 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Ask Me What You Need: Product Retrieval using Knowledge from GPT-3
Jul 06, 2022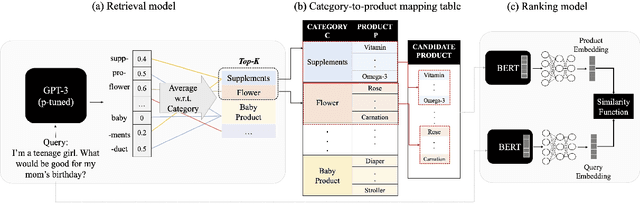
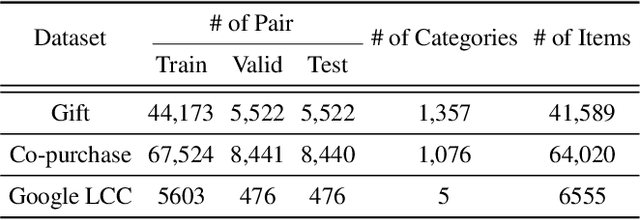
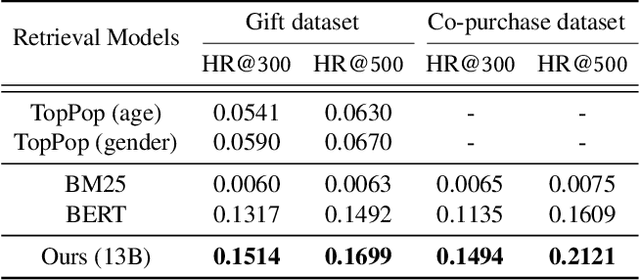
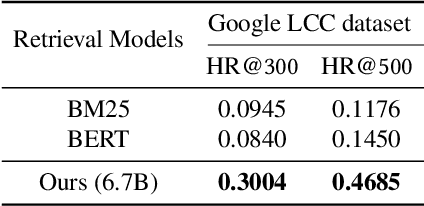
As online merchandise become more common, many studies focus on embedding-based methods where queries and products are represented in the semantic space. These methods alleviate the problem of vocab mismatch between the language of queries and products. However, past studies usually dealt with queries that precisely describe the product, and there still exists the need to answer imprecise queries that may require common sense knowledge, i.e., 'what should I get my mom for Mother's Day.' In this paper, we propose a GPT-3 based product retrieval system that leverages the knowledge-base (KB) of GPT-3 for question answering; users do not need to know the specific illustrative keywords for a product when querying. Our method tunes prompt tokens of GPT-3 to prompt knowledge and render answers that are mapped directly to products without further processing. Our method shows consistent performance improvement on two real-world and one public dataset, compared to the baseline methods. We provide an in-depth discussion on leveraging GPT-3 knowledge into a question answering based retrieval system.
Scaling Law for Recommendation Models: Towards General-purpose User Representations
Dec 01, 2021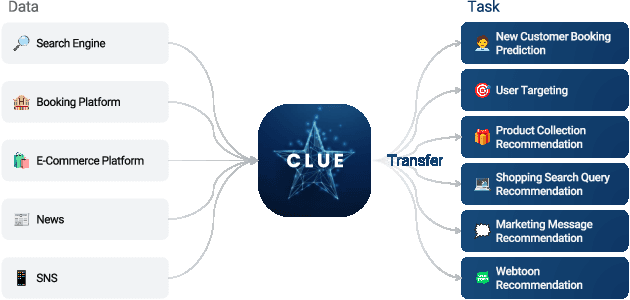
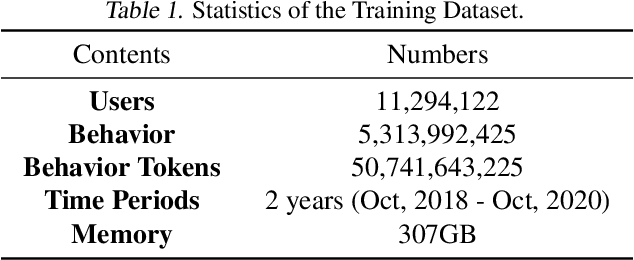
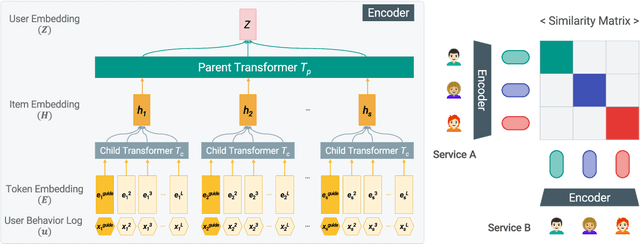

A recent trend shows that a general class of models, e.g., BERT, GPT-3, CLIP, trained on broad data at scale have shown a great variety of functionalities with a single learning architecture. In this work, we explore the possibility of general-purpose user representation learning by training a universal user encoder at large scales. We demonstrate that the scaling law holds in the user modeling areas, where the training error scales as a power-law with the amount of compute. Our Contrastive Learning User Encoder (CLUE), optimizes task-agnostic objectives, and the resulting user embeddings stretches our expectation of what is possible to do in various downstream tasks. CLUE also shows great transferability to other domains and systems, as performances on an online experiment shows significant improvements in online Click-Through-Rate (CTR). Furthermore, we also investigate how the performance changes according to the scale-up factors, i.e., model capacity, sequence length and batch size. Finally, we discuss the broader impacts of CLUE in general.
One4all User Representation for Recommender Systems in E-commerce
May 24, 2021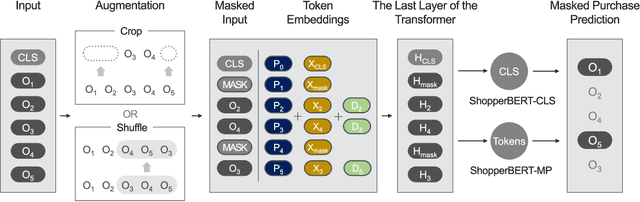

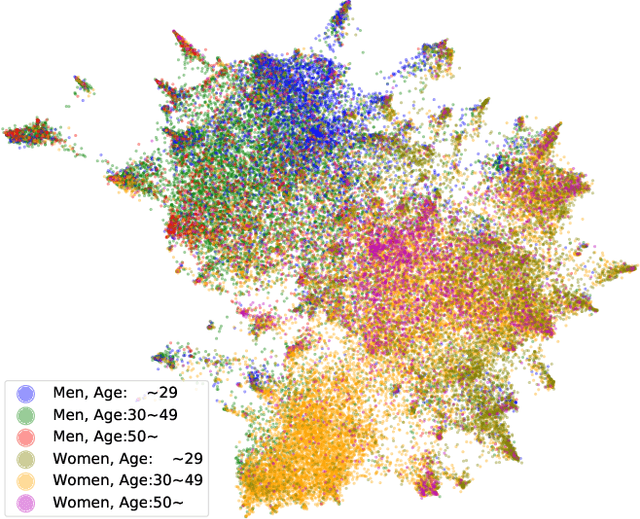
General-purpose representation learning through large-scale pre-training has shown promising results in the various machine learning fields. For an e-commerce domain, the objective of general-purpose, i.e., one for all, representations would be efficient applications for extensive downstream tasks such as user profiling, targeting, and recommendation tasks. In this paper, we systematically compare the generalizability of two learning strategies, i.e., transfer learning through the proposed model, ShopperBERT, vs. learning from scratch. ShopperBERT learns nine pretext tasks with 79.2M parameters from 0.8B user behaviors collected over two years to produce user embeddings. As a result, the MLPs that employ our embedding method outperform more complex models trained from scratch for five out of six tasks. Specifically, the pre-trained embeddings have superiority over the task-specific supervised features and the strong baselines, which learn the auxiliary dataset for the cold-start problem. We also show the computational efficiency and embedding visualization of the pre-trained features.
Multi-Manifold Learning for Large-scale Targeted Advertising System
Jul 08, 2020
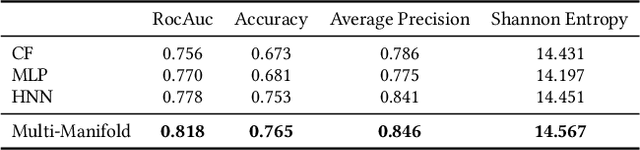
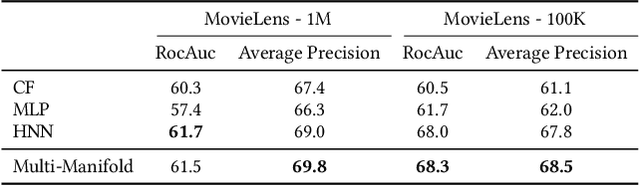
Messenger advertisements (ads) give direct and personal user experience yielding high conversion rates and sales. However, people are skeptical about ads and sometimes perceive them as spam, which eventually leads to a decrease in user satisfaction. Targeted advertising, which serves ads to individuals who may exhibit interest in a particular advertising message, is strongly required. The key to the success of precise user targeting lies in learning the accurate user and ad representation in the embedding space. Most of the previous studies have limited the representation learning in the Euclidean space, but recent studies have suggested hyperbolic manifold learning for the distinct projection of complex network properties emerging from real-world datasets such as social networks, recommender systems, and advertising. We propose a framework that can effectively learn the hierarchical structure in users and ads on the hyperbolic space, and extend to the Multi-Manifold Learning. Our method constructs multiple hyperbolic manifolds with learnable curvatures and maps the representation of user and ad to each manifold. The origin of each manifold is set as the centroid of each user cluster. The user preference for each ad is estimated using the distance between two entities in the hyperbolic space, and the final prediction is determined by aggregating the values calculated from the learned multiple manifolds. We evaluate our method on public benchmark datasets and a large-scale commercial messenger system LINE, and demonstrate its effectiveness through improved performance.
* Accepted at AdKDD 2020
Hop Sampling: A Simple Regularized Graph Learning for Non-Stationary Environments
Jun 26, 2020


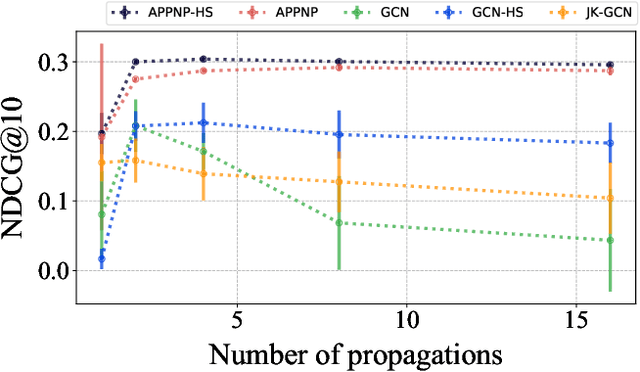
Graph representation learning is gaining popularity in a wide range of applications, such as social networks analysis, computational biology, and recommender systems. However, different with positive results from many academic studies, applying graph neural networks (GNNs) in a real-world application is still challenging due to non-stationary environments. The underlying distribution of streaming data changes unexpectedly, resulting in different graph structures (a.k.a., concept drift). Therefore, it is essential to devise a robust graph learning technique so that the model does not overfit to the training graphs. In this work, we present Hop Sampling, a straightforward regularization method that can effectively prevent GNNs from overfishing. The hop sampling randomly selects the number of propagation steps rather than fixing it, and by doing so, it encourages the model to learn meaningful node representation for all intermediate propagation layers and to experience a variety of plausible graphs that are not in the training set. Particularly, we describe the use case of our method in recommender systems, a representative example of the real-world non-stationary case. We evaluated hop sampling on a large-scale real-world LINE dataset and conducted an online A/B/n test in LINE Coupon recommender systems of LINE Wallet Tab. Experimental results demonstrate that the proposed scheme improves the prediction accuracy of GNNs. We observed hop sampling provides 7.97% and 16.93% improvements for NDCG and MAP compared to non-regularized GNN models in our online service. Furthermore, models using hop sampling alleviate the oversmoothing issue in GNNs enabling a deeper model as well as more diversified representation.
Graphs, Entities, and Step Mixture
May 18, 2020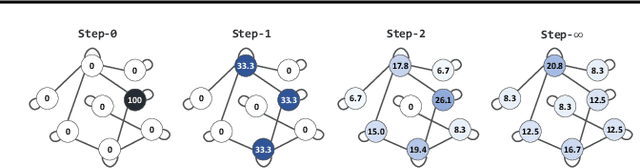
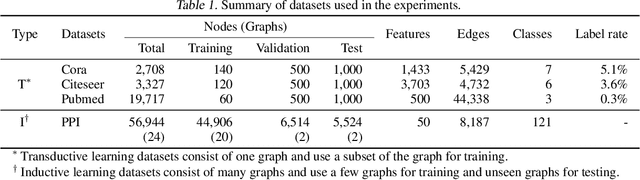
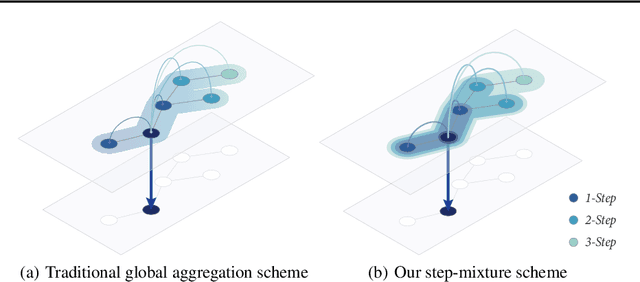
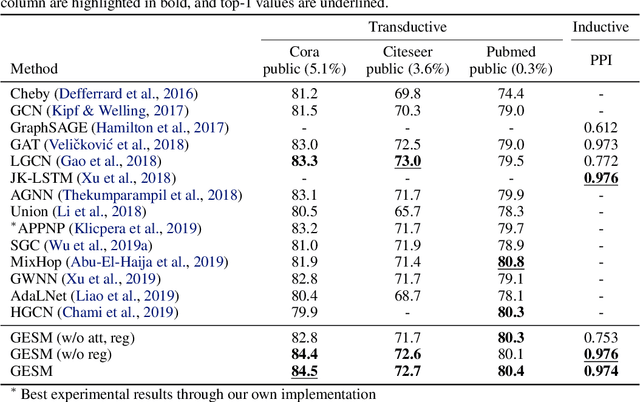
Existing approaches for graph neural networks commonly suffer from the oversmoothing issue, regardless of how neighborhoods are aggregated. Most methods also focus on transductive scenarios for fixed graphs, leading to poor generalization for unseen graphs. To address these issues, we propose a new graph neural network that considers both edge-based neighborhood relationships and node-based entity features, i.e. Graph Entities with Step Mixture via random walk (GESM). GESM employs a mixture of various steps through random walk to alleviate the oversmoothing problem, attention to dynamically reflect interrelations depending on node information, and structure-based regularization to enhance embedding representation. With intensive experiments, we show that the proposed GESM achieves state-of-the-art or comparable performances on eight benchmark graph datasets comprising transductive and inductive learning tasks. Furthermore, we empirically demonstrate the significance of considering global information.