 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegFormer: Transferable Relational Grounding for Efficient Weakly-Supervised Human-Object Interaction Detection
Apr 01, 2026Weakly-supervised Human-Object Interaction (HOI) detection is essential for scalable scene understanding, as it learns interactions from only image-level annotations. Due to the lack of localization signals, prior works typically rely on an external object detector to generate candidate pairs and then infer their interactions through pairwise reasoning. However, this framework often struggles to scale due to the substantial computational cost incurred by enumerating numerous instance pairs. In addition, it suffers from false positives arising from non-interactive combinations, which hinder accurate instance-level HOI reasoning. To address these issues, we introduce Relational Grounding Transformer (RegFormer), a versatile interaction recognition module for efficient and accurate HOI reasoning. Under image-level supervision, RegFormer leverages spatially grounded signals as guidance for the reasoning process and promotes locality-aware interaction learning. By learning localized interaction cues, our module distinguishes humans, objects, and their interactions, enabling direct transfer from image-level interaction reasoning to precise and efficient instance-level reasoning without additional training. Our extensive experiments and analyses demonstrate that RegFormer effectively learns spatial cues for instance-level interaction reasoning, operates with high efficiency, and even achieves performance comparable to fully supervised models. Our code is available at https://github.com/mlvlab/RegFormer.
MoE-GRPO: Optimizing Mixture-of-Experts via Reinforcement Learning in Vision-Language Models
Mar 26, 2026Mixture-of-Experts (MoE) has emerged as an effective approach to reduce the computational overhead of Transformer architectures by sparsely activating a subset of parameters for each token while preserving high model capacity. This paradigm has recently been extended to Vision-Language Models (VLMs), enabling scalable multi-modal understanding with reduced computational cost. However, the widely adopted deterministic top-K routing mechanism may overlook more optimal expert combinations and lead to expert overfitting. To address this limitation and improve the diversity of expert selection, we propose MoE-GRPO, a reinforcement learning (RL)-based framework for optimizing expert routing in MoE-based VLMs. Specifically, we formulate expert selection as a sequential decision-making problem and optimize it using Group Relative Policy Optimization (GRPO), allowing the model to learn adaptive expert routing policies through exploration and reward-based feedback. Furthermore, we introduce a modality-aware router guidance that enhances training stability and efficiency by discouraging the router from exploring experts that are infrequently activated for a given modality. Extensive experiments on multi-modal image and video benchmarks show that MoE-GRPO consistently outperforms standard top-K routing and its variants by promoting more diverse expert selection, thereby mitigating expert overfitting and enabling a task-level expert specialization.
F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
Mar 22, 2026Feed-forward 3D Gaussian Splatting methods enable single-pass reconstruction and real-time rendering. However, they typically adopt rigid pixel-to-Gaussian or voxel-to-Gaussian pipelines that uniformly allocate Gaussians, leading to redundant Gaussians across views. Moreover, they lack an effective mechanism to control the total number of Gaussians while maintaining reconstruction fidelity. To address these limitations, we present F4Splat, which performs Feed-Forward predictive densification for Feed-Forward 3D Gaussian Splatting, introducing a densification-score-guided allocation strategy that adaptively distributes Gaussians according to spatial complexity and multi-view overlap. Our model predicts per-region densification scores to estimate the required Gaussian density and allows explicit control over the final Gaussian budget without retraining. This spatially adaptive allocation reduces redundancy in simple regions and minimizes duplicate Gaussians across overlapping views, producing compact yet high-quality 3D representations. Extensive experiments demonstrate that our model achieves superior novel-view synthesis performance compared to prior uncalibrated feed-forward methods, while using significantly fewer Gaussians.
Error as Signal: Stiffness-Aware Diffusion Sampling via Embedded Runge-Kutta Guidance
Mar 04, 2026Classifier-Free Guidance (CFG) has established the foundation for guidance mechanisms in diffusion models, showing that well-designed guidance proxies significantly improve conditional generation and sample quality. Autoguidance (AG) has extended this idea, but it relies on an auxiliary network and leaves solver-induced errors unaddressed. In stiff regions, the ODE trajectory changes sharply, where local truncation error (LTE) becomes a critical factor that deteriorates sample quality. Our key observation is that these errors align with the dominant eigenvector, motivating us to leverage the solver-induced error as a guidance signal. We propose Embedded Runge-Kutta Guidance (ERK-Guid), which exploits detected stiffness to reduce LTE and stabilize sampling. We theoretically and empirically analyze stiffness and eigenvector estimators with solver errors to motivate the design of ERK-Guid. Our experiments on both synthetic datasets and the popular benchmark dataset, ImageNet, demonstrate that ERK-Guid consistently outperforms state-of-the-art methods. Code is available at https://github.com/mlvlab/ERK-Guid.
ProGraph-R1: Progress-aware Reinforcement Learning for Graph Retrieval Augmented Generation
Jan 25, 2026Graph Retrieval-Augmented Generation (GraphRAG) has been successfully applied in various knowledge-intensive question answering tasks by organizing external knowledge into structured graphs of entities and relations. It enables large language models (LLMs) to perform complex reasoning beyond text-chunk retrieval. Recent works have employed reinforcement learning (RL) to train agentic GraphRAG frameworks that perform iterative interactions between LLMs and knowledge graphs. However, existing RL-based frameworks such as Graph-R1 suffer from two key limitations: (1) they primarily depend on semantic similarity for retrieval, often overlooking the underlying graph structure, and (2) they rely on sparse, outcome-level rewards, failing to capture the quality of intermediate retrieval steps and their dependencies. To address these limitations, we propose ProGraph-R1, a progress-aware agentic framework for graph-based retrieval and multi-step reasoning. ProGraph-R1 introduces a structure-aware hypergraph retrieval mechanism that jointly considers semantic relevance and graph connectivity, encouraging coherent traversal along multi-hop reasoning paths. We also design a progress-based step-wise policy optimization, which provides dense learning signals by modulating advantages according to intermediate reasoning progress within a graph, rather than relying solely on final outcomes. Experiments on multi-hop question answering benchmarks demonstrate that ProGraph-R1 consistently improves reasoning accuracy and generation quality over existing GraphRAG methods.
Improving Large Molecular Language Model via Relation-aware Multimodal Collaboration
Jan 18, 2026Large language models (LLMs) have demonstrated their instruction-following capabilities and achieved powerful performance on various tasks. Inspired by their success, recent works in the molecular domain have led to the development of large molecular language models (LMLMs) that integrate 1D molecular strings or 2D molecular graphs into the language models. However, existing LMLMs often suffer from hallucination and limited robustness, largely due to inadequate integration of diverse molecular modalities such as 1D sequences, 2D molecular graphs, and 3D conformations. To address these limitations, we propose CoLLaMo, a large language model-based molecular assistant equipped with a multi-level molecular modality-collaborative projector. The relation-aware modality-collaborative attention mechanism in the projector facilitates fine-grained and relation-guided information exchange between atoms by incorporating 2D structural and 3D spatial relations. Furthermore, we present a molecule-centric new automatic measurement, including a hallucination assessment metric and GPT-based caption quality evaluation to address the limitations of token-based generic evaluation metrics (i.e., BLEU) widely used in assessing molecular comprehension of LMLMs. Our extensive experiments demonstrate that our CoLLaMo enhances the molecular modality generalization capabilities of LMLMs, achieving the best performance on multiple tasks, including molecule captioning, computed property QA, descriptive property QA, motif counting, and IUPAC name prediction.
TabFlash: Efficient Table Understanding with Progressive Question Conditioning and Token Focusing
Nov 17, 2025Table images present unique challenges for effective and efficient understanding due to the need for question-specific focus and the presence of redundant background regions. Existing Multimodal Large Language Model (MLLM) approaches often overlook these characteristics, resulting in uninformative and redundant visual representations. To address these issues, we aim to generate visual features that are both informative and compact to improve table understanding. We first propose progressive question conditioning, which injects the question into Vision Transformer layers with gradually increasing frequency, considering each layer's capacity to handle additional information, to generate question-aware visual features. To reduce redundancy, we introduce a pruning strategy that discards background tokens, thereby improving efficiency. To mitigate information loss from pruning, we further propose token focusing, a training strategy that encourages the model to concentrate essential information in the retained tokens. By combining these approaches, we present TabFlash, an efficient and effective MLLM for table understanding. TabFlash achieves state-of-the-art performance, outperforming both open-source and proprietary MLLMs, while requiring 27% less FLOPs and 30% less memory usage compared to the second-best MLLM.
Transferable Model-agnostic Vision-Language Model Adaptation for Efficient Weak-to-Strong Generalization
Aug 13, 2025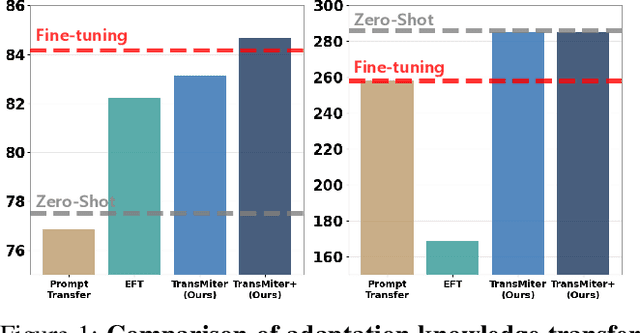
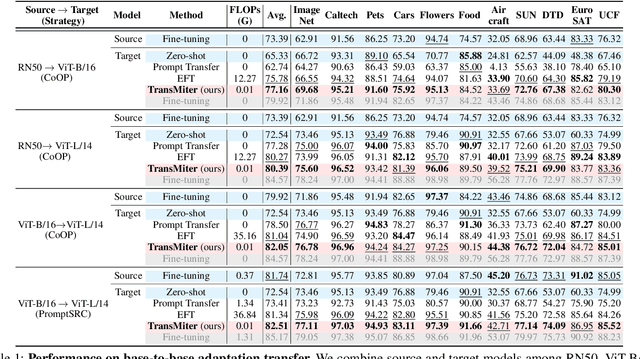
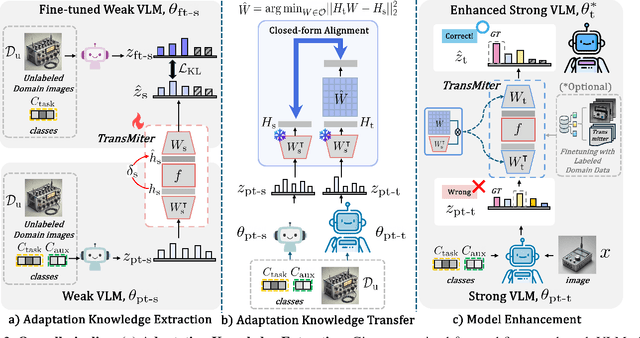
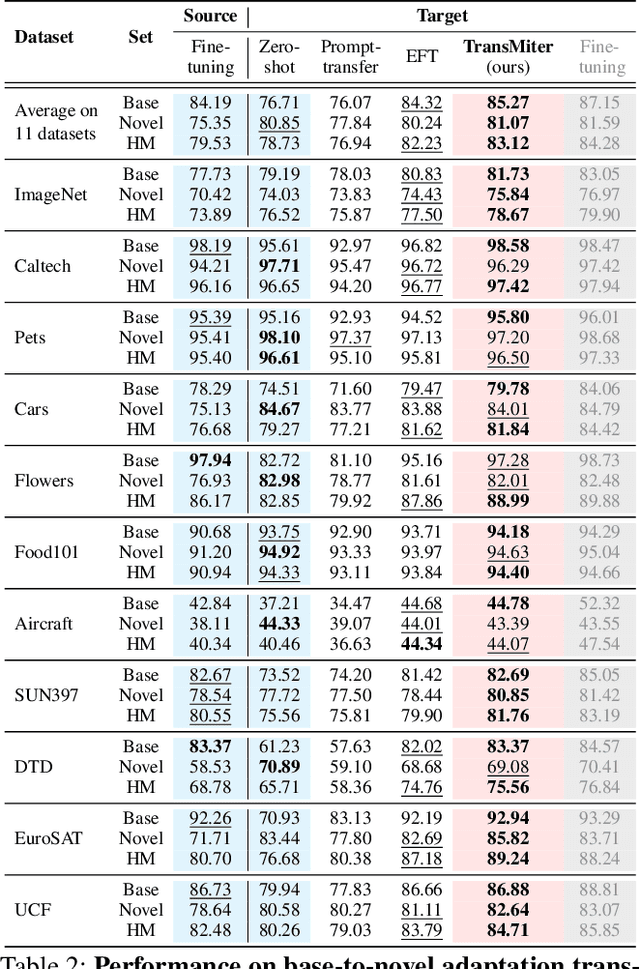
Vision-Language Models (VLMs) have been widely used in various visual recognition tasks due to their remarkable generalization capabilities. As these models grow in size and complexity, fine-tuning becomes costly, emphasizing the need to reuse adaptation knowledge from 'weaker' models to efficiently enhance 'stronger' ones. However, existing adaptation transfer methods exhibit limited transferability across models due to their model-specific design and high computational demands. To tackle this, we propose Transferable Model-agnostic adapter (TransMiter), a light-weight adapter that improves vision-language models 'without backpropagation'. TransMiter captures the knowledge gap between pre-trained and fine-tuned VLMs, in an 'unsupervised' manner. Once trained, this knowledge can be seamlessly transferred across different models without the need for backpropagation. Moreover, TransMiter consists of only a few layers, inducing a negligible additional inference cost. Notably, supplementing the process with a few labeled data further yields additional performance gain, often surpassing a fine-tuned stronger model, with a marginal training cost. Experimental results and analyses demonstrate that TransMiter effectively and efficiently transfers adaptation knowledge while preserving generalization abilities across VLMs of different sizes and architectures in visual recognition tasks.
When Model Knowledge meets Diffusion Model: Diffusion-assisted Data-free Image Synthesis with Alignment of Domain and Class
Jun 18, 2025Open-source pre-trained models hold great potential for diverse applications, but their utility declines when their training data is unavailable. Data-Free Image Synthesis (DFIS) aims to generate images that approximate the learned data distribution of a pre-trained model without accessing the original data. However, existing DFIS meth ods produce samples that deviate from the training data distribution due to the lack of prior knowl edge about natural images. To overcome this limitation, we propose DDIS, the first Diffusion-assisted Data-free Image Synthesis method that leverages a text-to-image diffusion model as a powerful image prior, improving synthetic image quality. DDIS extracts knowledge about the learned distribution from the given model and uses it to guide the diffusion model, enabling the generation of images that accurately align with the training data distribution. To achieve this, we introduce Domain Alignment Guidance (DAG) that aligns the synthetic data domain with the training data domain during the diffusion sampling process. Furthermore, we optimize a single Class Alignment Token (CAT) embedding to effectively capture class-specific attributes in the training dataset. Experiments on PACS and Ima geNet demonstrate that DDIS outperforms prior DFIS methods by generating samples that better reflect the training data distribution, achieving SOTA performance in data-free applications.
Efficient multi-view training for 3D Gaussian Splatting
Jun 15, 20253D Gaussian Splatting (3DGS) has emerged as a preferred choice alongside Neural Radiance Fields (NeRF) in inverse rendering due to its superior rendering speed. Currently, the common approach in 3DGS is to utilize "single-view" mini-batch training, where only one image is processed per iteration, in contrast to NeRF's "multi-view" mini-batch training, which leverages multiple images. We observe that such single-view training can lead to suboptimal optimization due to increased variance in mini-batch stochastic gradients, highlighting the necessity for multi-view training. However, implementing multi-view training in 3DGS poses challenges. Simply rendering multiple images per iteration incurs considerable overhead and may result in suboptimal Gaussian densification due to its reliance on single-view assumptions. To address these issues, we modify the rasterization process to minimize the overhead associated with multi-view training and propose a 3D distance-aware D-SSIM loss and multi-view adaptive density control that better suits multi-view scenarios. Our experiments demonstrate that the proposed methods significantly enhance the performance of 3DGS and its variants, freeing 3DGS from the constraints of single-view training.