 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
k-SALSA: k-anonymous synthetic averaging of retinal images via local style alignment
Mar 20, 2023The application of modern machine learning to retinal image analyses offers valuable insights into a broad range of human health conditions beyond ophthalmic diseases. Additionally, data sharing is key to fully realizing the potential of machine learning models by providing a rich and diverse collection of training data. However, the personally-identifying nature of retinal images, encompassing the unique vascular structure of each individual, often prevents this data from being shared openly. While prior works have explored image de-identification strategies based on synthetic averaging of images in other domains (e.g. facial images), existing techniques face difficulty in preserving both privacy and clinical utility in retinal images, as we demonstrate in our work. We therefore introduce k-SALSA, a generative adversarial network (GAN)-based framework for synthesizing retinal fundus images that summarize a given private dataset while satisfying the privacy notion of k-anonymity. k-SALSA brings together state-of-the-art techniques for training and inverting GANs to achieve practical performance on retinal images. Furthermore, k-SALSA leverages a new technique, called local style alignment, to generate a synthetic average that maximizes the retention of fine-grain visual patterns in the source images, thus improving the clinical utility of the generated images. On two benchmark datasets of diabetic retinopathy (EyePACS and APTOS), we demonstrate our improvement upon existing methods with respect to image fidelity, classification performance, and mitigation of membership inference attacks. Our work represents a step toward broader sharing of retinal images for scientific collaboration. Code is available at https://github.com/hcholab/k-salsa.
Relation-aware Language-Graph Transformer for Question Answering
Dec 02, 2022



Question Answering (QA) is a task that entails reasoning over natural language contexts, and many relevant works augment language models (LMs) with graph neural networks (GNNs) to encode the Knowledge Graph (KG) information. However, most existing GNN-based modules for QA do not take advantage of rich relational information of KGs and depend on limited information interaction between the LM and the KG. To address these issues, we propose Question Answering Transformer (QAT), which is designed to jointly reason over language and graphs with respect to entity relations in a unified manner. Specifically, QAT constructs Meta-Path tokens, which learn relation-centric embeddings based on diverse structural and semantic relations. Then, our Relation-Aware Self-Attention module comprehensively integrates different modalities via the Cross-Modal Relative Position Bias, which guides information exchange between relevant entities of different modalities. We validate the effectiveness of QAT on commonsense question answering datasets like CommonsenseQA and OpenBookQA, and on a medical question answering dataset, MedQA-USMLE. On all the datasets, our method achieves state-of-the-art performance. Our code is available at http://github.com/mlvlab/QAT.
Ask Me What You Need: Product Retrieval using Knowledge from GPT-3
Jul 06, 2022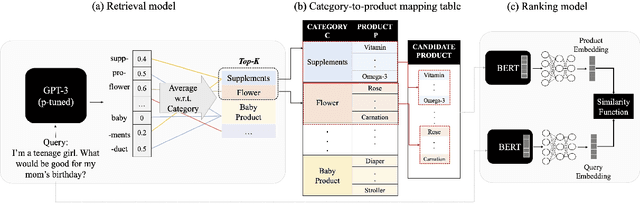
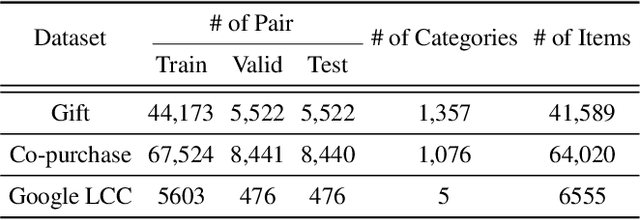
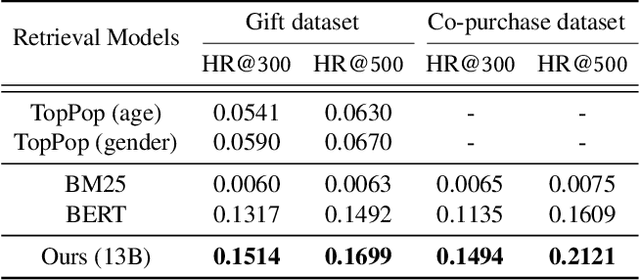
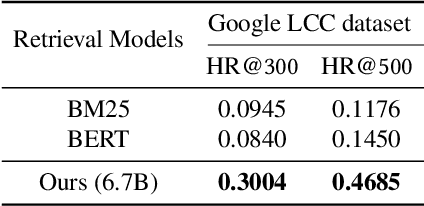
As online merchandise become more common, many studies focus on embedding-based methods where queries and products are represented in the semantic space. These methods alleviate the problem of vocab mismatch between the language of queries and products. However, past studies usually dealt with queries that precisely describe the product, and there still exists the need to answer imprecise queries that may require common sense knowledge, i.e., 'what should I get my mom for Mother's Day.' In this paper, we propose a GPT-3 based product retrieval system that leverages the knowledge-base (KB) of GPT-3 for question answering; users do not need to know the specific illustrative keywords for a product when querying. Our method tunes prompt tokens of GPT-3 to prompt knowledge and render answers that are mapped directly to products without further processing. Our method shows consistent performance improvement on two real-world and one public dataset, compared to the baseline methods. We provide an in-depth discussion on leveraging GPT-3 knowledge into a question answering based retrieval system.
Deformable Graph Transformer
Jun 29, 2022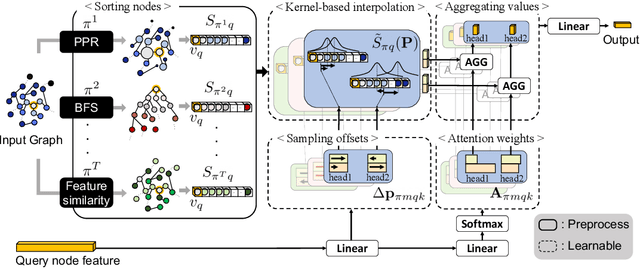
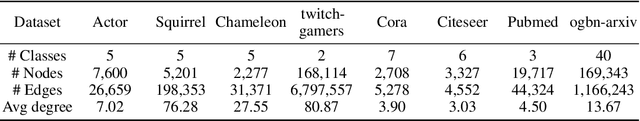
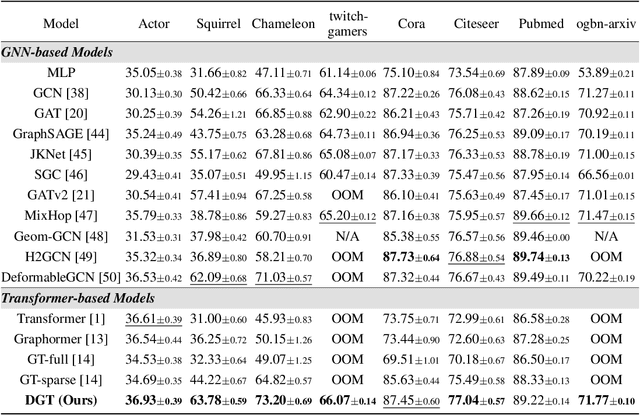
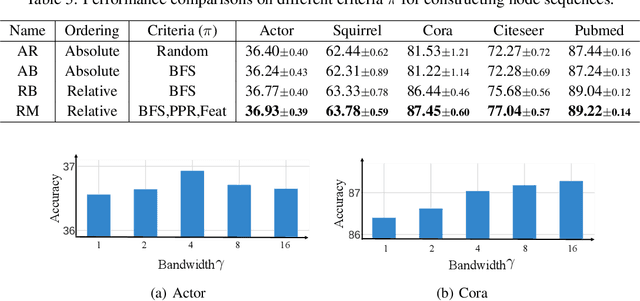
Transformer-based models have been widely used and achieved state-of-the-art performance in various domains such as natural language processing and computer vision. Recent works show that Transformers can also be generalized to graph-structured data. However, the success is limited to small-scale graphs due to technical challenges such as the quadratic complexity in regards to the number of nodes and non-local aggregation that often leads to inferior generalization performance to conventional graph neural networks. In this paper, to address these issues, we propose Deformable Graph Transformer (DGT) that performs sparse attention with dynamically sampled key and value pairs. Specifically, our framework first constructs multiple node sequences with various criteria to consider both structural and semantic proximity. Then, the sparse attention is applied to the node sequences for learning node representations with a reduced computational cost. We also design simple and effective positional encodings to capture structural similarity and distance between nodes. Experiments demonstrate that our novel graph Transformer consistently outperforms existing Transformer-based models and shows competitive performance compared to state-of-the-art models on 8 graph benchmark datasets including large-scale graphs.
Metropolis-Hastings Data Augmentation for Graph Neural Networks
Mar 26, 2022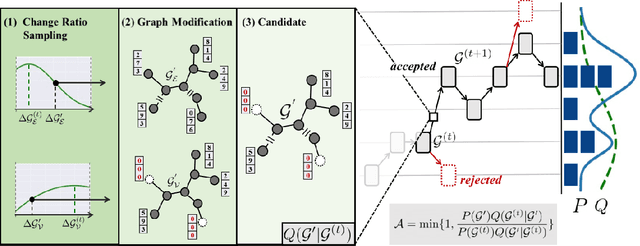
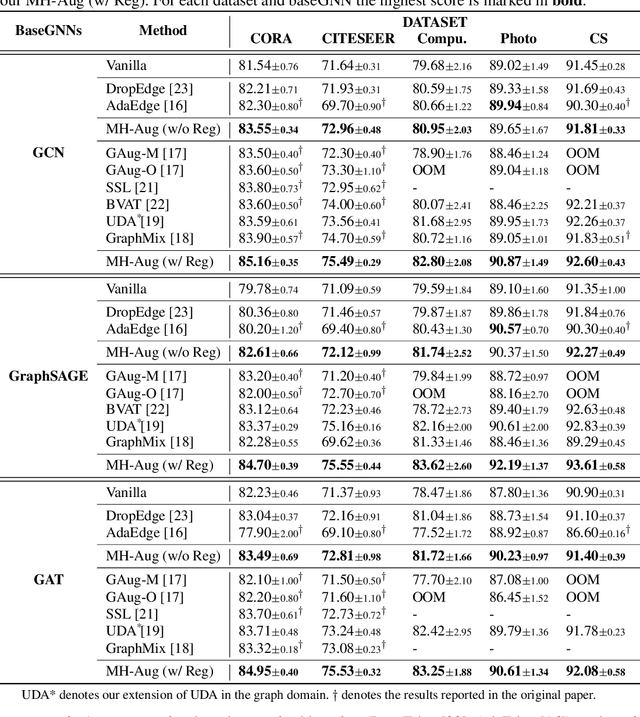
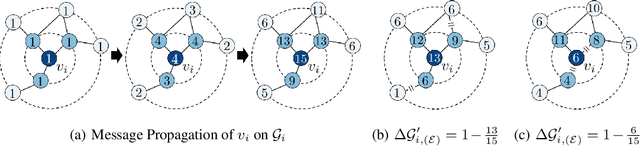
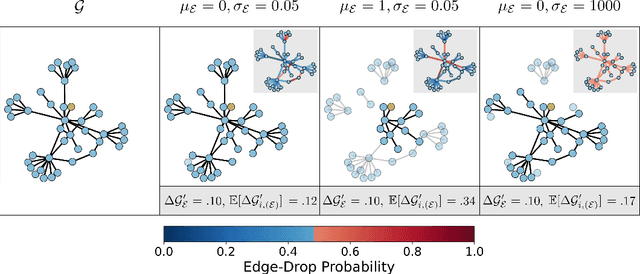
Graph Neural Networks (GNNs) often suffer from weak-generalization due to sparsely labeled data despite their promising results on various graph-based tasks. Data augmentation is a prevalent remedy to improve the generalization ability of models in many domains. However, due to the non-Euclidean nature of data space and the dependencies between samples, designing effective augmentation on graphs is challenging. In this paper, we propose a novel framework Metropolis-Hastings Data Augmentation (MH-Aug) that draws augmented graphs from an explicit target distribution for semi-supervised learning. MH-Aug produces a sequence of augmented graphs from the target distribution enables flexible control of the strength and diversity of augmentation. Since the direct sampling from the complex target distribution is challenging, we adopt the Metropolis-Hastings algorithm to obtain the augmented samples. We also propose a simple and effective semi-supervised learning strategy with generated samples from MH-Aug. Our extensive experiments demonstrate that MH-Aug can generate a sequence of samples according to the target distribution to significantly improve the performance of GNNs.