 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUTRA: Scalable Multilingual Language Model Architecture
May 07, 2024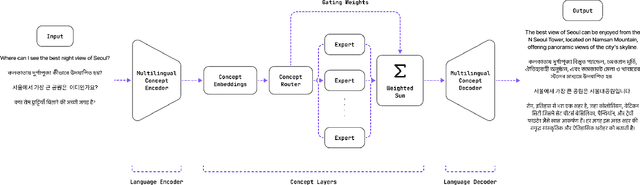

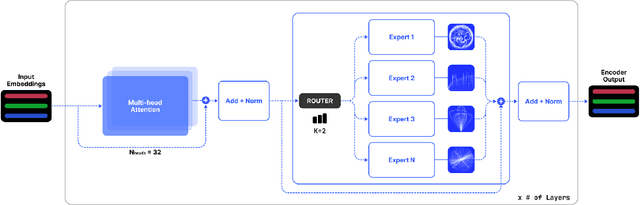

In this paper, we introduce SUTRA, multilingual Large Language Model architecture capable of understanding, reasoning, and generating text in over 50 languages. SUTRA's design uniquely decouples core conceptual understanding from language-specific processing, which facilitates scalable and efficient multilingual alignment and learning. Employing a Mixture of Experts framework both in language and concept processing, SUTRA demonstrates both computational efficiency and responsiveness. Through extensive evaluations, SUTRA is demonstrated to surpass existing models like GPT-3.5, Llama2 by 20-30% on leading Massive Multitask Language Understanding (MMLU) benchmarks for multilingual tasks. SUTRA models are also online LLMs that can use knowledge from the internet to provide hallucination-free, factual and up-to-date responses while retaining their multilingual capabilities. Furthermore, we explore the broader implications of its architecture for the future of multilingual AI, highlighting its potential to democratize access to AI technology globally and to improve the equity and utility of AI in regions with predominantly non-English languages. Our findings suggest that SUTRA not only fills pivotal gaps in multilingual model capabilities but also establishes a new benchmark for operational efficiency and scalability in AI applications.
Towards Open Set Deep Networks
Nov 19, 2015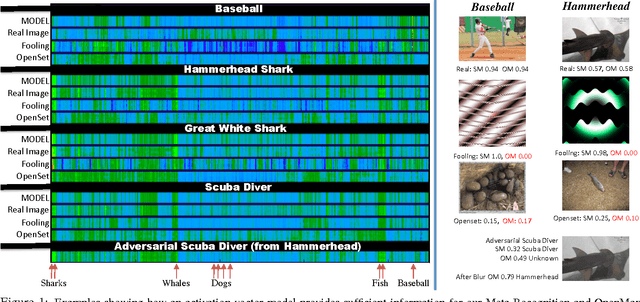
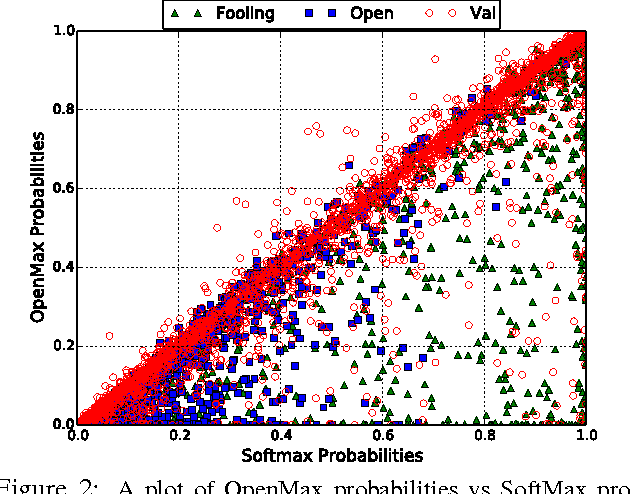
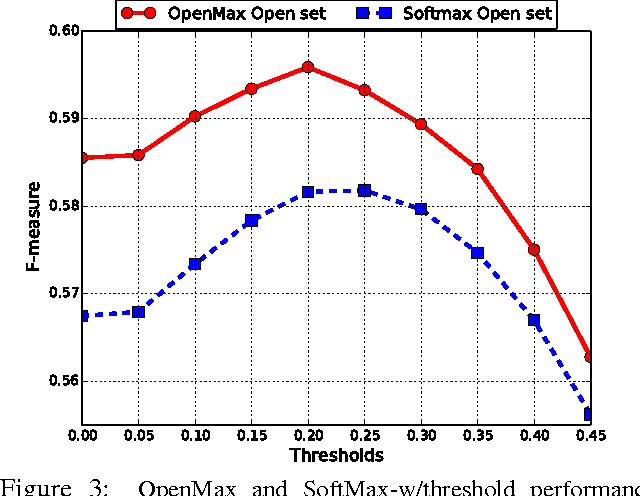
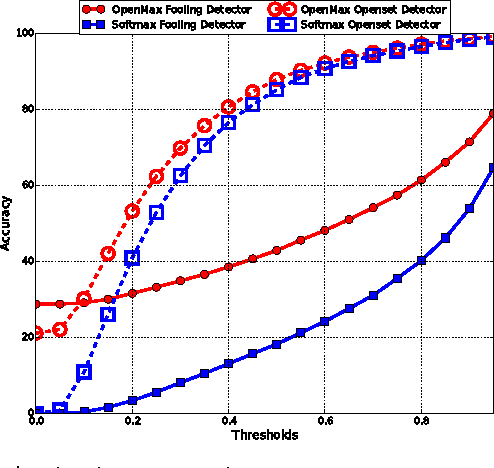
Deep networks have produced significant gains for various visual recognition problems, leading to high impact academic and commercial applications. Recent work in deep networks highlighted that it is easy to generate images that humans would never classify as a particular object class, yet networks classify such images high confidence as that given class - deep network are easily fooled with images humans do not consider meaningful. The closed set nature of deep networks forces them to choose from one of the known classes leading to such artifacts. Recognition in the real world is open set, i.e. the recognition system should reject unknown/unseen classes at test time. We present a methodology to adapt deep networks for open set recognition, by introducing a new model layer, OpenMax, which estimates the probability of an input being from an unknown class. A key element of estimating the unknown probability is adapting Meta-Recognition concepts to the activation patterns in the penultimate layer of the network. OpenMax allows rejection of "fooling" and unrelated open set images presented to the system; OpenMax greatly reduces the number of obvious errors made by a deep network. We prove that the OpenMax concept provides bounded open space risk, thereby formally providing an open set recognition solution. We evaluate the resulting open set deep networks using pre-trained networks from the Caffe Model-zoo on ImageNet 2012 validation data, and thousands of fooling and open set images. The proposed OpenMax model significantly outperforms open set recognition accuracy of basic deep networks as well as deep networks with thresholding of SoftMax probabilities.
Towards Open World Recognition
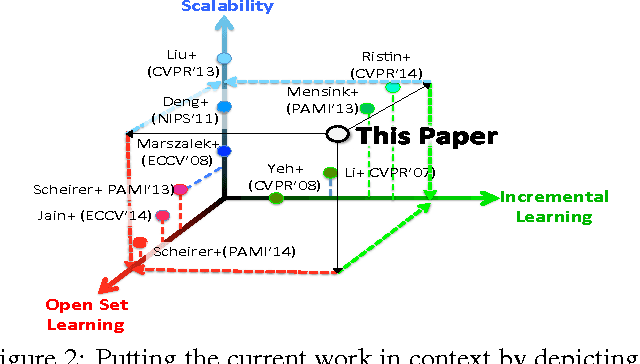
Dec 18, 2014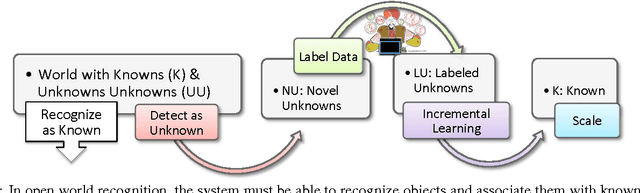
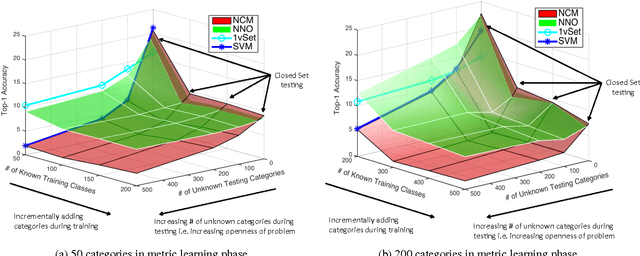
With the of advent rich classification models and high computational power visual recognition systems have found many operational applications. Recognition in the real world poses multiple challenges that are not apparent in controlled lab environments. The datasets are dynamic and novel categories must be continuously detected and then added. At prediction time, a trained system has to deal with myriad unseen categories. Operational systems require minimum down time, even to learn. To handle these operational issues, we present the problem of Open World recognition and formally define it. We prove that thresholding sums of monotonically decreasing functions of distances in linearly transformed feature space can balance "open space risk" and empirical risk. Our theory extends existing algorithms for open world recognition. We present a protocol for evaluation of open world recognition systems. We present the Nearest Non-Outlier (NNO) algorithm which evolves model efficiently, adding object categories incrementally while detecting outliers and managing open space risk. We perform experiments on the ImageNet dataset with 1.2M+ images to validate the effectiveness of our method on large scale visual recognition tasks. NNO consistently yields superior results on open world recognition.