 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Basics: Revisiting ASR in the Age of Voice Agents
Mar 26, 2026Automatic speech recognition (ASR) systems have achieved near-human accuracy on curated benchmarks, yet still fail in real-world voice agents under conditions that current evaluations do not systematically cover. Without diagnostic tools that isolate specific failure factors, practitioners cannot anticipate which conditions, in which languages, will cause what degree of degradation. We introduce WildASR, a multilingual (four-language) diagnostic benchmark sourced entirely from real human speech that factorizes ASR robustness along three axes: environmental degradation, demographic shift, and linguistic diversity. Evaluating seven widely used ASR systems, we find severe and uneven performance degradation, and model robustness does not transfer across languages or conditions. Critically, models often hallucinate plausible but unspoken content under partial or degraded inputs, creating concrete safety risks for downstream agent behavior. Our results demonstrate that targeted, factor-isolated evaluation is essential for understanding and improving ASR reliability in production systems. Besides the benchmark itself, we also present three analytical tools that practitioners can use to guide deployment decisions.
DALDALL: Data Augmentation for Lexical and Semantic Diverse in Legal Domain by leveraging LLM-Persona
Mar 24, 2026Data scarcity remains a persistent challenge in low-resource domains. While existing data augmentation methods leverage the generative capabilities of large language models (LLMs) to produce large volumes of synthetic data, these approaches often prioritize quantity over quality and lack domain-specific strategies. In this work, we introduce DALDALL, a persona-based data augmentation framework tailored for legal information retrieval (IR). Our method employs domain-specific professional personas--such as attorneys, prosecutors, and judges--to generate synthetic queries that exhibit substantially greater lexical and semantic diversity than vanilla prompting approaches. Experiments on the CLERC and COLIEE benchmarks demonstrate that persona-based augmentation achieves improvement in lexical diversity as measured by Self-BLEU scores, while preserving semantic fidelity to the original queries. Furthermore, dense retrievers fine-tuned on persona-augmented data consistently achieve competitive or superior recall performance compared to those trained on original data or generic augmentations. These findings establish persona-based prompting as an effective strategy for generating high-quality training data in specialized, low-resource domains.
Rethinking Pose Refinement in 3D Gaussian Splatting under Pose Prior and Geometric Uncertainty
Mar 17, 20263D Gaussian Splatting (3DGS) has recently emerged as a powerful scene representation and is increasingly used for visual localization and pose refinement. However, despite its high-quality differentiable rendering, the robustness of 3DGS-based pose refinement remains highly sensitive to both the initial camera pose and the reconstructed geometry. In this work, we take a closer look at these limitations and identify two major sources of uncertainty: (i) pose prior uncertainty, which often arises from regression or retrieval models that output a single deterministic estimate, and (ii) geometric uncertainty, caused by imperfections in the 3DGS reconstruction that propagate errors into PnP solvers. Such uncertainties can distort reprojection geometry and destabilize optimization, even when the rendered appearance still looks plausible. To address these uncertainties, we introduce a relocalization framework that combines Monte Carlo pose sampling with Fisher Information-based PnP optimization. Our method explicitly accounts for both pose and geometric uncertainty and requires no retraining or additional supervision. Across diverse indoor and outdoor benchmarks, our approach consistently improves localization accuracy and significantly increases stability under pose and depth noise.
RVN-Bench: A Benchmark for Reactive Visual Navigation
Mar 04, 2026Safe visual navigation is critical for indoor mobile robots operating in cluttered environments. Existing benchmarks, however, often neglect collisions or are designed for outdoor scenarios, making them unsuitable for indoor visual navigation. To address this limitation, we introduce the reactive visual navigation benchmark (RVN-Bench), a collision-aware benchmark for indoor mobile robots. In RVN-Bench, an agent must reach sequential goal positions in previously unseen environments using only visual observations and no prior map, while avoiding collisions. Built on the Habitat 2.0 simulator and leveraging high-fidelity HM3D scenes, RVN-Bench provides large-scale, diverse indoor environments, defines a collision-aware navigation task and evaluation metrics, and offers tools for standardized training and benchmarking. RVN-Bench supports both online and offline learning by offering an environment for online reinforcement learning, a trajectory image dataset generator, and tools for producing negative trajectory image datasets that capture collision events. Experiments show that policies trained on RVN-Bench generalize effectively to unseen environments, demonstrating its value as a standardized benchmark for safe and robust visual navigation. Code and additional materials are available at: https://rvn-bench.github.io/.
Erase at the Core: Representation Unlearning for Machine Unlearning
Feb 05, 2026Many approximate machine unlearning methods demonstrate strong logit-level forgetting -- such as near-zero accuracy on the forget set -- yet continue to preserve substantial information within their internal feature representations. We refer to this discrepancy as superficial forgetting. Recent studies indicate that most existing unlearning approaches primarily alter the final classifier, leaving intermediate representations largely unchanged and highly similar to those of the original model. To address this limitation, we introduce the Erase at the Core (EC), a framework designed to enforce forgetting throughout the entire network hierarchy. EC integrates multi-layer contrastive unlearning on the forget set with retain set preservation through deeply supervised learning. Concretely, EC attaches auxiliary modules to intermediate layers and applies both contrastive unlearning and cross-entropy losses at each supervision point, with layer-wise weighted losses. Experimental results show that EC not only achieves effective logit-level forgetting, but also substantially reduces representational similarity to the original model across intermediate layers. Furthermore, EC is model-agnostic and can be incorporated as a plug-in module into existing unlearning methods, improving representation-level forgetting while maintaining performance on the retain set.
Consistency-Preserving Concept Erasure via Unsafe-Safe Pairing and Directional Fisher-weighted Adaptation
Feb 05, 2026With the increasing versatility of text-to-image diffusion models, the ability to selectively erase undesirable concepts (e.g., harmful content) has become indispensable. However, existing concept erasure approaches primarily focus on removing unsafe concepts without providing guidance toward corresponding safe alternatives, which often leads to failure in preserving the structural and semantic consistency between the original and erased generations. In this paper, we propose a novel framework, PAIRed Erasing (PAIR), which reframes concept erasure from simple removal to consistency-preserving semantic realignment using unsafe-safe pairs. We first generate safe counterparts from unsafe inputs while preserving structural and semantic fidelity, forming paired unsafe-safe multimodal data. Leveraging these pairs, we introduce two key components: (1) Paired Semantic Realignment, a guided objective that uses unsafe-safe pairs to explicitly map target concepts to semantically aligned safe anchors; and (2) Fisher-weighted Initialization for DoRA, which initializes parameter-efficient low-rank adaptation matrices using unsafe-safe pairs, encouraging the generation of safe alternatives while selectively suppressing unsafe concepts. Together, these components enable fine-grained erasure that removes only the targeted concepts while maintaining overall semantic consistency. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, achieving effective concept erasure while preserving structural integrity, semantic coherence, and generation quality.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
Self-supervised denoising of visual field data improves detection of glaucoma progression
Nov 19, 2024Perimetric measurements provide insight into a patient's peripheral vision and day-to-day functioning and are the main outcome measure for identifying progression of visual damage from glaucoma. However, visual field data can be noisy, exhibiting high variance, especially with increasing damage. In this study, we demonstrate the utility of self-supervised deep learning in denoising visual field data from over 4000 patients to enhance its signal-to-noise ratio and its ability to detect true glaucoma progression. We deployed both a variational autoencoder (VAE) and a masked autoencoder to determine which self-supervised model best smooths the visual field data while reconstructing salient features that are less noisy and more predictive of worsening disease. Our results indicate that including a categorical p-value at every visual field location improves the smoothing of visual field data. Masked autoencoders led to cleaner denoised data than previous methods, such as variational autoencoders. A 4.7% increase in detection of progressing eyes with pointwise linear regression (PLR) was observed. The masked and variational autoencoders' smoothed data predicted glaucoma progression 2.3 months earlier when p-values were included compared to when they were not. The faster prediction of time to progression (TTP) and the higher percentage progression detected support our hypothesis that masking out visual field elements during training while including p-values at each location would improve the task of detection of visual field progression. Our study has clinically relevant implications regarding masking when training neural networks to denoise visual field data, resulting in earlier and more accurate detection of glaucoma progression. This denoising model can be integrated into future models for visual field analysis to enhance detection of glaucoma progression.
DGS-SLAM: Gaussian Splatting SLAM in Dynamic Environment
Nov 16, 2024
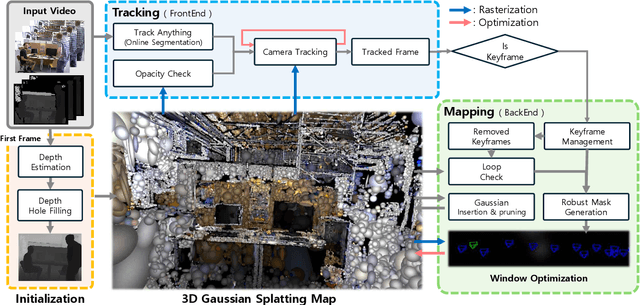


We introduce Dynamic Gaussian Splatting SLAM (DGS-SLAM), the first dynamic SLAM framework built on the foundation of Gaussian Splatting. While recent advancements in dense SLAM have leveraged Gaussian Splatting to enhance scene representation, most approaches assume a static environment, making them vulnerable to photometric and geometric inconsistencies caused by dynamic objects. To address these challenges, we integrate Gaussian Splatting SLAM with a robust filtering process to handle dynamic objects throughout the entire pipeline, including Gaussian insertion and keyframe selection. Within this framework, to further improve the accuracy of dynamic object removal, we introduce a robust mask generation method that enforces photometric consistency across keyframes, reducing noise from inaccurate segmentation and artifacts such as shadows. Additionally, we propose the loop-aware window selection mechanism, which utilizes unique keyframe IDs of 3D Gaussians to detect loops between the current and past frames, facilitating joint optimization of the current camera poses and the Gaussian map. DGS-SLAM achieves state-of-the-art performance in both camera tracking and novel view synthesis on various dynamic SLAM benchmarks, proving its effectiveness in handling real-world dynamic scenes.