 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
Mar 22, 2026Feed-forward 3D Gaussian Splatting methods enable single-pass reconstruction and real-time rendering. However, they typically adopt rigid pixel-to-Gaussian or voxel-to-Gaussian pipelines that uniformly allocate Gaussians, leading to redundant Gaussians across views. Moreover, they lack an effective mechanism to control the total number of Gaussians while maintaining reconstruction fidelity. To address these limitations, we present F4Splat, which performs Feed-Forward predictive densification for Feed-Forward 3D Gaussian Splatting, introducing a densification-score-guided allocation strategy that adaptively distributes Gaussians according to spatial complexity and multi-view overlap. Our model predicts per-region densification scores to estimate the required Gaussian density and allows explicit control over the final Gaussian budget without retraining. This spatially adaptive allocation reduces redundancy in simple regions and minimizes duplicate Gaussians across overlapping views, producing compact yet high-quality 3D representations. Extensive experiments demonstrate that our model achieves superior novel-view synthesis performance compared to prior uncalibrated feed-forward methods, while using significantly fewer Gaussians.
Efficient multi-view training for 3D Gaussian Splatting
Jun 15, 20253D Gaussian Splatting (3DGS) has emerged as a preferred choice alongside Neural Radiance Fields (NeRF) in inverse rendering due to its superior rendering speed. Currently, the common approach in 3DGS is to utilize "single-view" mini-batch training, where only one image is processed per iteration, in contrast to NeRF's "multi-view" mini-batch training, which leverages multiple images. We observe that such single-view training can lead to suboptimal optimization due to increased variance in mini-batch stochastic gradients, highlighting the necessity for multi-view training. However, implementing multi-view training in 3DGS poses challenges. Simply rendering multiple images per iteration incurs considerable overhead and may result in suboptimal Gaussian densification due to its reliance on single-view assumptions. To address these issues, we modify the rasterization process to minimize the overhead associated with multi-view training and propose a 3D distance-aware D-SSIM loss and multi-view adaptive density control that better suits multi-view scenarios. Our experiments demonstrate that the proposed methods significantly enhance the performance of 3DGS and its variants, freeing 3DGS from the constraints of single-view training.
Robust Multimodal 3D Object Detection via Modality-Agnostic Decoding and Proximity-based Modality Ensemble
Jul 27, 2024



Recent advancements in 3D object detection have benefited from multi-modal information from the multi-view cameras and LiDAR sensors. However, the inherent disparities between the modalities pose substantial challenges. We observe that existing multi-modal 3D object detection methods heavily rely on the LiDAR sensor, treating the camera as an auxiliary modality for augmenting semantic details. This often leads to not only underutilization of camera data but also significant performance degradation in scenarios where LiDAR data is unavailable. Additionally, existing fusion methods overlook the detrimental impact of sensor noise induced by environmental changes, on detection performance. In this paper, we propose MEFormer to address the LiDAR over-reliance problem by harnessing critical information for 3D object detection from every available modality while concurrently safeguarding against corrupted signals during the fusion process. Specifically, we introduce Modality Agnostic Decoding (MOAD) that extracts geometric and semantic features with a shared transformer decoder regardless of input modalities and provides promising improvement with a single modality as well as multi-modality. Additionally, our Proximity-based Modality Ensemble (PME) module adaptively utilizes the strengths of each modality depending on the environment while mitigating the effects of a noisy sensor. Our MEFormer achieves state-of-the-art performance of 73.9% NDS and 71.5% mAP in the nuScenes validation set. Extensive analyses validate that our MEFormer improves robustness against challenging conditions such as sensor malfunctions or environmental changes. The source code is available at https://github.com/hanchaa/MEFormer
UP-NeRF: Unconstrained Pose-Prior-Free Neural Radiance Fields
Nov 08, 2023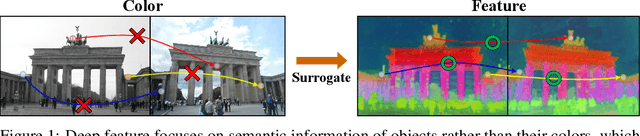
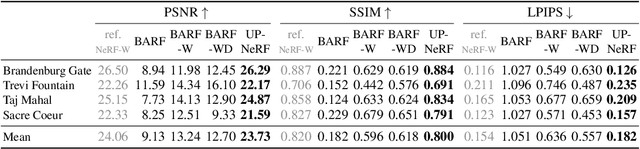
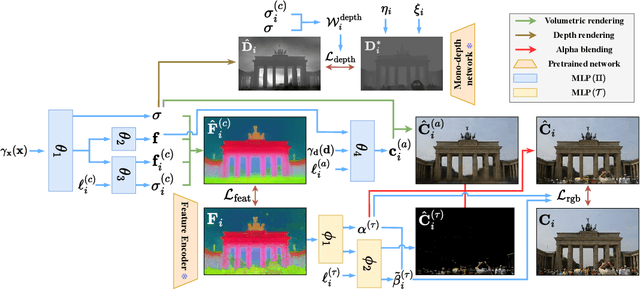
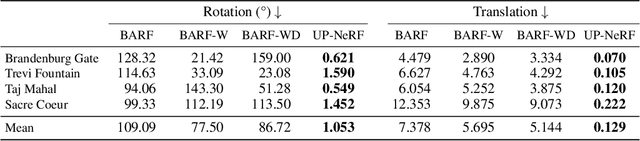
Neural Radiance Field (NeRF) has enabled novel view synthesis with high fidelity given images and camera poses. Subsequent works even succeeded in eliminating the necessity of pose priors by jointly optimizing NeRF and camera pose. However, these works are limited to relatively simple settings such as photometrically consistent and occluder-free image collections or a sequence of images from a video. So they have difficulty handling unconstrained images with varying illumination and transient occluders. In this paper, we propose $\textbf{UP-NeRF}$ ($\textbf{U}$nconstrained $\textbf{P}$ose-prior-free $\textbf{Ne}$ural $\textbf{R}$adiance $\textbf{F}$ields) to optimize NeRF with unconstrained image collections without camera pose prior. We tackle these challenges with surrogate tasks that optimize color-insensitive feature fields and a separate module for transient occluders to block their influence on pose estimation. In addition, we introduce a candidate head to enable more robust pose estimation and transient-aware depth supervision to minimize the effect of incorrect prior. Our experiments verify the superior performance of our method compared to the baselines including BARF and its variants in a challenging internet photo collection, $\textit{Phototourism}$ dataset.
Concept Bottleneck with Visual Concept Filtering for Explainable Medical Image Classification
Aug 23, 2023



Interpretability is a crucial factor in building reliable models for various medical applications. Concept Bottleneck Models (CBMs) enable interpretable image classification by utilizing human-understandable concepts as intermediate targets. Unlike conventional methods that require extensive human labor to construct the concept set, recent works leveraging Large Language Models (LLMs) for generating concepts made automatic concept generation possible. However, those methods do not consider whether a concept is visually relevant or not, which is an important factor in computing meaningful concept scores. Therefore, we propose a visual activation score that measures whether the concept contains visual cues or not, which can be easily computed with unlabeled image data. Computed visual activation scores are then used to filter out the less visible concepts, thus resulting in a final concept set with visually meaningful concepts. Our experimental results show that adopting the proposed visual activation score for concept filtering consistently boosts performance compared to the baseline. Moreover, qualitative analyses also validate that visually relevant concepts are successfully selected with the visual activation score.
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Mar 05, 2023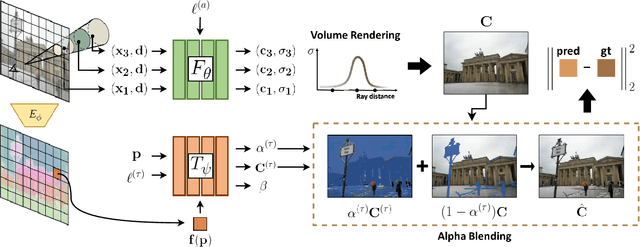
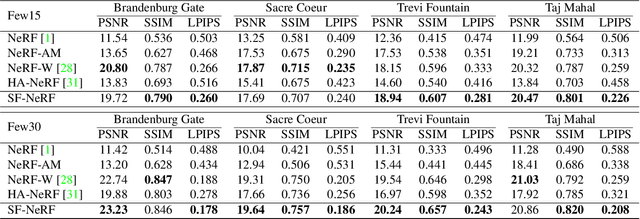

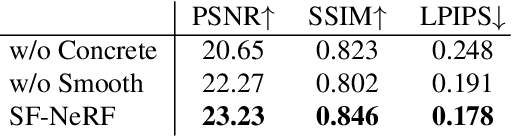
We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.
SageMix: Saliency-Guided Mixup for Point Clouds
Oct 13, 2022

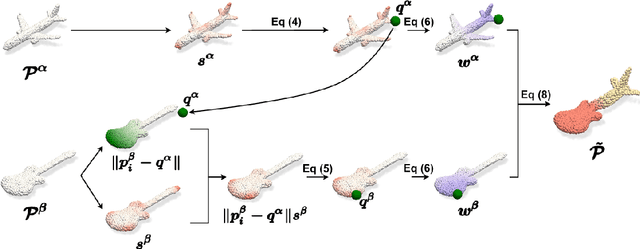
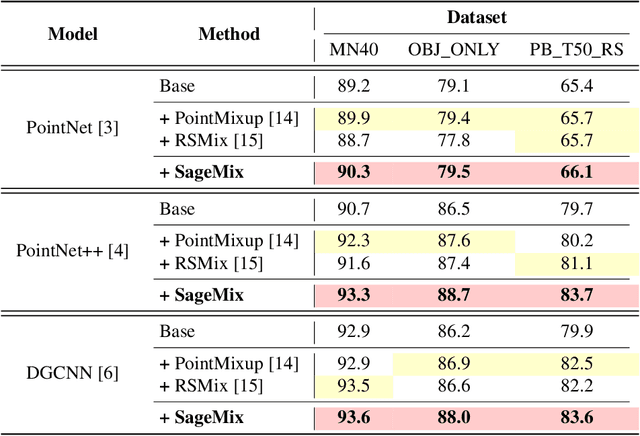
Data augmentation is key to improving the generalization ability of deep learning models. Mixup is a simple and widely-used data augmentation technique that has proven effective in alleviating the problems of overfitting and data scarcity. Also, recent studies of saliency-aware Mixup in the image domain show that preserving discriminative parts is beneficial to improving the generalization performance. However, these Mixup-based data augmentations are underexplored in 3D vision, especially in point clouds. In this paper, we propose SageMix, a saliency-guided Mixup for point clouds to preserve salient local structures. Specifically, we extract salient regions from two point clouds and smoothly combine them into one continuous shape. With a simple sequential sampling by re-weighted saliency scores, SageMix preserves the local structure of salient regions. Extensive experiments demonstrate that the proposed method consistently outperforms existing Mixup methods in various benchmark point cloud datasets. With PointNet++, our method achieves an accuracy gain of 2.6% and 4.0% over standard training in 3D Warehouse dataset (MN40) and ScanObjectNN, respectively. In addition to generalization performance, SageMix improves robustness and uncertainty calibration. Moreover, when adopting our method to various tasks including part segmentation and standard 2D image classification, our method achieves competitive performance.