Acceptable Responses Created Through Human-Machine Collaboration
May 28, 2023



The potential social harms that large language models pose, such as generating offensive content and reinforcing biases, are steeply rising. Existing works focus on coping with this concern while interacting with ill-intentioned users, such as those who explicitly make hate speech or elicit harmful responses. However, discussions on sensitive issues can become toxic even if the users are well-intentioned. For safer models in such scenarios, we present the Sensitive Questions and Acceptable Response (SQuARe) dataset, a large-scale Korean dataset of 49k sensitive questions with 42k acceptable and 46k non-acceptable responses. The dataset was constructed leveraging HyperCLOVA in a human-in-the-loop manner based on real news headlines. Experiments show that acceptable response generation significantly improves for HyperCLOVA and GPT-3, demonstrating the efficacy of this dataset.
Query-Efficient Black-Box Red Teaming via Bayesian Optimization
May 27, 2023



The deployment of large-scale generative models is often restricted by their potential risk of causing harm to users in unpredictable ways. We focus on the problem of black-box red teaming, where a red team generates test cases and interacts with the victim model to discover a diverse set of failures with limited query access. Existing red teaming methods construct test cases based on human supervision or language model (LM) and query all test cases in a brute-force manner without incorporating any information from past evaluations, resulting in a prohibitively large number of queries. To this end, we propose Bayesian red teaming (BRT), novel query-efficient black-box red teaming methods based on Bayesian optimization, which iteratively identify diverse positive test cases leading to model failures by utilizing the pre-defined user input pool and the past evaluations. Experimental results on various user input pools demonstrate that our method consistently finds a significantly larger number of diverse positive test cases under the limited query budget than the baseline methods. The source code is available at https://github.com/snu-mllab/Bayesian-Red-Teaming.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.