 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient multi-view training for 3D Gaussian Splatting
Jun 15, 20253D Gaussian Splatting (3DGS) has emerged as a preferred choice alongside Neural Radiance Fields (NeRF) in inverse rendering due to its superior rendering speed. Currently, the common approach in 3DGS is to utilize "single-view" mini-batch training, where only one image is processed per iteration, in contrast to NeRF's "multi-view" mini-batch training, which leverages multiple images. We observe that such single-view training can lead to suboptimal optimization due to increased variance in mini-batch stochastic gradients, highlighting the necessity for multi-view training. However, implementing multi-view training in 3DGS poses challenges. Simply rendering multiple images per iteration incurs considerable overhead and may result in suboptimal Gaussian densification due to its reliance on single-view assumptions. To address these issues, we modify the rasterization process to minimize the overhead associated with multi-view training and propose a 3D distance-aware D-SSIM loss and multi-view adaptive density control that better suits multi-view scenarios. Our experiments demonstrate that the proposed methods significantly enhance the performance of 3DGS and its variants, freeing 3DGS from the constraints of single-view training.
vid-TLDR: Training Free Token merging for Light-weight Video Transformer
Mar 30, 2024



Video Transformers have become the prevalent solution for various video downstream tasks with superior expressive power and flexibility. However, these video transformers suffer from heavy computational costs induced by the massive number of tokens across the entire video frames, which has been the major barrier to training the model. Further, the patches irrelevant to the main contents, e.g., backgrounds, degrade the generalization performance of models. To tackle these issues, we propose training free token merging for lightweight video Transformer (vid-TLDR) that aims to enhance the efficiency of video Transformers by merging the background tokens without additional training. For vid-TLDR, we introduce a novel approach to capture the salient regions in videos only with the attention map. Further, we introduce the saliency-aware token merging strategy by dropping the background tokens and sharpening the object scores. Our experiments show that vid-TLDR significantly mitigates the computational complexity of video Transformers while achieving competitive performance compared to the base model without vid-TLDR. Code is available at https://github.com/mlvlab/vid-TLDR.
UP-NeRF: Unconstrained Pose-Prior-Free Neural Radiance Fields
Nov 08, 2023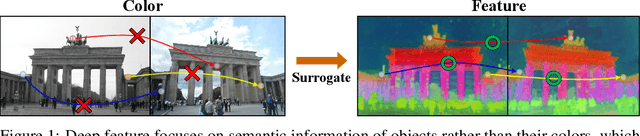
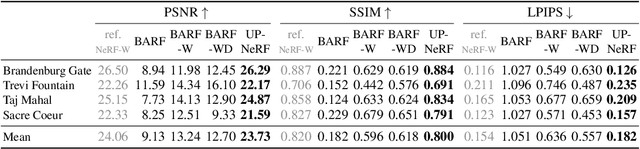
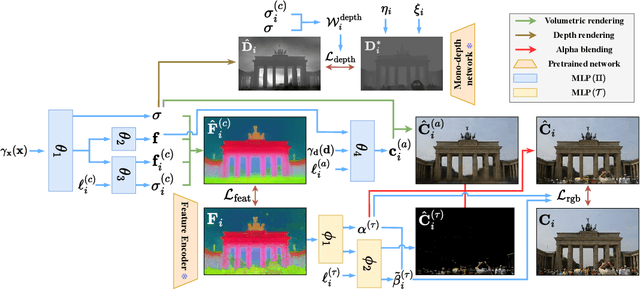
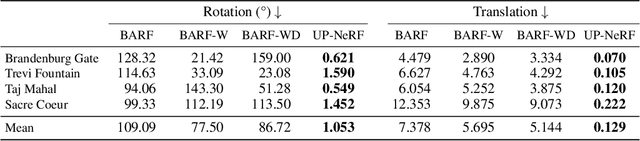
Neural Radiance Field (NeRF) has enabled novel view synthesis with high fidelity given images and camera poses. Subsequent works even succeeded in eliminating the necessity of pose priors by jointly optimizing NeRF and camera pose. However, these works are limited to relatively simple settings such as photometrically consistent and occluder-free image collections or a sequence of images from a video. So they have difficulty handling unconstrained images with varying illumination and transient occluders. In this paper, we propose $\textbf{UP-NeRF}$ ($\textbf{U}$nconstrained $\textbf{P}$ose-prior-free $\textbf{Ne}$ural $\textbf{R}$adiance $\textbf{F}$ields) to optimize NeRF with unconstrained image collections without camera pose prior. We tackle these challenges with surrogate tasks that optimize color-insensitive feature fields and a separate module for transient occluders to block their influence on pose estimation. In addition, we introduce a candidate head to enable more robust pose estimation and transient-aware depth supervision to minimize the effect of incorrect prior. Our experiments verify the superior performance of our method compared to the baselines including BARF and its variants in a challenging internet photo collection, $\textit{Phototourism}$ dataset.